 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
SDesc3D: Towards Layout-Aware 3D Indoor Scene Generation from Short Descriptions
Apr 02, 20263D indoor scene generation conditioned on short textual descriptions provides a promising avenue for interactive 3D environment construction without the need for labor-intensive layout specification. Despite recent progress in text-conditioned 3D scene generation, existing works suffer from poor physical plausibility and insufficient detail richness in such semantic condensation cases, largely due to their reliance on explicit semantic cues about compositional objects and their spatial relationships. This limitation highlights the need for enhanced 3D reasoning capabilities, particularly in terms of prior integration and spatial anchoring.Motivated by this, we propose SDesc3D, a short-text conditioned 3D indoor scene generation framework, that leverages multi-view structural priors and regional functionality implications to enable 3D layout reasoning under sparse textual guidance.Specifically, we introduce a Multi-view scene prior augmentation that enriches underspecified textual inputs with aggregated multi-view structural knowledge, shifting from inaccessible semantic relation cues to multi-view relational prior aggregation. Building on this, we design a Functionality-aware layout grounding, employing regional functionality grounding for implicit spatial anchors and conducting hierarchical layout reasoning to enhance scene organization and semantic plausibility.Furthermore, an Iterative reflection-rectification scheme is employed for progressive structural plausibility refinement via self-rectification.Extensive experiments show that our method outperforms existing approaches on short-text conditioned 3D indoor scene generation.Code will be publicly available.
DynaGen: Unifying Temporal Knowledge Graph Reasoning with Dynamic Subgraphs and Generative Regularization
Dec 14, 2025Temporal Knowledge Graph Reasoning (TKGR) aims to complete missing factual elements along the timeline. Depending on the temporal position of the query, the task is categorized into interpolation and extrapolation. Existing interpolation methods typically embed temporal information into individual facts to complete missing historical knowledge, while extrapolation techniques often leverage sequence models over graph snapshots to identify recurring patterns for future event prediction. These methods face two critical challenges: limited contextual modeling in interpolation and cognitive generalization bias in extrapolation. To address these, we propose a unified method for TKGR, dubbed DynaGen. For interpolation, DynaGen dynamically constructs entity-centric subgraphs and processes them with a synergistic dual-branch GNN encoder to capture evolving structural context. For extrapolation, it applies a conditional diffusion process, which forces the model to learn underlying evolutionary principles rather than just superficial patterns, enhancing its ability to predict unseen future events. Extensive experiments on six benchmark datasets show DynaGen achieves state-of-the-art performance. On average, compared to the second-best models, DynaGen improves the Mean Reciprocal Rank (MRR) score by 2.61 points for interpolation and 1.45 points for extrapolation.
Automatic Failure Attribution and Critical Step Prediction Method for Multi-Agent Systems Based on Causal Inference
Sep 10, 2025Multi-agent systems (MAS) are critical for automating complex tasks, yet their practical deployment is severely hampered by the challenge of failure attribution. Current diagnostic tools, which rely on statistical correlations, are fundamentally inadequate; on challenging benchmarks like Who\&When, state-of-the-art methods achieve less than 15\% accuracy in locating the root-cause step of a failure. To address this critical gap, we introduce the first failure attribution framework for MAS grounded in multi-granularity causal inference. Our approach makes two key technical contributions: (1) a performance causal inversion principle, which correctly models performance dependencies by reversing the data flow in execution logs, combined with Shapley values to accurately assign agent-level blame; (2) a novel causal discovery algorithm, CDC-MAS, that robustly identifies critical failure steps by tackling the non-stationary nature of MAS interaction data. The framework's attribution results directly fuel an automated optimization loop, generating targeted suggestions whose efficacy is validated via counterfactual simulations. Evaluations on the Who\&When and TRAIL benchmarks demonstrate a significant leap in performance. Our method achieves up to 36.2\% step-level accuracy. Crucially, the generated optimizations boost overall task success rates by an average of 22.4\%. This work provides a principled and effective solution for debugging complex agent interactions, paving the way for more reliable and interpretable multi-agent systems.
Seed-Prover: Deep and Broad Reasoning for Automated Theorem Proving
Aug 01, 2025LLMs have demonstrated strong mathematical reasoning abilities by leveraging reinforcement learning with long chain-of-thought, yet they continue to struggle with theorem proving due to the lack of clear supervision signals when solely using natural language. Dedicated domain-specific languages like Lean provide clear supervision via formal verification of proofs, enabling effective training through reinforcement learning. In this work, we propose \textbf{Seed-Prover}, a lemma-style whole-proof reasoning model. Seed-Prover can iteratively refine its proof based on Lean feedback, proved lemmas, and self-summarization. To solve IMO-level contest problems, we design three test-time inference strategies that enable both deep and broad reasoning. Seed-Prover proves $78.1\%$ of formalized past IMO problems, saturates MiniF2F, and achieves over 50\% on PutnamBench, outperforming the previous state-of-the-art by a large margin. To address the lack of geometry support in Lean, we introduce a geometry reasoning engine \textbf{Seed-Geometry}, which outperforms previous formal geometry engines. We use these two systems to participate in IMO 2025 and fully prove 5 out of 6 problems. This work represents a significant advancement in automated mathematical reasoning, demonstrating the effectiveness of formal verification with long chain-of-thought reasoning.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025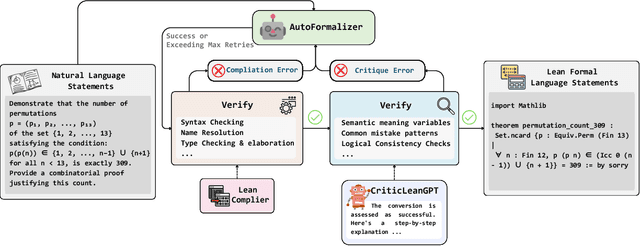

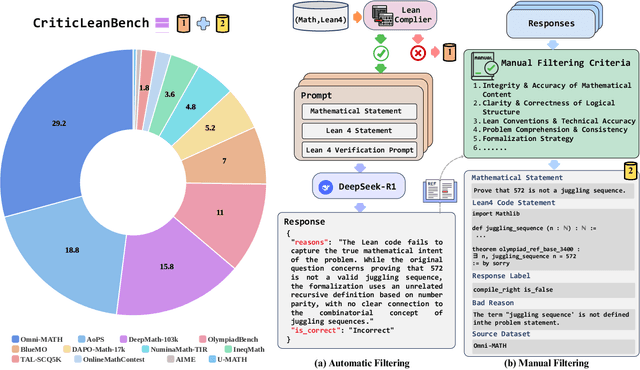
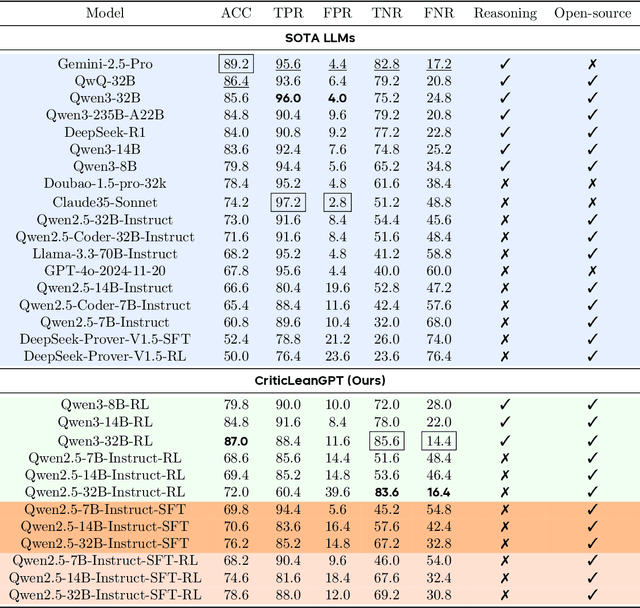
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
A Study of In-Context-Learning-Based Text-to-SQL Errors
Jan 16, 2025


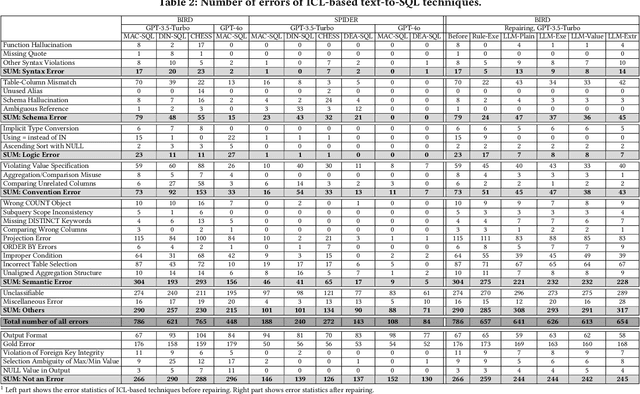
Large language models (LLMs) have been adopted to perform text-to-SQL tasks, utilizing their in-context learning (ICL) capability to translate natural language questions into structured query language (SQL). However, such a technique faces correctness problems and requires efficient repairing solutions. In this paper, we conduct the first comprehensive study of text-to-SQL errors. Our study covers four representative ICL-based techniques, five basic repairing methods, two benchmarks, and two LLM settings. We find that text-to-SQL errors are widespread and summarize 29 error types of 7 categories. We also find that existing repairing attempts have limited correctness improvement at the cost of high computational overhead with many mis-repairs. Based on the findings, we propose MapleRepair, a novel text-to-SQL error detection and repairing framework. The evaluation demonstrates that MapleRepair outperforms existing solutions by repairing 13.8% more queries with neglectable mis-repairs and 67.4% less overhead.
Vortex under Ripplet: An Empirical Study of RAG-enabled Applications
Jul 06, 2024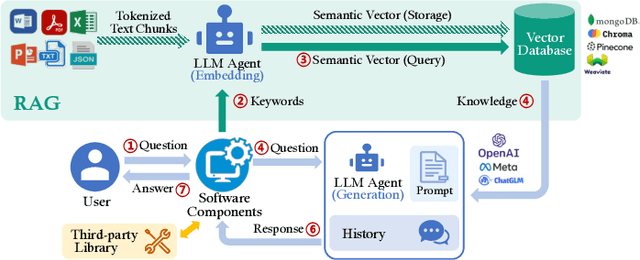
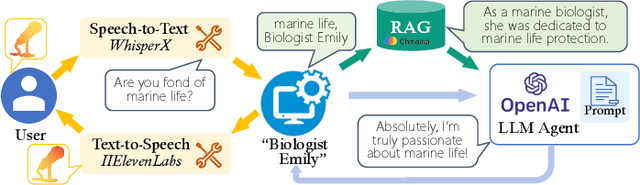


Large language models (LLMs) enhanced by retrieval-augmented generation (RAG) provide effective solutions in various application scenarios. However, developers face challenges in integrating RAG-enhanced LLMs into software systems, due to lack of interface specification, requirements from software context, and complicated system management. In this paper, we manually studied 100 open-source applications that incorporate RAG-enhanced LLMs, and their issue reports. We have found that more than 98% of applications contain multiple integration defects that harm software functionality, efficiency, and security. We have also generalized 19 defect patterns and proposed guidelines to tackle them. We hope this work could aid LLM-enabled software development and motivate future research.
Implicit Euler ODE Networks for Single-Image Dehazing
Jul 13, 2020
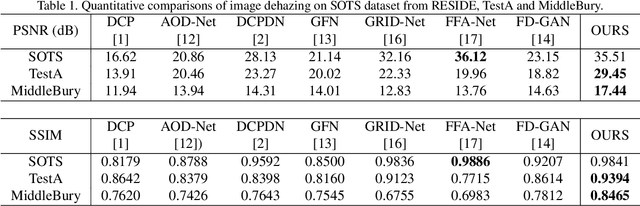
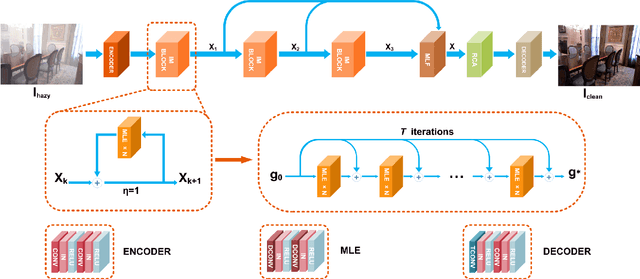

Deep convolutional neural networks (CNN) have been applied for image dehazing tasks, where the residual network (ResNet) is often adopted as the basic component to avoid the vanishing gradient problem. Recently, many works indicate that the ResNet can be considered as the explicit Euler forward approximation of an ordinary differential equation (ODE). In this paper, we extend the explicit forward approximation to the implicit backward counterpart, which can be realized via a recursive neural network, named IM-block. Given that, we propose an efficient end-to-end multi-level implicit network (MI-Net) for the single image dehazing problem. Moreover, multi-level fusing (MLF) mechanism and residual channel attention block (RCA-block) are adopted to boost performance of our network. Experiments on several dehazing benchmark datasets demonstrate that our method outperforms existing methods and achieves the state-of-the-art performance.