 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastAdaSP: Multitask-Adapted Efficient Inference for Large Speech Language Model
Paper and Code


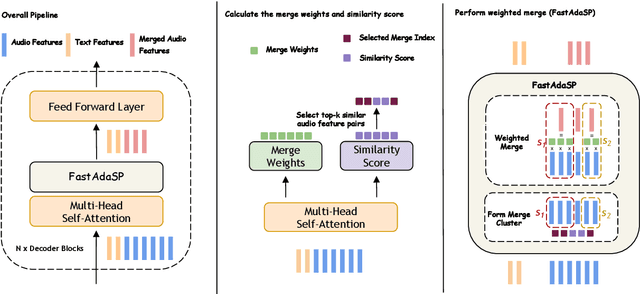
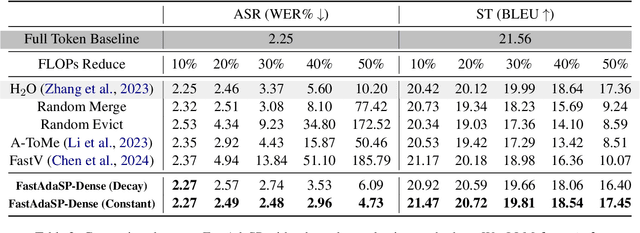
In this study, we aim to explore Multitask Speech Language Model (SpeechLM) efficient inference via token reduction. Unlike other modalities such as vision or text, speech has unique temporal dependencies, making previous efficient inference works on other modalities not directly applicable. Furthermore, methods for efficient SpeechLM inference on long sequence and sparse signals remain largely unexplored. Then we propose FastAdaSP, a weighted token merging framework specifically designed for various speech-related tasks to improve the trade-off between efficiency and performance. Experimental results on WavLLM and Qwen-Audio show that our method achieves the state-of-the-art (SOTA) efficiency-performance trade-off compared with other baseline methods. Specifically, FastAdaSP achieved 7x memory efficiency and 1.83x decoding throughput without any degradation on tasks like Emotion Recognition (ER) and Spoken Question Answering (SQA). The code will be available at https://github.com/yichen14/FastAdaSP