 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Text to Trust: Empowering AI-assisted Decision Making with Adaptive LLM-powered Analysis
Feb 17, 2025AI-assisted decision making becomes increasingly prevalent, yet individuals often fail to utilize AI-based decision aids appropriately especially when the AI explanations are absent, potentially as they do not %understand reflect on AI's decision recommendations critically. Large language models (LLMs), with their exceptional conversational and analytical capabilities, present great opportunities to enhance AI-assisted decision making in the absence of AI explanations by providing natural-language-based analysis of AI's decision recommendation, e.g., how each feature of a decision making task might contribute to the AI recommendation. In this paper, via a randomized experiment, we first show that presenting LLM-powered analysis of each task feature, either sequentially or concurrently, does not significantly improve people's AI-assisted decision performance. To enable decision makers to better leverage LLM-powered analysis, we then propose an algorithmic framework to characterize the effects of LLM-powered analysis on human decisions and dynamically decide which analysis to present. Our evaluation with human subjects shows that this approach effectively improves decision makers' appropriate reliance on AI in AI-assisted decision making.
Synthetic Data Generation with Large Language Models for Text Classification: Potential and Limitations
Oct 13, 2023
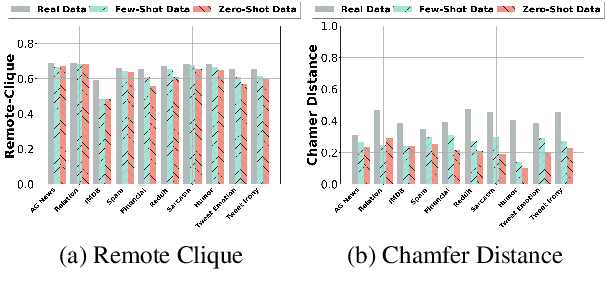


The collection and curation of high-quality training data is crucial for developing text classification models with superior performance, but it is often associated with significant costs and time investment. Researchers have recently explored using large language models (LLMs) to generate synthetic datasets as an alternative approach. However, the effectiveness of the LLM-generated synthetic data in supporting model training is inconsistent across different classification tasks. To better understand factors that moderate the effectiveness of the LLM-generated synthetic data, in this study, we look into how the performance of models trained on these synthetic data may vary with the subjectivity of classification. Our results indicate that subjectivity, at both the task level and instance level, is negatively associated with the performance of the model trained on synthetic data. We conclude by discussing the implications of our work on the potential and limitations of leveraging LLM for synthetic data generation.