 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARL-Tangram: Unleash the Resource Efficiency in Agentic Reinforcement Learning
Mar 13, 2026Agentic reinforcement learning (RL) has emerged as a transformative workload in cloud clusters, enabling large language models (LLMs) to solve complex problems through interactions with real world. However, unlike traditional RL, agentic RL demands substantial external cloud resources, e.g., CPUs for code execution and GPUs for reward models, that exist outside the primary training cluster. Existing agentic RL framework typically rely on static over-provisioning, i.e., resources are often tied to long-lived trajectories or isolated by tasks, which leads to severe resource inefficiency. We propose the action-level orchestration, and incorporate it into ARL-Tangram, a unified resource management system that enables fine-grained external resource sharing and elasticity. ARL-Tangram utilizes a unified action-level formulation and an elastic scheduling algorithm to minimize action completion time (ACT) while satisfying heterogeneous resource constraints. Further, heterogeneous resource managers are tailored to efficiently support the action-level execution on resources with heterogeneous characteristics and topologies. Evaluation on real-world agentic RL tasks demonstrates that ARL-Tangram improves average ACT by up to 4.3$\times$, speeds up the step duration of RL training by up to 1.5$\times$, and saves the external resources by up to 71.2$\%$. This system has been deployed to support the training of the MiMo series models.
MiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Towards Autonomous UAV Visual Object Search in City Space: Benchmark and Agentic Methodology
May 14, 2025Aerial Visual Object Search (AVOS) tasks in urban environments require Unmanned Aerial Vehicles (UAVs) to autonomously search for and identify target objects using visual and textual cues without external guidance. Existing approaches struggle in complex urban environments due to redundant semantic processing, similar object distinction, and the exploration-exploitation dilemma. To bridge this gap and support the AVOS task, we introduce CityAVOS, the first benchmark dataset for autonomous search of common urban objects. This dataset comprises 2,420 tasks across six object categories with varying difficulty levels, enabling comprehensive evaluation of UAV agents' search capabilities. To solve the AVOS tasks, we also propose PRPSearcher (Perception-Reasoning-Planning Searcher), a novel agentic method powered by multi-modal large language models (MLLMs) that mimics human three-tier cognition. Specifically, PRPSearcher constructs three specialized maps: an object-centric dynamic semantic map enhancing spatial perception, a 3D cognitive map based on semantic attraction values for target reasoning, and a 3D uncertainty map for balanced exploration-exploitation search. Also, our approach incorporates a denoising mechanism to mitigate interference from similar objects and utilizes an Inspiration Promote Thought (IPT) prompting mechanism for adaptive action planning. Experimental results on CityAVOS demonstrate that PRPSearcher surpasses existing baselines in both success rate and search efficiency (on average: +37.69% SR, +28.96% SPL, -30.69% MSS, and -46.40% NE). While promising, the performance gap compared to humans highlights the need for better semantic reasoning and spatial exploration capabilities in AVOS tasks. This work establishes a foundation for future advances in embodied target search. Dataset and source code are available at https://anonymous.4open.science/r/CityAVOS-3DF8.
TG-LMM: Enhancing Medical Image Segmentation Accuracy through Text-Guided Large Multi-Modal Model
Sep 05, 2024



We propose TG-LMM (Text-Guided Large Multi-Modal Model), a novel approach that leverages textual descriptions of organs to enhance segmentation accuracy in medical images. Existing medical image segmentation methods face several challenges: current medical automatic segmentation models do not effectively utilize prior knowledge, such as descriptions of organ locations; previous text-visual models focus on identifying the target rather than improving the segmentation accuracy; prior models attempt to use prior knowledge to enhance accuracy but do not incorporate pre-trained models. To address these issues, TG-LMM integrates prior knowledge, specifically expert descriptions of the spatial locations of organs, into the segmentation process. Our model utilizes pre-trained image and text encoders to reduce the number of training parameters and accelerate the training process. Additionally, we designed a comprehensive image-text information fusion structure to ensure thorough integration of the two modalities of data. We evaluated TG-LMM on three authoritative medical image datasets, encompassing the segmentation of various parts of the human body. Our method demonstrated superior performance compared to existing approaches, such as MedSAM, SAM and nnUnet.
Quality assurance of organs-at-risk delineation in radiotherapy
May 20, 2024



The delineation of tumor target and organs-at-risk is critical in the radiotherapy treatment planning. Automatic segmentation can be used to reduce the physician workload and improve the consistency. However, the quality assurance of the automatic segmentation is still an unmet need in clinical practice. The patient data used in our study was a standardized dataset from AAPM Thoracic Auto-Segmentation Challenge. The OARs included were left and right lungs, heart, esophagus, and spinal cord. Two groups of OARs were generated, the benchmark dataset manually contoured by experienced physicians and the test dataset automatically created using a software AccuContour. A resnet-152 network was performed as feature extractor, and one-class support vector classifier was used to determine the high or low quality. We evaluate the model performance with balanced accuracy, F-score, sensitivity, specificity and the area under the receiving operator characteristic curve. We randomly generated contour errors to assess the generalization of our method, explored the detection limit, and evaluated the correlations between detection limit and various metrics such as volume, Dice similarity coefficient, Hausdorff distance, and mean surface distance. The proposed one-class classifier outperformed in metrics such as balanced accuracy, AUC, and others. The proposed method showed significant improvement over binary classifiers in handling various types of errors. Our proposed model, which introduces residual network and attention mechanism in the one-class classification framework, was able to detect the various types of OAR contour errors with high accuracy. The proposed method can significantly reduce the burden of physician review for contour delineation.
A Survey of Resource-efficient LLM and Multimodal Foundation Models
Jan 16, 2024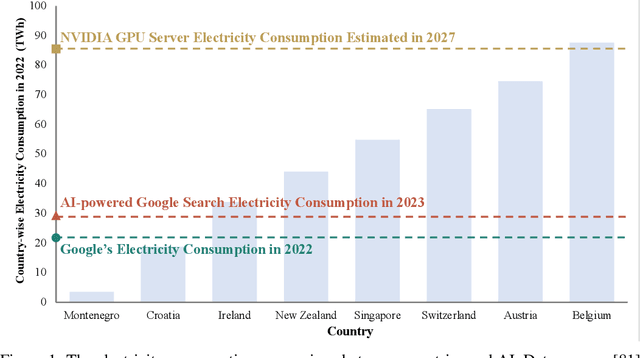
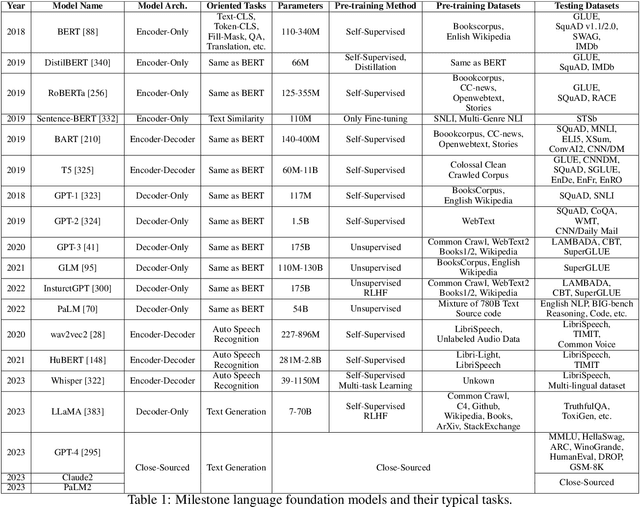
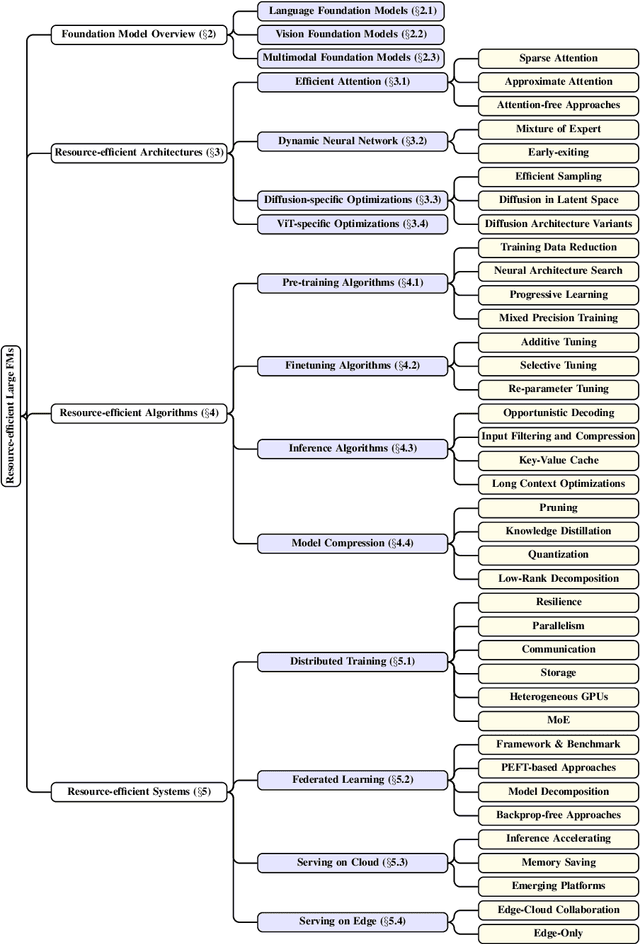
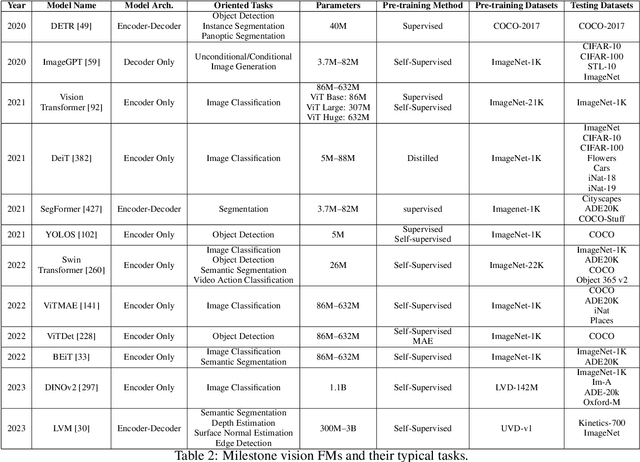
Large foundation models, including large language models (LLMs), vision transformers (ViTs), diffusion, and LLM-based multimodal models, are revolutionizing the entire machine learning lifecycle, from training to deployment. However, the substantial advancements in versatility and performance these models offer come at a significant cost in terms of hardware resources. To support the growth of these large models in a scalable and environmentally sustainable way, there has been a considerable focus on developing resource-efficient strategies. This survey delves into the critical importance of such research, examining both algorithmic and systemic aspects. It offers a comprehensive analysis and valuable insights gleaned from existing literature, encompassing a broad array of topics from cutting-edge model architectures and training/serving algorithms to practical system designs and implementations. The goal of this survey is to provide an overarching understanding of how current approaches are tackling the resource challenges posed by large foundation models and to potentially inspire future breakthroughs in this field.
Unpaired Image-to-Image Translation using Adversarial Consistency Loss
Mar 10, 2020

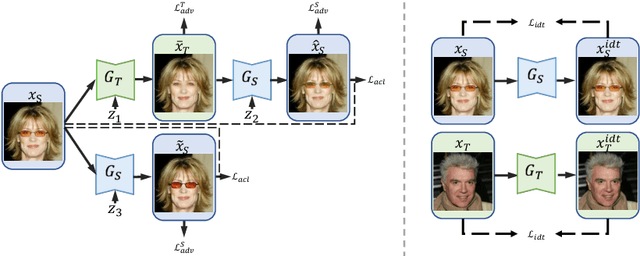
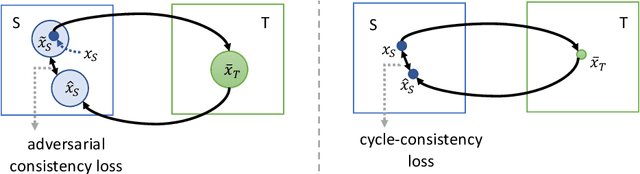
Unpaired image-to-image translation is a class of vision problems whose goal is to find the mapping between different image domains using unpaired training data. Cycle-consistency loss is a widely used constraint for such problems. However, due to the strict pixel-level constraint, it cannot perform geometric changes, remove large objects, or ignore irrelevant texture. In this paper, we propose a novel adversarial-consistency loss for image-to-image translation. This loss does not require the translated image to be translated back to be a specific source image but can encourage the translated images to retain important features of the source images and overcome the drawbacks of cycle-consistency loss noted above. Our method achieves state-of-the-art results on three challenging tasks: glasses removal, male-to-female translation, and selfie-to-anime translation.
DLGAN: Disentangling Label-Specific Fine-Grained Features for Image Manipulation
Nov 22, 2019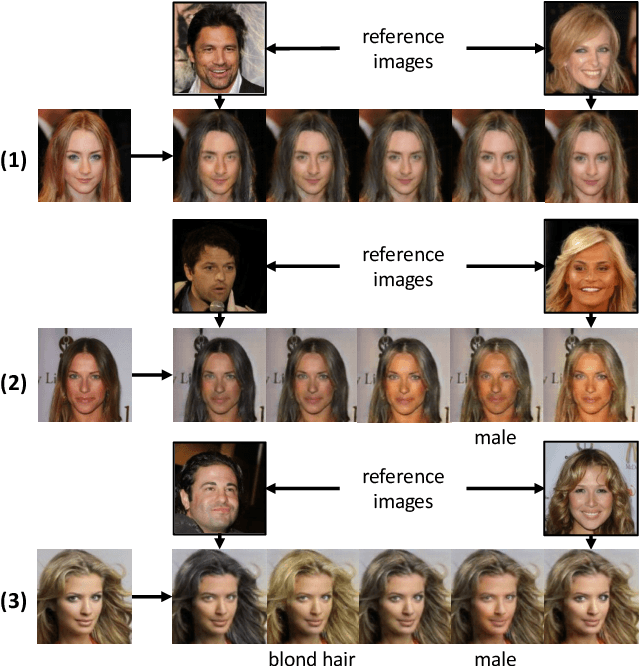
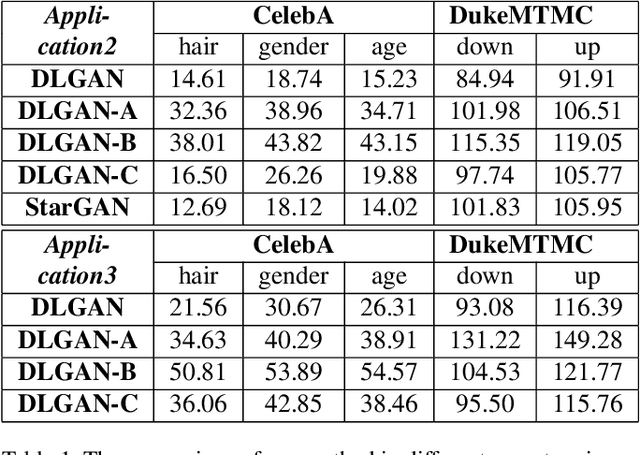
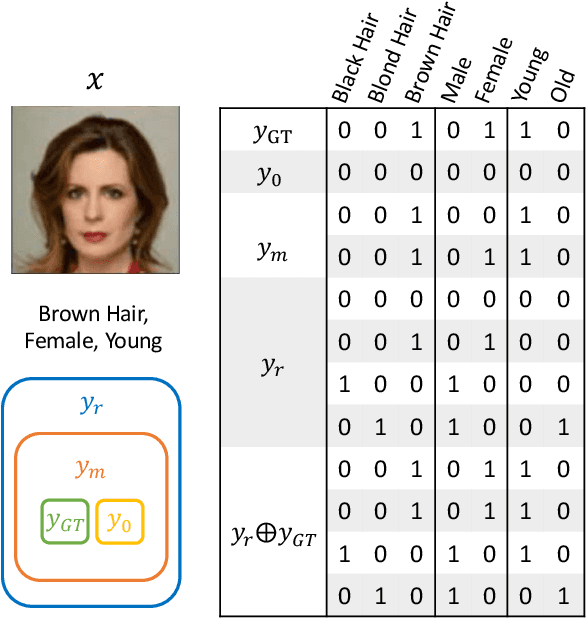
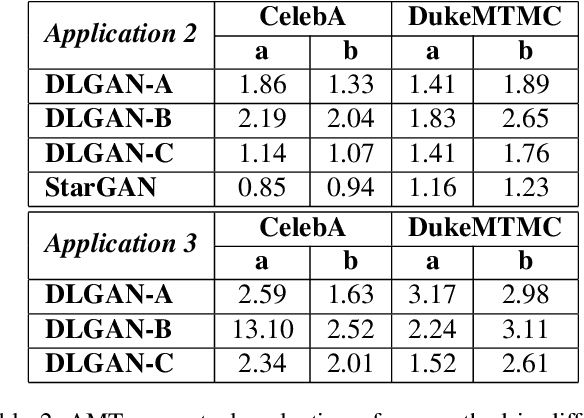
Several recent studies have shown how disentangling images into content and feature spaces can provide controllable image translation/manipulation. In this paper, we propose a framework to enable utilizing discrete multi-labels to control which features to be disentangled,i.e., disentangling label-specific fine-grained features for image manipulation (dubbed DLGAN). By mapping the discrete label-specific attribute features into a continuous prior distribution, we enable leveraging the advantages of both discrete labels and reference images to achieve image manipulation in a hybrid fashion. For example, given a face image dataset (e.g., CelebA) with multiple discrete fine-grained labels, we can learn to smoothly interpolate a face image between black hair and blond hair through reference images while immediately control the gender and age through discrete input labels. To the best of our knowledge, this is the first work to realize such a hybrid manipulation within a single model. Qualitative and quantitative experiments demonstrate the effectiveness of the proposed method