 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBatch-of-Thought: Cross-Instance Learning for Enhanced LLM Reasoning
Jan 06, 2026Current Large Language Model reasoning systems process queries independently, discarding valuable cross-instance signals such as shared reasoning patterns and consistency constraints. We introduce Batch-of-Thought (BoT), a training-free method that processes related queries jointly to enable cross-instance learning. By performing comparative analysis across batches, BoT identifies high-quality reasoning templates, detects errors through consistency checks, and amortizes computational costs. We instantiate BoT within a multi-agent reflection architecture (BoT-R), where a Reflector performs joint evaluation to unlock mutual information gain unavailable in isolated processing. Experiments across three model families and six benchmarks demonstrate that BoT-R consistently improves accuracy and confidence calibration while reducing inference costs by up to 61%. Our theoretical and experimental analysis reveals when and why batch-aware reasoning benefits LLM systems.
DynamicCity: Large-Scale LiDAR Generation from Dynamic Scenes
Oct 23, 2024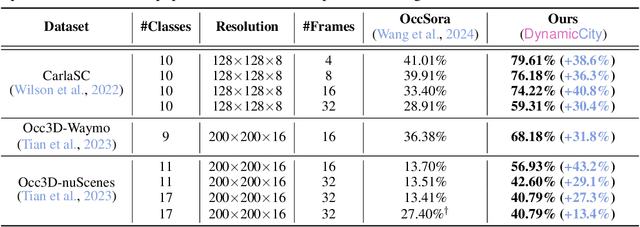
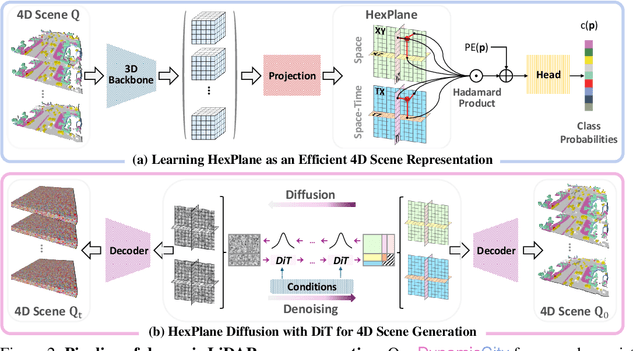

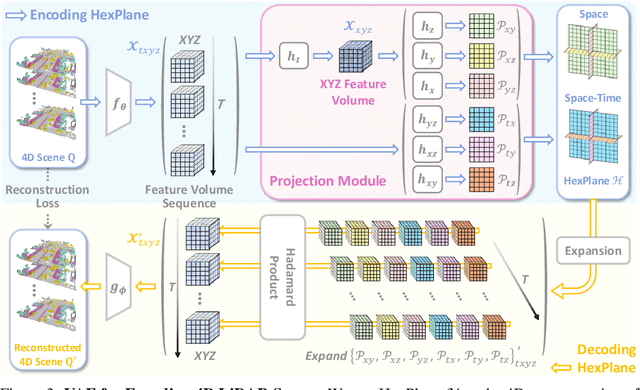
LiDAR scene generation has been developing rapidly recently. However, existing methods primarily focus on generating static and single-frame scenes, overlooking the inherently dynamic nature of real-world driving environments. In this work, we introduce DynamicCity, a novel 4D LiDAR generation framework capable of generating large-scale, high-quality LiDAR scenes that capture the temporal evolution of dynamic environments. DynamicCity mainly consists of two key models. 1) A VAE model for learning HexPlane as the compact 4D representation. Instead of using naive averaging operations, DynamicCity employs a novel Projection Module to effectively compress 4D LiDAR features into six 2D feature maps for HexPlane construction, which significantly enhances HexPlane fitting quality (up to 12.56 mIoU gain). Furthermore, we utilize an Expansion & Squeeze Strategy to reconstruct 3D feature volumes in parallel, which improves both network training efficiency and reconstruction accuracy than naively querying each 3D point (up to 7.05 mIoU gain, 2.06x training speedup, and 70.84% memory reduction). 2) A DiT-based diffusion model for HexPlane generation. To make HexPlane feasible for DiT generation, a Padded Rollout Operation is proposed to reorganize all six feature planes of the HexPlane as a squared 2D feature map. In particular, various conditions could be introduced in the diffusion or sampling process, supporting versatile 4D generation applications, such as trajectory- and command-driven generation, inpainting, and layout-conditioned generation. Extensive experiments on the CarlaSC and Waymo datasets demonstrate that DynamicCity significantly outperforms existing state-of-the-art 4D LiDAR generation methods across multiple metrics. The code will be released to facilitate future research.
SynesLM: A Unified Approach for Audio-visual Speech Recognition and Translation via Language Model and Synthetic Data
Aug 01, 2024In this work, we present SynesLM, an unified model which can perform three multimodal language understanding tasks: audio-visual automatic speech recognition(AV-ASR) and visual-aided speech/machine translation(VST/VMT). Unlike previous research that focused on lip motion as visual cues for speech signals, our work explores more general visual information within entire frames, such as objects and actions. Additionally, we use synthetic image data to enhance the correlation between image and speech data. We benchmark SynesLM against the How2 dataset, demonstrating performance on par with state-of-the-art (SOTA) models dedicated to AV-ASR while maintaining our multitasking framework. Remarkably, for zero-shot AV-ASR, SynesLM achieved SOTA performance by lowering the Word Error Rate (WER) from 43.4% to 39.4% on the VisSpeech Dataset. Furthermore, our results in VST and VMT outperform the previous results, improving the BLEU score to 43.5 from 37.2 for VST, and to 54.8 from 54.4 for VMT.
Training-free CryoET Tomogram Segmentation
Jul 08, 2024



Cryogenic Electron Tomography (CryoET) is a useful imaging technology in structural biology that is hindered by its need for manual annotations, especially in particle picking. Recent works have endeavored to remedy this issue with few-shot learning or contrastive learning techniques. However, supervised training is still inevitable for them. We instead choose to leverage the power of existing 2D foundation models and present a novel, training-free framework, CryoSAM. In addition to prompt-based single-particle instance segmentation, our approach can automatically search for similar features, facilitating full tomogram semantic segmentation with only one prompt. CryoSAM is composed of two major parts: 1) a prompt-based 3D segmentation system that uses prompts to complete single-particle instance segmentation recursively with Cross-Plane Self-Prompting, and 2) a Hierarchical Feature Matching mechanism that efficiently matches relevant features with extracted tomogram features. They collaborate to enable the segmentation of all particles of one category with just one particle-specific prompt. Our experiments show that CryoSAM outperforms existing works by a significant margin and requires even fewer annotations in particle picking. Further visualizations demonstrate its ability when dealing with full tomogram segmentation for various subcellular structures. Our code is available at: https://github.com/xulabs/aitom
Bridging the Gap: A Unified Video Comprehension Framework for Moment Retrieval and Highlight Detection
Nov 28, 2023Video Moment Retrieval (MR) and Highlight Detection (HD) have attracted significant attention due to the growing demand for video analysis. Recent approaches treat MR and HD as similar video grounding problems and address them together with transformer-based architecture. However, we observe that the emphasis of MR and HD differs, with one necessitating the perception of local relationships and the other prioritizing the understanding of global contexts. Consequently, the lack of task-specific design will inevitably lead to limitations in associating the intrinsic specialty of two tasks. To tackle the issue, we propose a Unified Video COMprehension framework (UVCOM) to bridge the gap and jointly solve MR and HD effectively. By performing progressive integration on intra and inter-modality across multi-granularity, UVCOM achieves the comprehensive understanding in processing a video. Moreover, we present multi-aspect contrastive learning to consolidate the local relation modeling and global knowledge accumulation via well aligned multi-modal space. Extensive experiments on QVHighlights, Charades-STA, TACoS , YouTube Highlights and TVSum datasets demonstrate the effectiveness and rationality of UVCOM which outperforms the state-of-the-art methods by a remarkable margin.