 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLOrtho -- A Unified Framework for Teeth Enumeration and Dental Disease Detection
Aug 11, 2023


Detecting dental diseases through panoramic X-rays images is a standard procedure for dentists. Normally, a dentist need to identify diseases and find the infected teeth. While numerous machine learning models adopting this two-step procedure have been developed, there has not been an end-to-end model that can identify teeth and their associated diseases at the same time. To fill the gap, we develop YOLOrtho, a unified framework for teeth enumeration and dental disease detection. We develop our model on Dentex Challenge 2023 data, which consists of three distinct types of annotated data. The first part is labeled with quadrant, and the second part is labeled with quadrant and enumeration and the third part is labeled with quadrant, enumeration and disease. To further improve detection, we make use of Tufts Dental public dataset. To fully utilize the data and learn both teeth detection and disease identification simultaneously, we formulate diseases as attributes attached to their corresponding teeth. Due to the nature of position relation in teeth enumeration, We replace convolution layer with CoordConv in our model to provide more position information for the model. We also adjust the model architecture and insert one more upsampling layer in FPN in favor of large object detection. Finally, we propose a post-process strategy for teeth layout that corrects teeth enumeration based on linear sum assignment. Results from experiments show that our model exceeds large Diffusion-based model.
ROBIN : A Benchmark for Robustness to Individual Nuisances in Real-World Out-of-Distribution Shifts
Dec 02, 2021
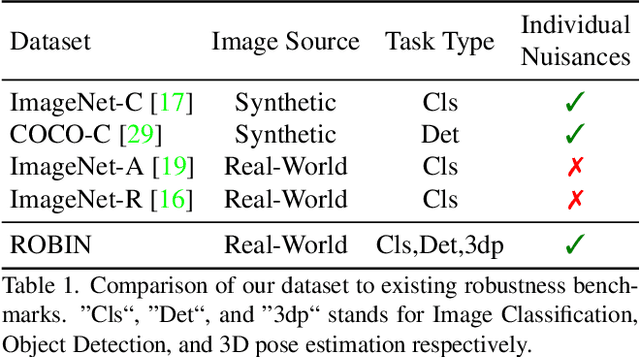

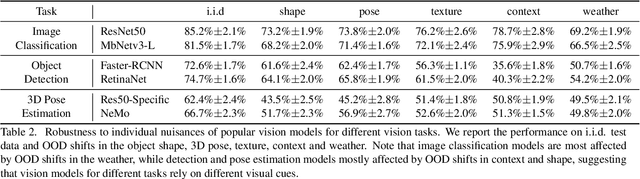
Enhancing the robustness in real-world scenarios has been proven very challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or they simply measure robustness as generalization between datasets and hence ignore the effects of individual nuisance factors. In this work, we introduce ROBIN, a benchmark dataset for diagnosing the robustness of vision algorithms to individual nuisances in real-world images. ROBIN builds on 10 rigid categories from the PASCAL VOC 2012 and ImageNet datasets and includes out-of-distribution examples of the objects 3D pose, shape, texture, context and weather conditions. ROBIN is richly annotated to enable benchmark models for image classification, object detection, and 3D pose estimation. We provide results for a number of popular baselines and make several interesting observations: 1. Some nuisance factors have a much stronger negative effect on the performance compared to others. Moreover, the negative effect of an OODnuisance depends on the downstream vision task. 2. Current approaches to enhance OOD robustness using strong data augmentation have only marginal effects in real-world OOD scenarios, and sometimes even reduce the OOD performance. 3. We do not observe any significant differences between convolutional and transformer architectures in terms of OOD robustness. We believe our dataset provides a rich testbed to study the OOD robustness of vision algorithms and will help to significantly push forward research in this area.
Neural View Synthesis and Matching for Semi-Supervised Few-Shot Learning of 3D Pose
Oct 27, 2021
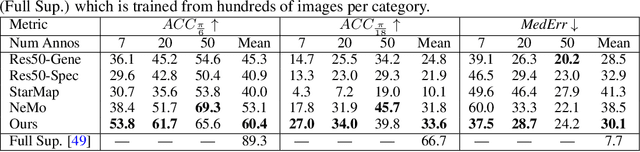

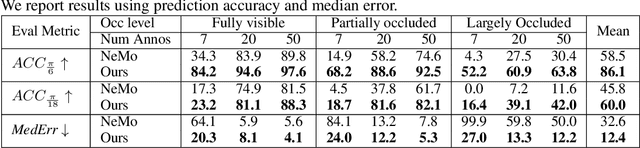
We study the problem of learning to estimate the 3D object pose from a few labelled examples and a collection of unlabelled data. Our main contribution is a learning framework, neural view synthesis and matching, that can transfer the 3D pose annotation from the labelled to unlabelled images reliably, despite unseen 3D views and nuisance variations such as the object shape, texture, illumination or scene context. In our approach, objects are represented as 3D cuboid meshes composed of feature vectors at each mesh vertex. The model is initialized from a few labelled images and is subsequently used to synthesize feature representations of unseen 3D views. The synthesized views are matched with the feature representations of unlabelled images to generate pseudo-labels of the 3D pose. The pseudo-labelled data is, in turn, used to train the feature extractor such that the features at each mesh vertex are more invariant across varying 3D views of the object. Our model is trained in an EM-type manner alternating between increasing the 3D pose invariance of the feature extractor and annotating unlabelled data through neural view synthesis and matching. We demonstrate the effectiveness of the proposed semi-supervised learning framework for 3D pose estimation on the PASCAL3D+ and KITTI datasets. We find that our approach outperforms all baselines by a wide margin, particularly in an extreme few-shot setting where only 7 annotated images are given. Remarkably, we observe that our model also achieves an exceptional robustness in out-of-distribution scenarios that involve partial occlusion.