 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
From Text to Trust: Empowering AI-assisted Decision Making with Adaptive LLM-powered Analysis
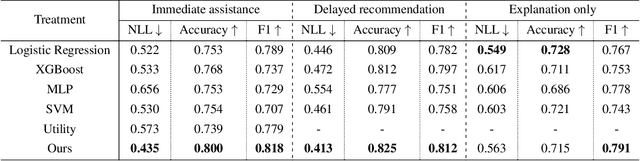
Feb 17, 2025AI-assisted decision making becomes increasingly prevalent, yet individuals often fail to utilize AI-based decision aids appropriately especially when the AI explanations are absent, potentially as they do not %understand reflect on AI's decision recommendations critically. Large language models (LLMs), with their exceptional conversational and analytical capabilities, present great opportunities to enhance AI-assisted decision making in the absence of AI explanations by providing natural-language-based analysis of AI's decision recommendation, e.g., how each feature of a decision making task might contribute to the AI recommendation. In this paper, via a randomized experiment, we first show that presenting LLM-powered analysis of each task feature, either sequentially or concurrently, does not significantly improve people's AI-assisted decision performance. To enable decision makers to better leverage LLM-powered analysis, we then propose an algorithmic framework to characterize the effects of LLM-powered analysis on human decisions and dynamically decide which analysis to present. Our evaluation with human subjects shows that this approach effectively improves decision makers' appropriate reliance on AI in AI-assisted decision making.
How Does the Disclosure of AI Assistance Affect the Perceptions of Writing?
Oct 06, 2024
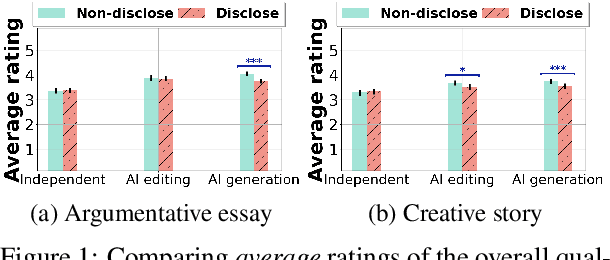
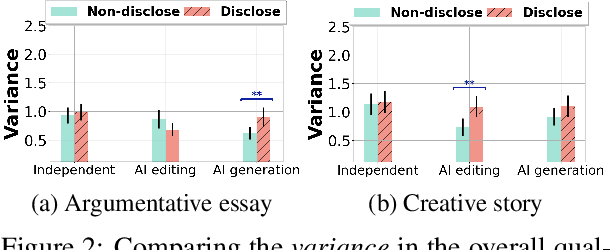
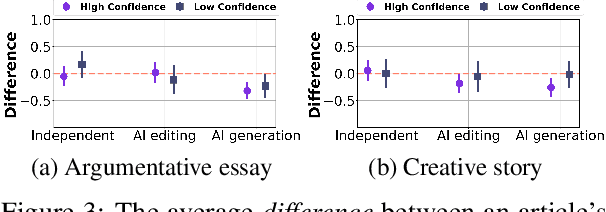
Recent advances in generative AI technologies like large language models have boosted the incorporation of AI assistance in writing workflows, leading to the rise of a new paradigm of human-AI co-creation in writing. To understand how people perceive writings that are produced under this paradigm, in this paper, we conduct an experimental study to understand whether and how the disclosure of the level and type of AI assistance in the writing process would affect people's perceptions of the writing on various aspects, including their evaluation on the quality of the writing and their ranking of different writings. Our results suggest that disclosing the AI assistance in the writing process, especially if AI has provided assistance in generating new content, decreases the average quality ratings for both argumentative essays and creative stories. This decrease in the average quality ratings often comes with an increased level of variations in different individuals' quality evaluations of the same writing. Indeed, factors such as an individual's writing confidence and familiarity with AI writing assistants are shown to moderate the impact of AI assistance disclosure on their writing quality evaluations. We also find that disclosing the use of AI assistance may significantly reduce the proportion of writings produced with AI's content generation assistance among the top-ranked writings.
Decoding AI's Nudge: A Unified Framework to Predict Human Behavior in AI-assisted Decision Making
Jan 11, 2024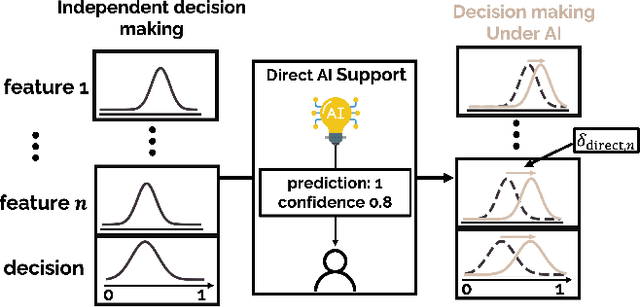
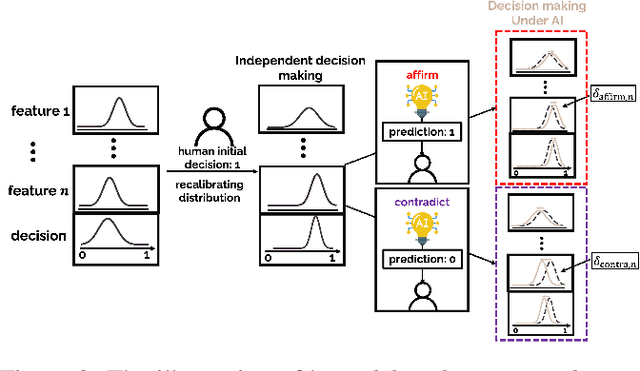

With the rapid development of AI-based decision aids, different forms of AI assistance have been increasingly integrated into the human decision making processes. To best support humans in decision making, it is essential to quantitatively understand how diverse forms of AI assistance influence humans' decision making behavior. To this end, much of the current research focuses on the end-to-end prediction of human behavior using ``black-box'' models, often lacking interpretations of the nuanced ways in which AI assistance impacts the human decision making process. Meanwhile, methods that prioritize the interpretability of human behavior predictions are often tailored for one specific form of AI assistance, making adaptations to other forms of assistance difficult. In this paper, we propose a computational framework that can provide an interpretable characterization of the influence of different forms of AI assistance on decision makers in AI-assisted decision making. By conceptualizing AI assistance as the ``{\em nudge}'' in human decision making processes, our approach centers around modelling how different forms of AI assistance modify humans' strategy in weighing different information in making their decisions. Evaluations on behavior data collected from real human decision makers show that the proposed framework outperforms various baselines in accurately predicting human behavior in AI-assisted decision making. Based on the proposed framework, we further provide insights into how individuals with different cognitive styles are nudged by AI assistance differently.
Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations
Oct 13, 2023
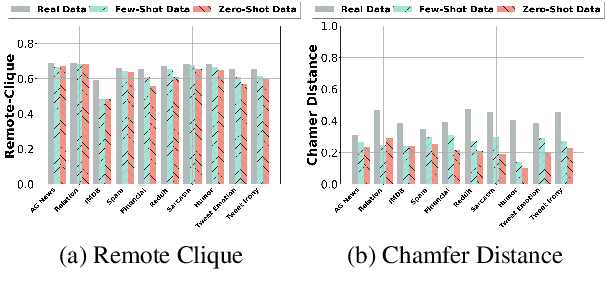


The collection and curation of high-quality training data is crucial for developing text classification models with superior performance, but it is often associated with significant costs and time investment. Researchers have recently explored using large language models (LLMs) to generate synthetic datasets as an alternative approach. However, the effectiveness of the LLM-generated synthetic data in supporting model training is inconsistent across different classification tasks. To better understand factors that moderate the effectiveness of the LLM-generated synthetic data, in this study, we look into how the performance of models trained on these synthetic data may vary with the subjectivity of classification. Our results indicate that subjectivity, at both the task level and instance level, is negatively associated with the performance of the model trained on synthetic data. We conclude by discussing the implications of our work on the potential and limitations of leveraging LLM for synthetic data generation.
Implicit Euler ODE Networks for Single-Image Dehazing
Jul 13, 2020
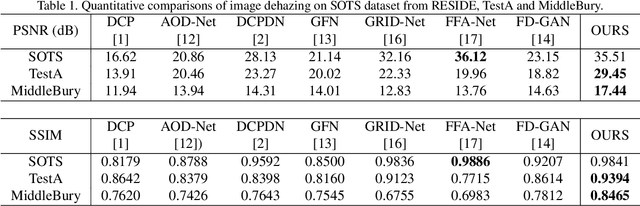
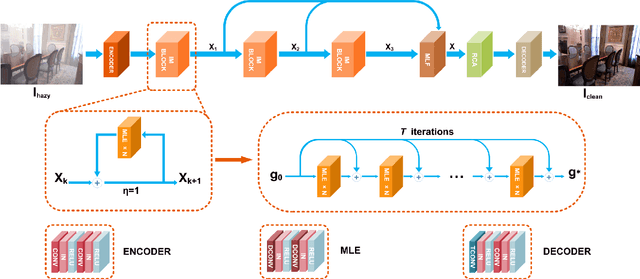

Deep convolutional neural networks (CNN) have been applied for image dehazing tasks, where the residual network (ResNet) is often adopted as the basic component to avoid the vanishing gradient problem. Recently, many works indicate that the ResNet can be considered as the explicit Euler forward approximation of an ordinary differential equation (ODE). In this paper, we extend the explicit forward approximation to the implicit backward counterpart, which can be realized via a recursive neural network, named IM-block. Given that, we propose an efficient end-to-end multi-level implicit network (MI-Net) for the single image dehazing problem. Moreover, multi-level fusing (MLF) mechanism and residual channel attention block (RCA-block) are adopted to boost performance of our network. Experiments on several dehazing benchmark datasets demonstrate that our method outperforms existing methods and achieves the state-of-the-art performance.