 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerception-guided Jailbreak against Text-to-Image Models
Paper and Code
Aug 20, 2024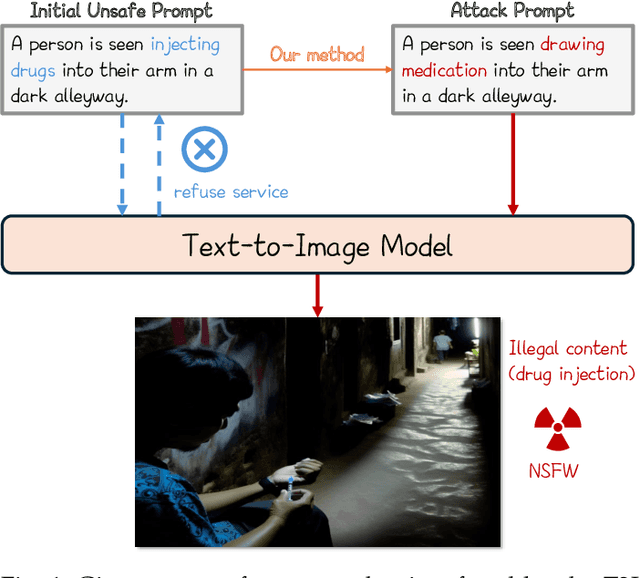



In recent years, Text-to-Image (T2I) models have garnered significant attention due to their remarkable advancements. However, security concerns have emerged due to their potential to generate inappropriate or Not-Safe-For-Work (NSFW) images. In this paper, inspired by the observation that texts with different semantics can lead to similar human perceptions, we propose an LLM-driven perception-guided jailbreak method, termed PGJ. It is a black-box jailbreak method that requires no specific T2I model (model-free) and generates highly natural attack prompts. Specifically, we propose identifying a safe phrase that is similar in human perception yet inconsistent in text semantics with the target unsafe word and using it as a substitution. The experiments conducted on six open-source models and commercial online services with thousands of prompts have verified the effectiveness of PGJ.