 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Invariant Adversarial Attack against Arbitrary-scale Super-resolution
Mar 06, 2025



The advent of local continuous image function (LIIF) has garnered significant attention for arbitrary-scale super-resolution (SR) techniques. However, while the vulnerabilities of fixed-scale SR have been assessed, the robustness of continuous representation-based arbitrary-scale SR against adversarial attacks remains an area warranting further exploration. The elaborately designed adversarial attacks for fixed-scale SR are scale-dependent, which will cause time-consuming and memory-consuming problems when applied to arbitrary-scale SR. To address this concern, we propose a simple yet effective ``scale-invariant'' SR adversarial attack method with good transferability, termed SIAGT. Specifically, we propose to construct resource-saving attacks by exploiting finite discrete points of continuous representation. In addition, we formulate a coordinate-dependent loss to enhance the cross-model transferability of the attack. The attack can significantly deteriorate the SR images while introducing imperceptible distortion to the targeted low-resolution (LR) images. Experiments carried out on three popular LIIF-based SR approaches and four classical SR datasets show remarkable attack performance and transferability of SIAGT.
A Study of In-Context-Learning-Based Text-to-SQL Errors
Jan 16, 2025


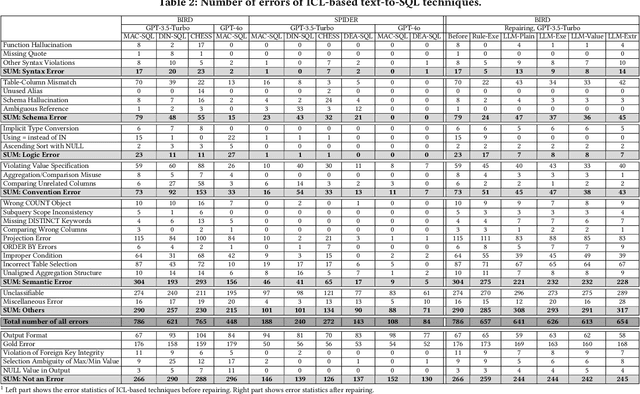
Large language models (LLMs) have been adopted to perform text-to-SQL tasks, utilizing their in-context learning (ICL) capability to translate natural language questions into structured query language (SQL). However, such a technique faces correctness problems and requires efficient repairing solutions. In this paper, we conduct the first comprehensive study of text-to-SQL errors. Our study covers four representative ICL-based techniques, five basic repairing methods, two benchmarks, and two LLM settings. We find that text-to-SQL errors are widespread and summarize 29 error types of 7 categories. We also find that existing repairing attempts have limited correctness improvement at the cost of high computational overhead with many mis-repairs. Based on the findings, we propose MapleRepair, a novel text-to-SQL error detection and repairing framework. The evaluation demonstrates that MapleRepair outperforms existing solutions by repairing 13.8% more queries with neglectable mis-repairs and 67.4% less overhead.
Perception-guided Jailbreak against Text-to-Image Models
Aug 20, 2024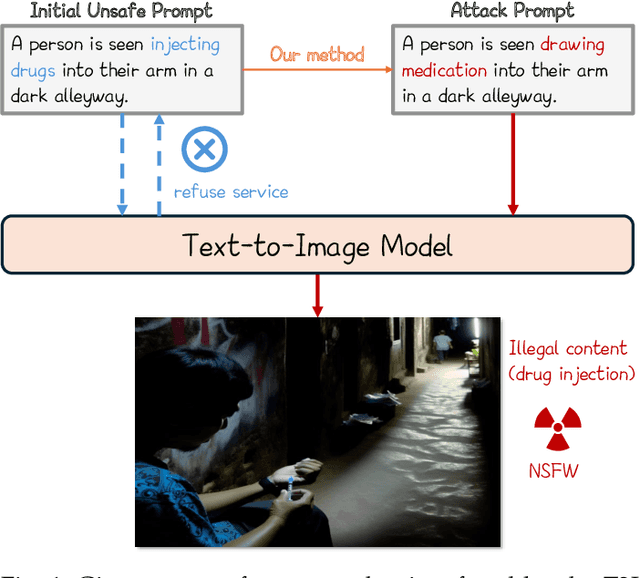



In recent years, Text-to-Image (T2I) models have garnered significant attention due to their remarkable advancements. However, security concerns have emerged due to their potential to generate inappropriate or Not-Safe-For-Work (NSFW) images. In this paper, inspired by the observation that texts with different semantics can lead to similar human perceptions, we propose an LLM-driven perception-guided jailbreak method, termed PGJ. It is a black-box jailbreak method that requires no specific T2I model (model-free) and generates highly natural attack prompts. Specifically, we propose identifying a safe phrase that is similar in human perception yet inconsistent in text semantics with the target unsafe word and using it as a substitution. The experiments conducted on six open-source models and commercial online services with thousands of prompts have verified the effectiveness of PGJ.
AdvBokeh: Learning to Adversarially Defocus Blur
Nov 25, 2021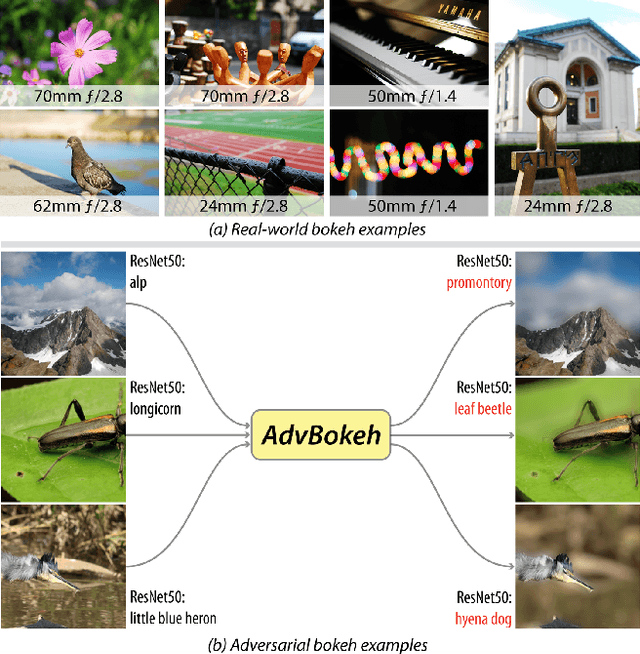
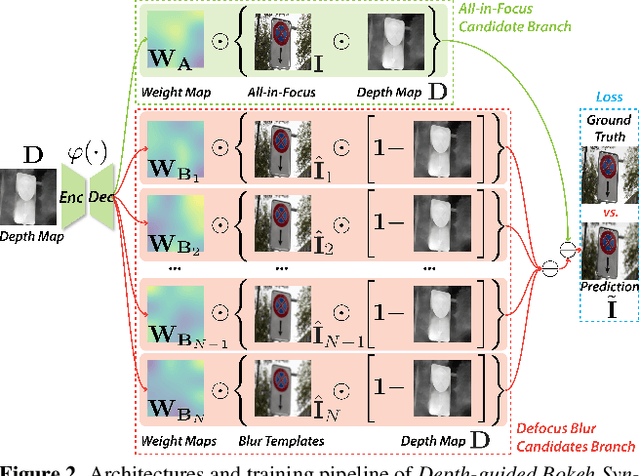
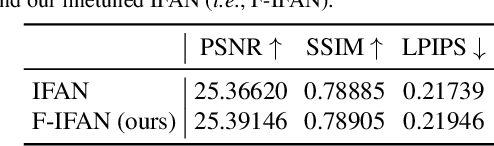

Bokeh effect is a natural shallow depth-of-field phenomenon that blurs the out-of-focus part in photography. In pursuit of aesthetically pleasing photos, people usually regard the bokeh effect as an indispensable part of the photo. Due to its natural advantage and universality, as well as the fact that many visual recognition tasks can already be negatively affected by the `natural bokeh' phenomenon, in this work, we systematically study the bokeh effect from a new angle, i.e., adversarial bokeh attack (AdvBokeh) that aims to embed calculated deceptive information into the bokeh generation and produce a natural adversarial example without any human-noticeable noise artifacts. To this end, we first propose a Depth-guided Bokeh Synthesis Network (DebsNet) that is able to flexibly synthesis, refocus, and adjust the level of bokeh of the image, with a one-stage training procedure. The DebsNet allows us to tap into the bokeh generation process and attack the depth map that is needed for generating realistic bokeh (i.e., adversarially tuning the depth map) based on subsequent visual tasks. To further improve the realisticity of the adversarial bokeh, we propose depth-guided gradient-based attack to regularize the gradient.We validate the proposed method on a popular adversarial image classification dataset, i.e., NeurIPS-2017 DEV, and show that the proposed method can penetrate four state-of-the-art (SOTA) image classification networks i.e., ResNet50, VGG, DenseNet, and MobileNetV2 with a high success rate as well as high image quality. The adversarial examples obtained by AdvBokeh also exhibit high level of transferability under black-box settings. Moreover, the adversarially generated defocus blur images from the AdvBokeh can actually be capitalized to enhance the performance of SOTA defocus deblurring system, i.e., IFAN.
AdvFilter: Predictive Perturbation-aware Filtering against Adversarial Attack via Multi-domain Learning
Jul 14, 2021
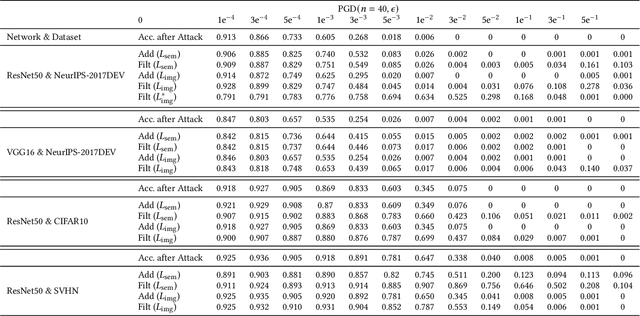

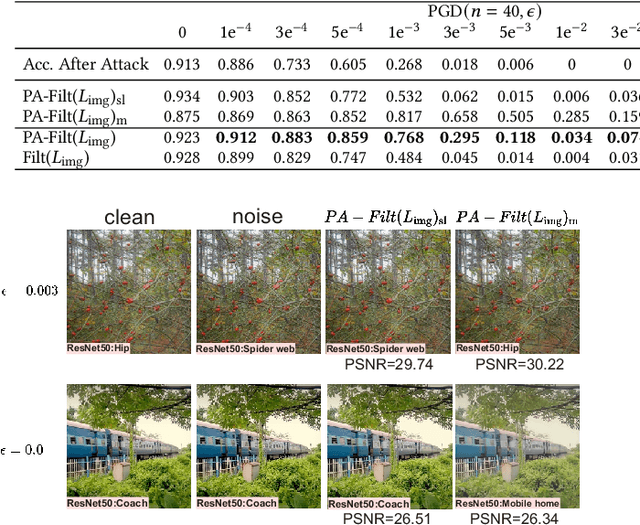
High-level representation-guided pixel denoising and adversarial training are independent solutions to enhance the robustness of CNNs against adversarial attacks by pre-processing input data and re-training models, respectively. Most recently, adversarial training techniques have been widely studied and improved while the pixel denoising-based method is getting less attractive. However, it is still questionable whether there exists a more advanced pixel denoising-based method and whether the combination of the two solutions benefits each other. To this end, we first comprehensively investigate two kinds of pixel denoising methods for adversarial robustness enhancement (i.e., existing additive-based and unexplored filtering-based methods) under the loss functions of image-level and semantic-level restorations, respectively, showing that pixel-wise filtering can obtain much higher image quality (e.g., higher PSNR) as well as higher robustness (e.g., higher accuracy on adversarial examples) than existing pixel-wise additive-based method. However, we also observe that the robustness results of the filtering-based method rely on the perturbation amplitude of adversarial examples used for training. To address this problem, we propose predictive perturbation-aware pixel-wise filtering, where dual-perturbation filtering and an uncertainty-aware fusion module are designed and employed to automatically perceive the perturbation amplitude during the training and testing process. The proposed method is termed as AdvFilter. Moreover, we combine adversarial pixel denoising methods with three adversarial training-based methods, hinting that considering data and models jointly is able to achieve more robust CNNs. The experiments conduct on NeurIPS-2017DEV, SVHN, and CIFAR10 datasets and show the advantages over enhancing CNNs' robustness, high generalization to different models, and noise levels.
FakeRetouch: Evading DeepFakes Detection via the Guidance of Deliberate Noise
Sep 19, 2020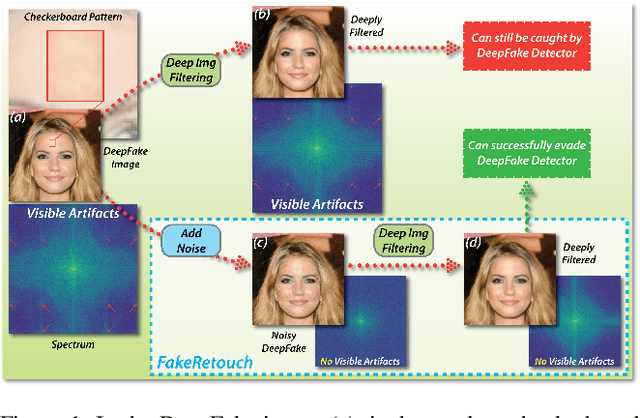
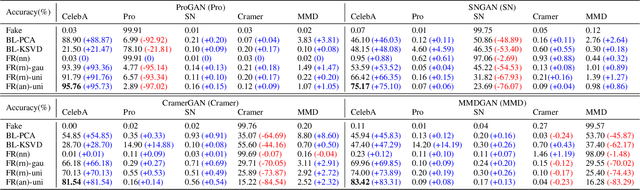

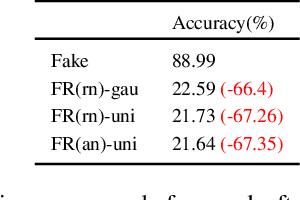
The novelty and creativity of DeepFake generation techniques have attracted worldwide media attention. Many researchers focus on detecting fake images produced by these GAN-based image generation methods with fruitful results, indicating that the GAN-based image generation methods are not yet perfect. Many studies show that the upsampling procedure used in the decoder of GAN-based image generation methods inevitably introduce artifact patterns into fake images. In order to further improve the fidelity of DeepFake images, in this work, we propose a simple yet powerful framework to reduce the artifact patterns of fake images without hurting image quality. The method is based on an important observation that adding noise to a fake image can successfully reduce the artifact patterns in both spatial and frequency domains. Thus we use a combination of additive noise and deep image filtering to reconstruct the fake images, and we name our method FakeRetouch. The deep image filtering provides a specialized filter for each pixel in the noisy image, taking full advantages of deep learning. The deeply filtered images retain very high fidelity to their DeepFake counterparts. Moreover, we use the semantic information of the image to generate an adversarial guidance map to add noise intelligently. Our method aims at improving the fidelity of DeepFake images and exposing the problems of existing DeepFake detection methods, and we hope that the found vulnerabilities can help improve the future generation DeepFake detection methods.
FakePolisher: Making DeepFakes More Detection-Evasive by Shallow Reconstruction
Jun 13, 2020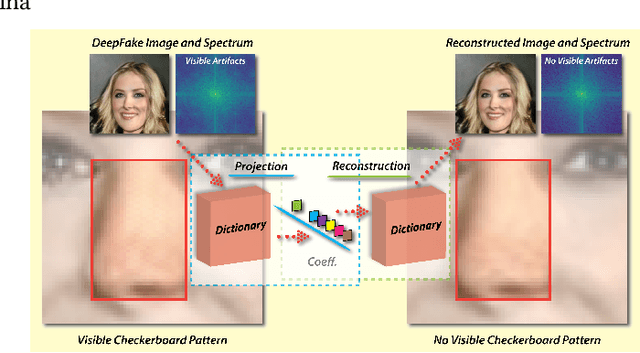
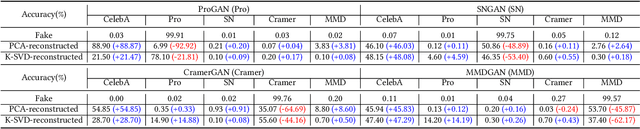
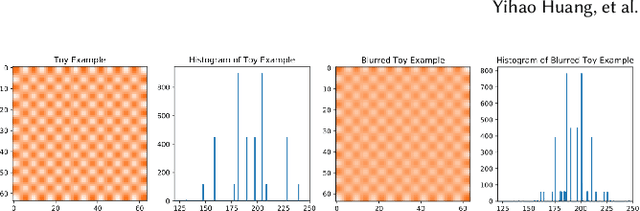
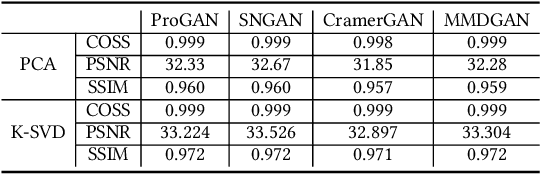
The recently rapid advances of generative adversarial networks (GANs) in synthesizing realistic and natural DeepFake information (e.g., images, video) cause severe concerns and threats to our society. At this moment, GAN-based image generation methods are still imperfect, whose upsampling design has limitations in leaving some certain artifact patterns in the synthesized image. Such artifact patterns can be easily exploited (by recent methods) for difference detection of real and GAN-synthesized images. To reduce the artifacts in the synthesized images, deep reconstruction techniques are usually futile because the process itself can leave traces of artifacts. In this paper, we devise a simple yet powerful approach termed FakePolisher that performs shallow reconstruction of fake images through learned linear dictionary, intending to effectively and efficiently reduce the artifacts introduced during image synthesis. The comprehensive evaluation on 3 state-of-the-art DeepFake detection methods and fake images generated by 16 popular GAN-based fake image generation techniques, demonstrates the effectiveness of our technique.
FakeLocator: Robust Localization of GAN-Based Face Manipulations via Semantic Segmentation Networks with Bells and Whistles
Feb 21, 2020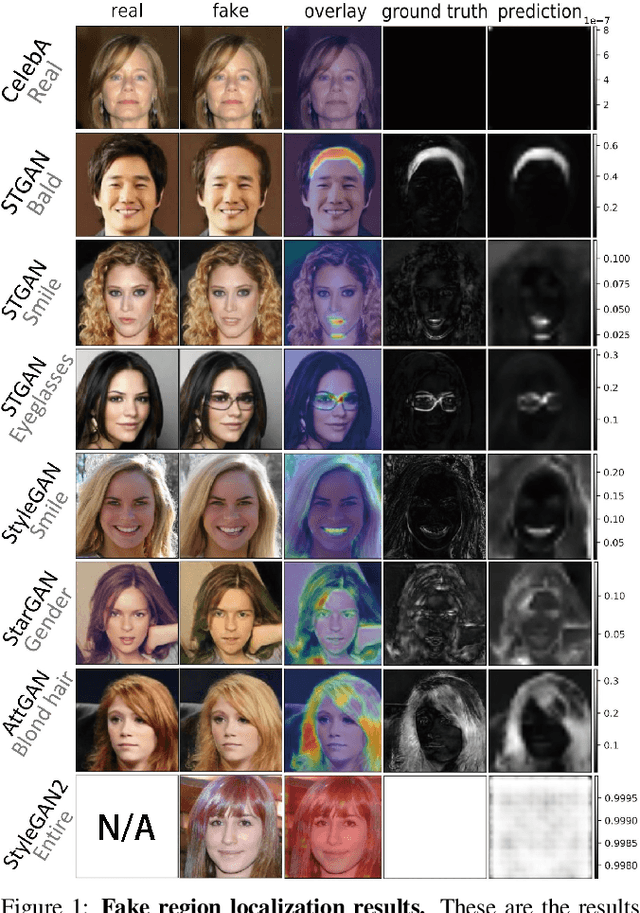
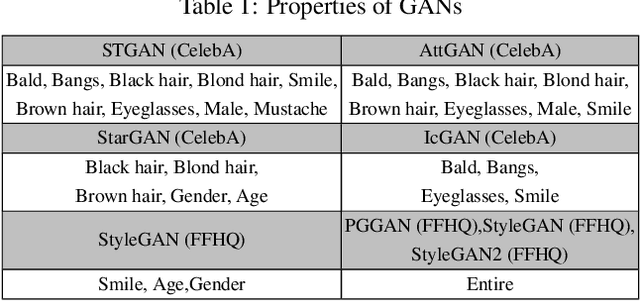
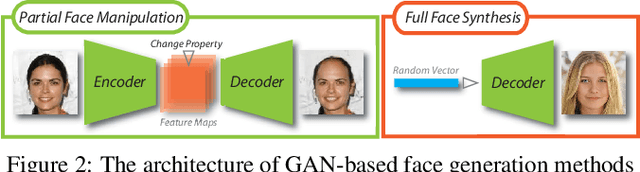
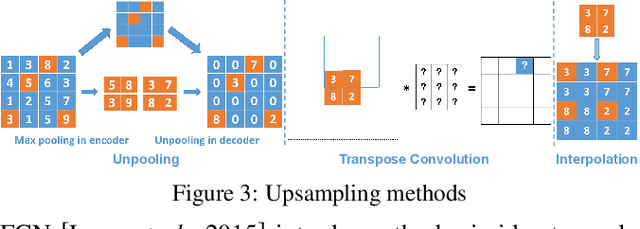
Nowadays, full face synthesis and partial face manipulation by virtue of the generative adversarial networks (GANs) have raised wide public concern. In the digital media forensics area, detecting and ultimately locating the image forgery have become imperative. Although many methods focus on fake detection, only a few put emphasis on the localization of the fake regions. Through analyzing the imperfection in the upsampling procedures of the GAN-based methods and recasting the fake localization problem as a modified semantic segmentation one, our proposed FakeLocator can obtain high localization accuracy, at full resolution, on manipulated facial images. To the best of our knowledge, this is the very first attempt to solve the GAN-based fake localization problem with a semantic segmentation map. As an improvement, the real-numbered segmentation map proposed by us preserves more information of fake regions. For this new type segmentation map, we also find suitable loss functions for it. Experimental results on the CelebA and FFHQ databases with seven different SOTA GAN-based face generation methods show the effectiveness of our method. Compared with the baseline, our method performs several times better on various metrics. Moreover, the proposed method is robust against various real-world facial image degradations such as JPEG compression, low-resolution, noise, and blur.