 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigid Body Path Planning using Mixed-Integer Linear Programming
Sep 17, 2024Navigating rigid body objects through crowded environments can be challenging, especially when narrow passages are presented. Existing sampling-based planners and optimization-based methods like mixed integer linear programming (MILP) formulations, suffer from limited scalability with respect to either the size of the workspace or the number of obstacles. In order to address the scalability issue, we propose a three-stage algorithm that first generates a graph of convex polytopes in the workspace free of collision, then poses a large set of small MILPs to generate viable paths between polytopes, and finally queries a pair of start and end configurations for a feasible path online. The graph of convex polytopes serves as a decomposition of the free workspace and the number of decision variables in each MILP is limited by restricting the subproblem within two or three free polytopes rather than the entire free region. Our simulation results demonstrate shorter online computation time compared to baseline methods and scales better with the size of the environment and tunnel width than sampling-based planners in both 2D and 3D environments.
Efficient Motion Planning for Manipulators with Control Barrier Function-Induced Neural Controller
Apr 01, 2024

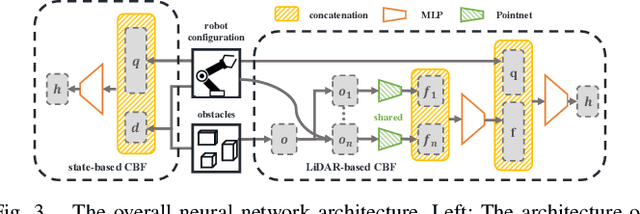
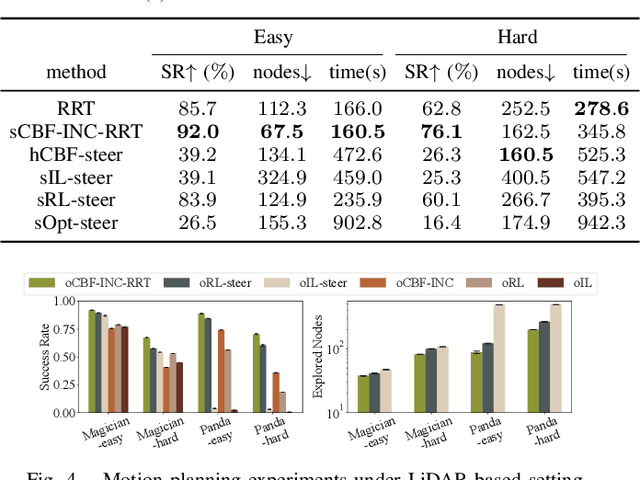
Sampling-based motion planning methods for manipulators in crowded environments often suffer from expensive collision checking and high sampling complexity, which make them difficult to use in real time. To address this issue, we propose a new generalizable control barrier function (CBF)-based steering controller to reduce the number of samples needed in a sampling-based motion planner RRT. Our method combines the strength of CBF for real-time collision-avoidance control and RRT for long-horizon motion planning, by using CBF-induced neural controller (CBF-INC) to generate control signals that steer the system towards sampled configurations by RRT. CBF-INC is learned as Neural Networks and has two variants handling different inputs, respectively: state (signed distance) input and point-cloud input from LiDAR. In the latter case, we also study two different settings: fully and partially observed environmental information. Compared to manually crafted CBF which suffers from over-approximating robot geometry, CBF-INC can balance safety and goal-reaching better without being over-conservative. Given state-based input, our neural CBF-induced neural controller-enhanced RRT (CBF-INC-RRT) can increase the success rate by 14% while reducing the number of nodes explored by 30%, compared with vanilla RRT on hard test cases. Given LiDAR input where vanilla RRT is not directly applicable, we demonstrate that our CBF-INC-RRT can improve the success rate by 10%, compared with planning with other steering controllers. Our project page with supplementary material is at https://mit-realm.github.io/CBF-INC-RRT-website/.
RoboAssembly: Learning Generalizable Furniture Assembly Policy in a Novel Multi-robot Contact-rich Simulation Environment
Dec 19, 2021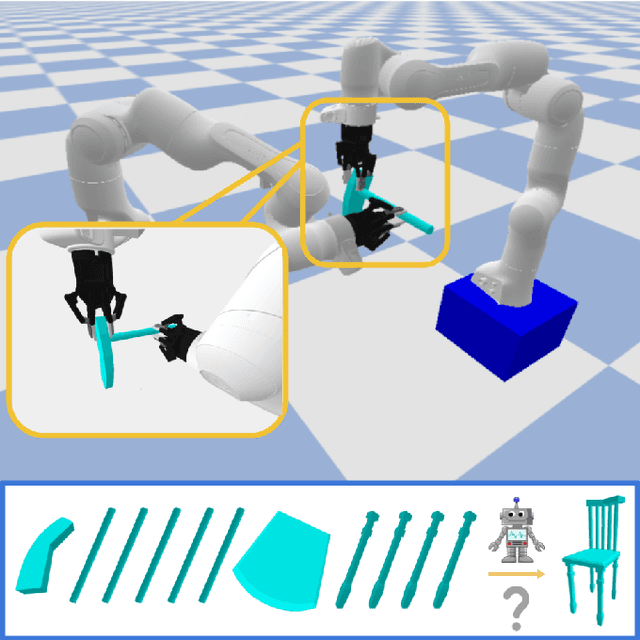
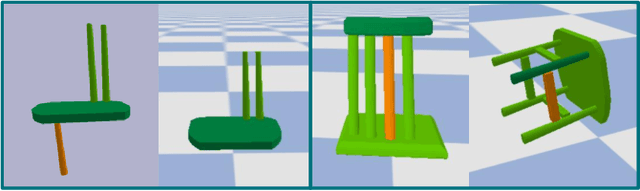
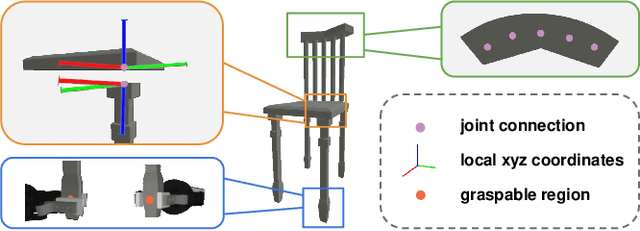
Part assembly is a typical but challenging task in robotics, where robots assemble a set of individual parts into a complete shape. In this paper, we develop a robotic assembly simulation environment for furniture assembly. We formulate the part assembly task as a concrete reinforcement learning problem and propose a pipeline for robots to learn to assemble a diverse set of chairs. Experiments show that when testing with unseen chairs, our approach achieves a success rate of 74.5% under the object-centric setting and 50.0% under the full setting. We adopt an RRT-Connect algorithm as the baseline, which only achieves a success rate of 18.8% after a significantly longer computation time. Supplemental materials and videos are available on our project webpage.
ROBIN : A Benchmark for Robustness to Individual Nuisances in Real-World Out-of-Distribution Shifts
Dec 02, 2021
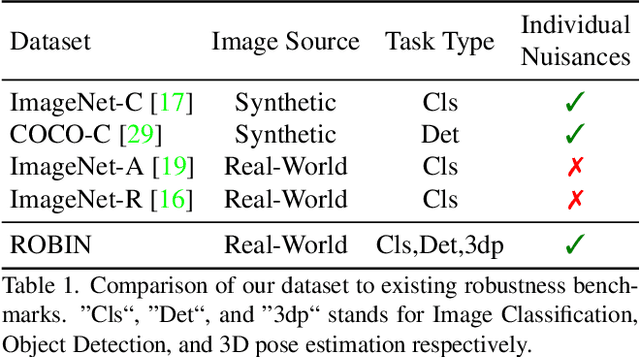

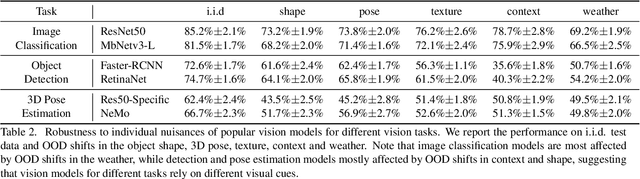
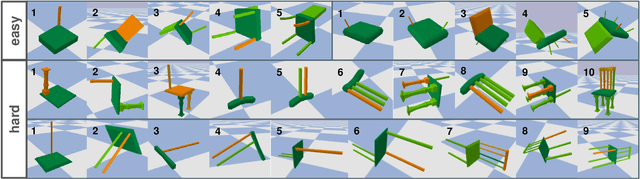
Enhancing the robustness in real-world scenarios has been proven very challenging. One reason is that existing robustness benchmarks are limited, as they either rely on synthetic data or they simply measure robustness as generalization between datasets and hence ignore the effects of individual nuisance factors. In this work, we introduce ROBIN, a benchmark dataset for diagnosing the robustness of vision algorithms to individual nuisances in real-world images. ROBIN builds on 10 rigid categories from the PASCAL VOC 2012 and ImageNet datasets and includes out-of-distribution examples of the objects 3D pose, shape, texture, context and weather conditions. ROBIN is richly annotated to enable benchmark models for image classification, object detection, and 3D pose estimation. We provide results for a number of popular baselines and make several interesting observations: 1. Some nuisance factors have a much stronger negative effect on the performance compared to others. Moreover, the negative effect of an OODnuisance depends on the downstream vision task. 2. Current approaches to enhance OOD robustness using strong data augmentation have only marginal effects in real-world OOD scenarios, and sometimes even reduce the OOD performance. 3. We do not observe any significant differences between convolutional and transformer architectures in terms of OOD robustness. We believe our dataset provides a rich testbed to study the OOD robustness of vision algorithms and will help to significantly push forward research in this area.