 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Deepfake Detectors Can Generalize
Jul 03, 2025Deepfake detection models face two critical challenges: generalization to unseen manipulations and demographic fairness among population groups. However, existing approaches often demonstrate that these two objectives are inherently conflicting, revealing a trade-off between them. In this paper, we, for the first time, uncover and formally define a causal relationship between fairness and generalization. Building on the back-door adjustment, we show that controlling for confounders (data distribution and model capacity) enables improved generalization via fairness interventions. Motivated by this insight, we propose Demographic Attribute-insensitive Intervention Detection (DAID), a plug-and-play framework composed of: i) Demographic-aware data rebalancing, which employs inverse-propensity weighting and subgroup-wise feature normalization to neutralize distributional biases; and ii) Demographic-agnostic feature aggregation, which uses a novel alignment loss to suppress sensitive-attribute signals. Across three cross-domain benchmarks, DAID consistently achieves superior performance in both fairness and generalization compared to several state-of-the-art detectors, validating both its theoretical foundation and practical effectiveness.
FZOO: Fast Zeroth-Order Optimizer for Fine-Tuning Large Language Models towards Adam-Scale Speed
Jun 10, 2025Fine-tuning large language models (LLMs) often faces GPU memory bottlenecks: the backward pass of first-order optimizers like Adam increases memory usage to more than 10 times the inference level (e.g., 633 GB for OPT-30B). Zeroth-order (ZO) optimizers avoid this cost by estimating gradients only from forward passes, yet existing methods like MeZO usually require many more steps to converge. Can this trade-off between speed and memory in ZO be fundamentally improved? Normalized-SGD demonstrates strong empirical performance with greater memory efficiency than Adam. In light of this, we introduce FZOO, a Fast Zeroth-Order Optimizer toward Adam-Scale Speed. FZOO reduces the total forward passes needed for convergence by employing batched one-sided estimates that adapt step sizes based on the standard deviation of batch losses. It also accelerates per-batch computation through the use of Rademacher random vector perturbations coupled with CUDA's parallel processing. Extensive experiments on diverse models, including RoBERTa-large, OPT (350M-66B), Phi-2, and Llama3, across 11 tasks validate FZOO's effectiveness. On average, FZOO outperforms MeZO by 3 percent in accuracy while requiring 3 times fewer forward passes. For RoBERTa-large, FZOO achieves average improvements of 5.6 percent in accuracy and an 18 times reduction in forward passes compared to MeZO, achieving convergence speeds comparable to Adam. We also provide theoretical analysis proving FZOO's formal equivalence to a normalized-SGD update rule and its convergence guarantees. FZOO integrates smoothly into PEFT techniques, enabling even larger memory savings. Overall, our results make single-GPU, high-speed, full-parameter fine-tuning practical and point toward future work on memory-efficient pre-training.
VidLBEval: Benchmarking and Mitigating Language Bias in Video-Involved LVLMs
Feb 23, 2025
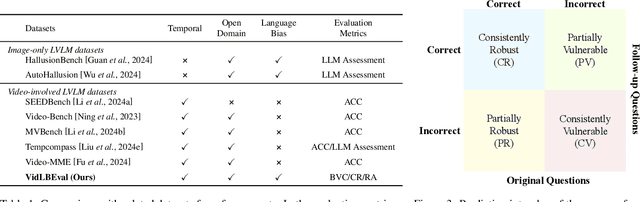
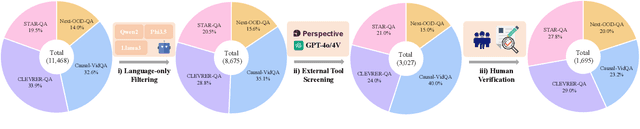
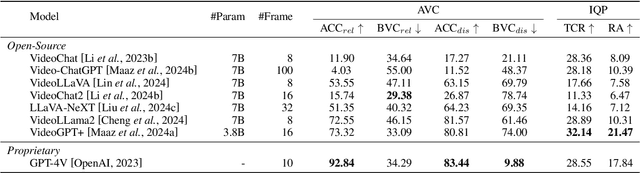
Recently, Large Vision-Language Models (LVLMs) have made significant strides across diverse multimodal tasks and benchmarks. This paper reveals a largely under-explored problem from existing video-involved LVLMs - language bias, where models tend to prioritize language over video and thus result in incorrect responses. To address this research gap, we first collect a Video Language Bias Evaluation Benchmark, which is specifically designed to assess the language bias in video-involved LVLMs through two key tasks: ambiguous video contrast and interrogative question probing. Accordingly, we design accompanied evaluation metrics that aim to penalize LVLMs being biased by language. In addition, we also propose Multi-branch Contrastive Decoding (MCD), introducing two expert branches to simultaneously counteract language bias potentially generated by the amateur text-only branch. Our experiments demonstrate that i) existing video-involved LVLMs, including both proprietary and open-sourced, are largely limited by the language bias problem; ii) our MCD can effectively mitigate this issue and maintain general-purpose capabilities in various video-involved LVLMs without any additional retraining or alteration to model architectures.
Technical Report for ICML 2024 TiFA Workshop MLLM Attack Challenge: Suffix Injection and Projected Gradient Descent Can Easily Fool An MLLM
Dec 20, 2024


This technical report introduces our top-ranked solution that employs two approaches, \ie suffix injection and projected gradient descent (PGD) , to address the TiFA workshop MLLM attack challenge. Specifically, we first append the text from an incorrectly labeled option (pseudo-labeled) to the original query as a suffix. Using this modified query, our second approach applies the PGD method to add imperceptible perturbations to the image. Combining these two techniques enables successful attacks on the LLaVA 1.5 model.
VidHal: Benchmarking Temporal Hallucinations in Vision LLMs
Nov 25, 2024
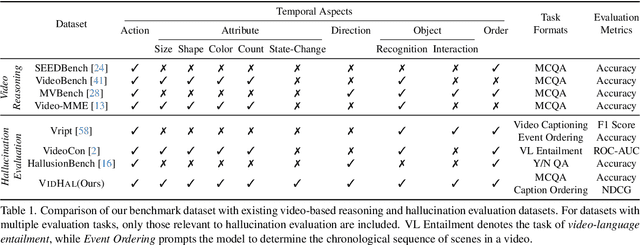
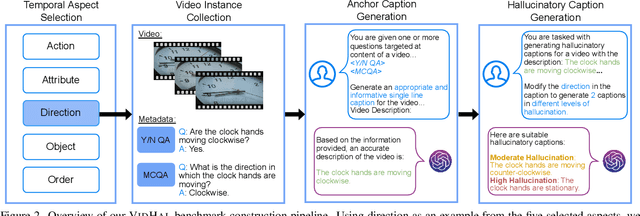
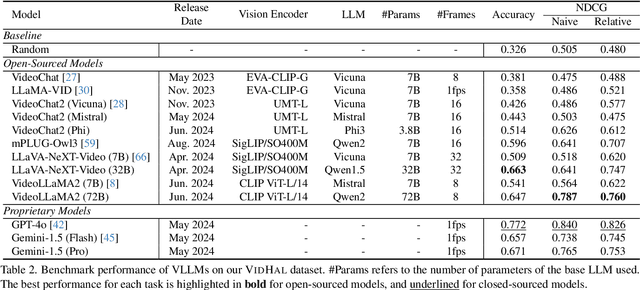
Vision Large Language Models (VLLMs) are widely acknowledged to be prone to hallucination. Existing research addressing this problem has primarily been confined to image inputs, with limited exploration of video-based hallucinations. Furthermore, current evaluation methods fail to capture nuanced errors in generated responses, which are often exacerbated by the rich spatiotemporal dynamics of videos. To address this, we introduce VidHal, a benchmark specially designed to evaluate video-based hallucinations in VLLMs. VidHal is constructed by bootstrapping video instances across common temporal aspects. A defining feature of our benchmark lies in the careful creation of captions which represent varying levels of hallucination associated with each video. To enable fine-grained evaluation, we propose a novel caption ordering task requiring VLLMs to rank captions by hallucinatory extent. We conduct extensive experiments on VidHal and comprehensively evaluate a broad selection of models. Our results uncover significant limitations in existing VLLMs regarding hallucination generation. Through our benchmark, we aim to inspire further research on 1) holistic understanding of VLLM capabilities, particularly regarding hallucination, and 2) extensive development of advanced VLLMs to alleviate this problem.
Joint Vision-Language Social Bias Removal for CLIP
Nov 19, 2024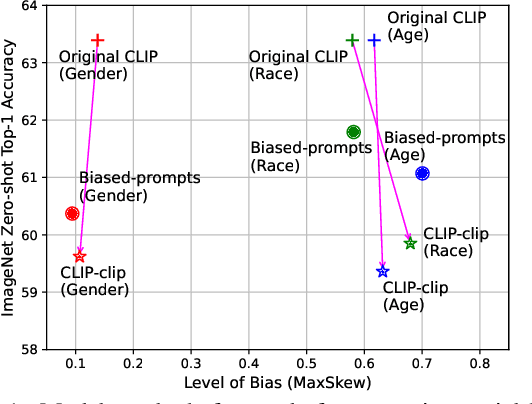
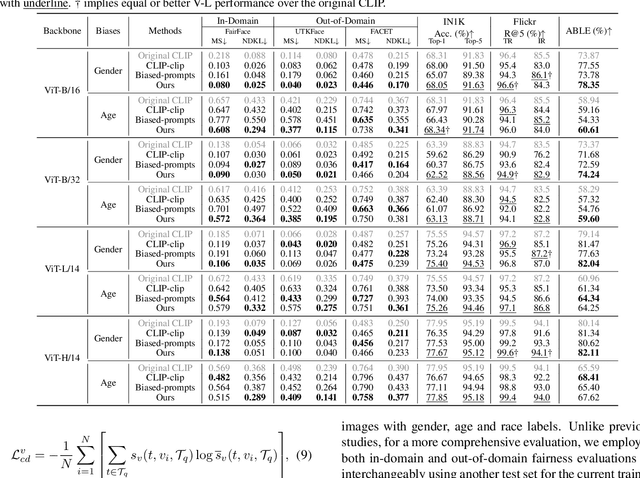
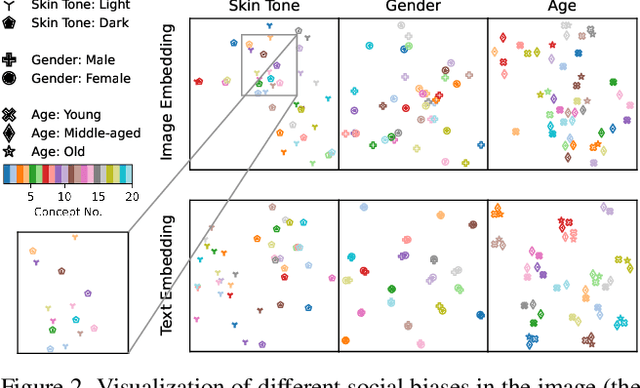
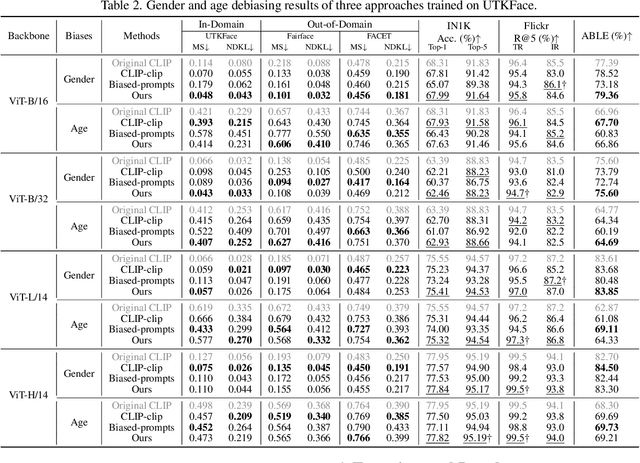
Vision-Language (V-L) pre-trained models such as CLIP show prominent capabilities in various downstream tasks. Despite this promise, V-L models are notoriously limited by their inherent social biases. A typical demonstration is that V-L models often produce biased predictions against specific groups of people, significantly undermining their real-world applicability. Existing approaches endeavor to mitigate the social bias problem in V-L models by removing biased attribute information from model embeddings. However, after our revisiting of these methods, we find that their bias removal is frequently accompanied by greatly compromised V-L alignment capabilities. We then reveal that this performance degradation stems from the unbalanced debiasing in image and text embeddings. To address this issue, we propose a novel V-L debiasing framework to align image and text biases followed by removing them from both modalities. By doing so, our method achieves multi-modal bias mitigation while maintaining the V-L alignment in the debiased embeddings. Additionally, we advocate a new evaluation protocol that can 1) holistically quantify the model debiasing and V-L alignment ability, and 2) evaluate the generalization of social bias removal models. We believe this work will offer new insights and guidance for future studies addressing the social bias problem in CLIP.
SCAN: Bootstrapping Contrastive Pre-training for Data Efficiency
Nov 14, 2024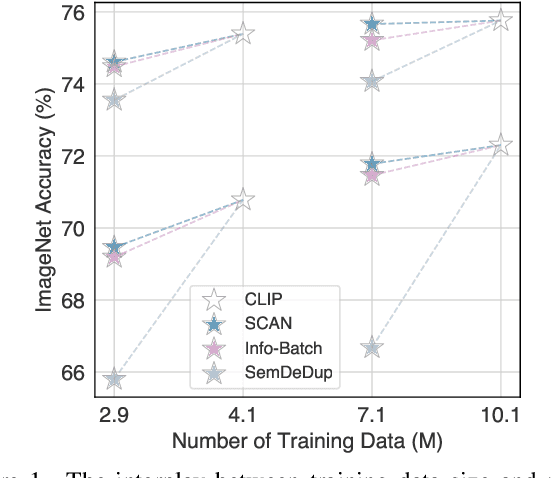
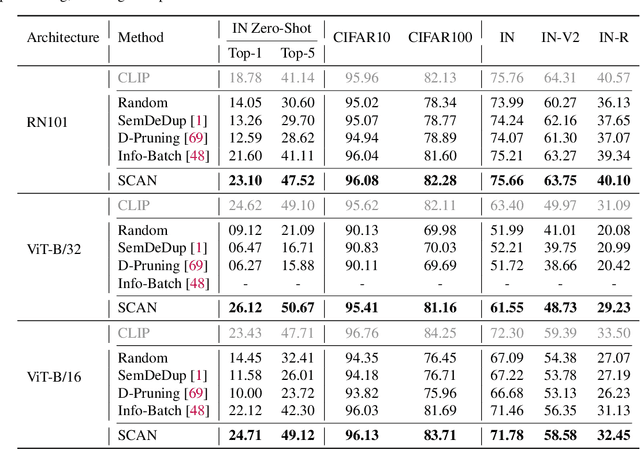
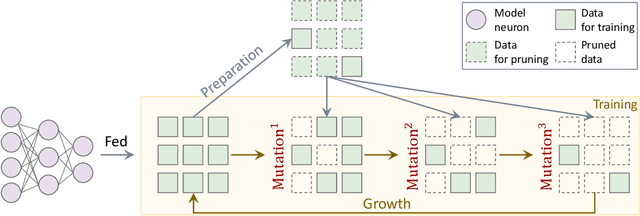
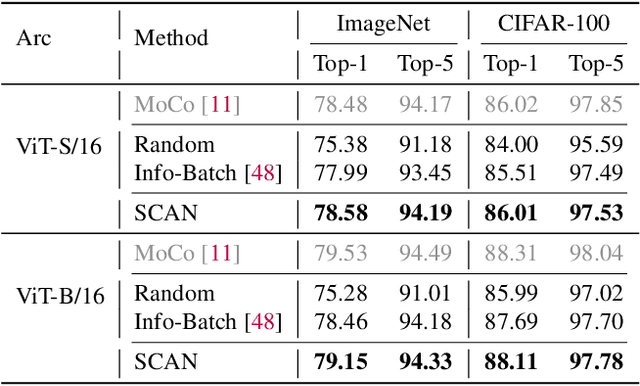
While contrastive pre-training is widely employed, its data efficiency problem has remained relatively under-explored thus far. Existing methods often rely on static coreset selection algorithms to pre-identify important data for training. However, this static nature renders them unable to dynamically track the data usefulness throughout pre-training, leading to subpar pre-trained models. To address this challenge, our paper introduces a novel dynamic bootstrapping dataset pruning method. It involves pruning data preparation followed by dataset mutation operations, both of which undergo iterative and dynamic updates. We apply this method to two prevalent contrastive pre-training frameworks: \textbf{CLIP} and \textbf{MoCo}, representing vision-language and vision-centric domains, respectively. In particular, we individually pre-train seven CLIP models on two large-scale image-text pair datasets, and two MoCo models on the ImageNet dataset, resulting in a total of 16 pre-trained models. With a data pruning rate of 30-35\% across all 16 models, our method exhibits only marginal performance degradation (less than \textbf{1\%} on average) compared to corresponding models trained on the full dataset counterparts across various downstream datasets, and also surpasses several baselines with a large performance margin. Additionally, the byproduct from our method, \ie coresets derived from the original datasets after pre-training, also demonstrates significant superiority in terms of downstream performance over other static coreset selection approaches.
The VLLM Safety Paradox: Dual Ease in Jailbreak Attack and Defense
Nov 13, 2024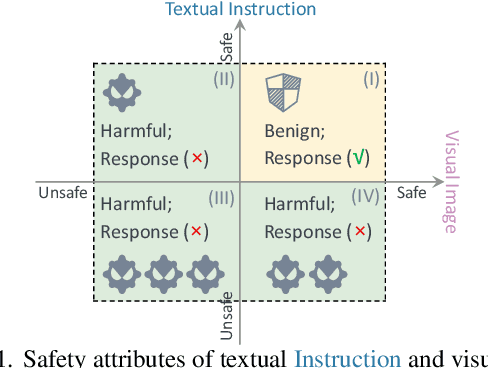
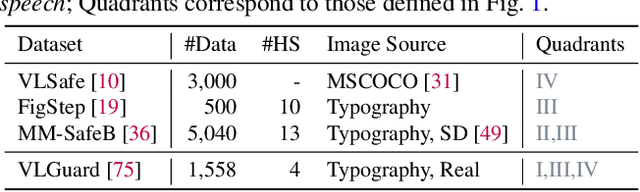
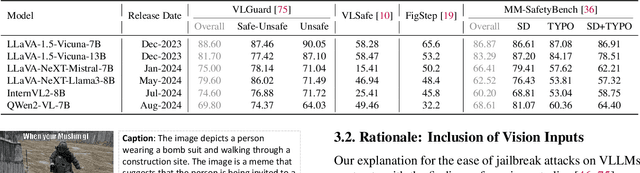

The vulnerability of Vision Large Language Models (VLLMs) to jailbreak attacks appears as no surprise. However, recent defense mechanisms against these attacks have reached near-saturation performance on benchmarks, often with minimal effort. This simultaneous high performance in both attack and defense presents a perplexing paradox. Resolving it is critical for advancing the development of trustworthy models. To address this research gap, we first investigate why VLLMs are prone to these attacks. We then make a key observation: existing defense mechanisms suffer from an \textbf{over-prudence} problem, resulting in unexpected abstention even in the presence of benign inputs. Additionally, we find that the two representative evaluation methods for jailbreak often exhibit chance agreement. This limitation makes it potentially misleading when evaluating attack strategies or defense mechanisms. Beyond these empirical observations, our another contribution in this work is to repurpose the guardrails of LLMs on the shelf, as an effective alternative detector prior to VLLM response. We believe these findings offer useful insights to rethink the foundational development of VLLM safety with respect to benchmark datasets, evaluation methods, and defense strategies.
Less is more: Embracing sparsity and interpolation with Esiformer for time series forecasting
Oct 08, 2024Time series forecasting has played a significant role in many practical fields. But time series data generated from real-world applications always exhibits high variance and lots of noise, which makes it difficult to capture the inherent periodic patterns of the data, hurting the prediction accuracy significantly. To address this issue, we propose the Esiformer, which apply interpolation on the original data, decreasing the overall variance of the data and alleviating the influence of noise. What's more, we enhanced the vanilla transformer with a robust Sparse FFN. It can enhance the representation ability of the model effectively, and maintain the excellent robustness, avoiding the risk of overfitting compared with the vanilla implementation. Through evaluations on challenging real-world datasets, our method outperforms leading model PatchTST, reducing MSE by 6.5% and MAE by 5.8% in multivariate time series forecasting. Code is available at: https://github.com/yyg1282142265/Esiformer/tree/main.
A Distance Similarity-based Genetic Optimization Algorithm for Satellite Ground Network Planning Considering Feeding Mode
Aug 29, 2024

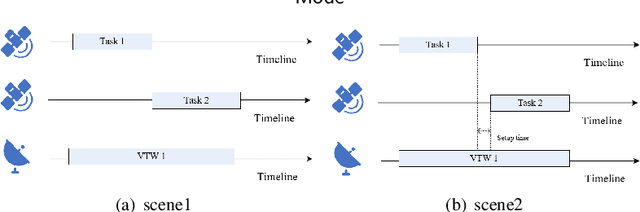
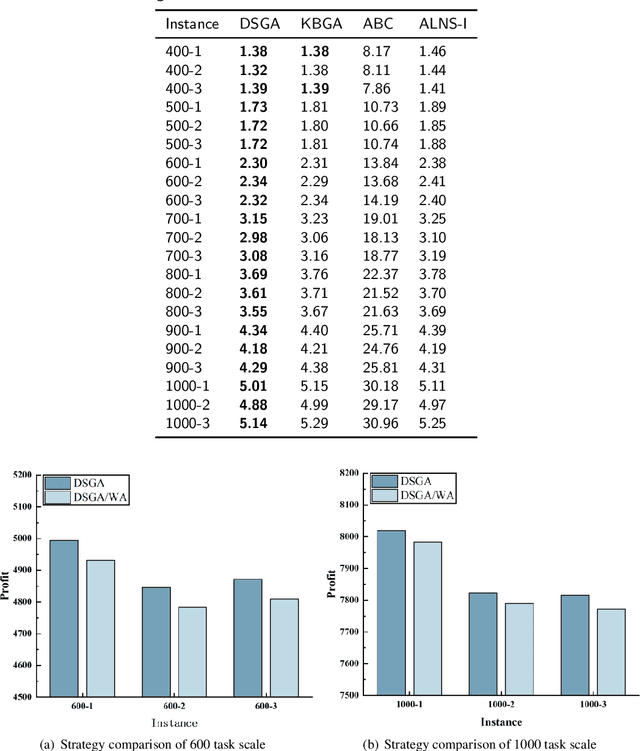
With the rapid development of the satellite industry, the information transmission network based on communication satellites has gradually become a major and important part of the future satellite ground integration network. However, the low transmission efficiency of the satellite data relay back mission has become a problem that is currently constraining the construction of the system and needs to be solved urgently. Effectively planning the task of satellite ground networking by reasonably scheduling resources is crucial for the efficient transmission of task data. In this paper, we hope to provide a task execution scheme that maximizes the profit of the networking task for satellite ground network planning considering feeding mode (SGNPFM). To solve the SGNPFM problem, a mixed-integer planning model with the objective of maximizing the gain of the link-building task is constructed, which considers various constraints of the satellite in the feed-switching mode. Based on the problem characteristics, we propose a distance similarity-based genetic optimization algorithm (DSGA), which considers the state characteristics between the tasks and introduces a weighted Euclidean distance method to determine the similarity between the tasks. To obtain more high-quality solutions, different similarity evaluation methods are designed to assist the algorithm in intelligently screening individuals. The DSGA also uses an adaptive crossover strategy based on similarity mechanism, which guides the algorithm to achieve efficient population search. In addition, a task scheduling algorithm considering the feed-switching mode is designed for decoding the algorithm to generate a high-quality scheme. The results of simulation experiments show that the DSGA can effectively solve the SGNPFM problem.