 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastAdaSP: Multitask-Adapted Efficient Inference for Large Speech Language Model
Oct 03, 2024

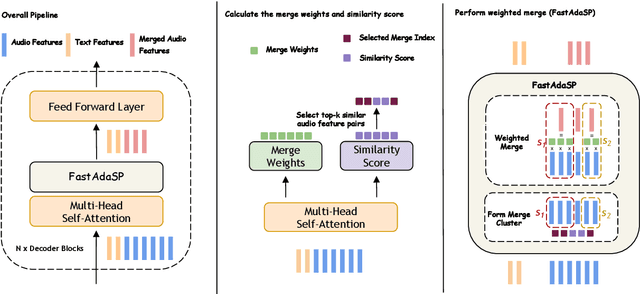
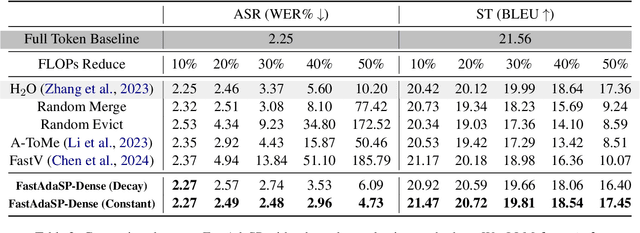
In this study, we aim to explore Multitask Speech Language Model (SpeechLM) efficient inference via token reduction. Unlike other modalities such as vision or text, speech has unique temporal dependencies, making previous efficient inference works on other modalities not directly applicable. Furthermore, methods for efficient SpeechLM inference on long sequence and sparse signals remain largely unexplored. Then we propose FastAdaSP, a weighted token merging framework specifically designed for various speech-related tasks to improve the trade-off between efficiency and performance. Experimental results on WavLLM and Qwen-Audio show that our method achieves the state-of-the-art (SOTA) efficiency-performance trade-off compared with other baseline methods. Specifically, FastAdaSP achieved 7x memory efficiency and 1.83x decoding throughput without any degradation on tasks like Emotion Recognition (ER) and Spoken Question Answering (SQA). The code will be available at https://github.com/yichen14/FastAdaSP
SynesLM: A Unified Approach for Audio-visual Speech Recognition and Translation via Language Model and Synthetic Data
Aug 01, 2024In this work, we present SynesLM, an unified model which can perform three multimodal language understanding tasks: audio-visual automatic speech recognition(AV-ASR) and visual-aided speech/machine translation(VST/VMT). Unlike previous research that focused on lip motion as visual cues for speech signals, our work explores more general visual information within entire frames, such as objects and actions. Additionally, we use synthetic image data to enhance the correlation between image and speech data. We benchmark SynesLM against the How2 dataset, demonstrating performance on par with state-of-the-art (SOTA) models dedicated to AV-ASR while maintaining our multitasking framework. Remarkably, for zero-shot AV-ASR, SynesLM achieved SOTA performance by lowering the Word Error Rate (WER) from 43.4% to 39.4% on the VisSpeech Dataset. Furthermore, our results in VST and VMT outperform the previous results, improving the BLEU score to 43.5 from 37.2 for VST, and to 54.8 from 54.4 for VMT.
Temporal compressive edge imaging enabled by a lensless diffuser camera
Sep 13, 2023Lensless imagers based on diffusers or encoding masks enable high-dimensional imaging from a single shot measurement and have been applied in various applications. However, to further extract image information such as edge detection, conventional post-processing filtering operations are needed after the reconstruction of the original object images in the diffuser imaging systems. Here, we present the concept of a temporal compressive edge detection method based on a lensless diffuser camera, which can directly recover a time sequence of edge images of a moving object from a single-shot measurement, without further post-processing steps. Our approach provides higher image quality during edge detection, compared with the conventional post-processing method. We demonstrate the effectiveness of this approach by both numerical simulation and experiments. The proof-of-concept approach can be further developed with other image post-process operations or versatile computer vision assignments toward task-oriented intelligent lensless imaging systems.
Dual-mode adaptive-SVD ghost imaging
Feb 14, 2023



In this paper, we present a dual-mode adaptive singular value decomposition ghost imaging (A-SVD GI), which can be easily switched between the modes of imaging and edge detection. It can adaptively localize the foreground pixels via a threshold selection method. Then only the foreground region is illuminated by the singular value decomposition (SVD) - based patterns, consequently retrieving high-quality images with fewer sampling ratios. By changing the selecting range of foreground pixels, the A-SVD GI can be switched to the mode of edge detection to directly reveal the edge of objects, without needing the original image. We investigate the performance of these two modes through both numerical simulations and experiments. We also develop a single-round scheme to halve measurement numbers in experiments, instead of separately illuminating positive and negative patterns in traditional methods. The binarized SVD patterns, generated by the spatial dithering method, are modulated by a digital micromirror device (DMD) to speed up the data acquisition. This dual-mode A-SVD GI can be applied in various applications, such as remote sensing or target recognition, and could be further extended for multi-modality functional imaging/detection.