 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidLBEval: Benchmarking and Mitigating Language Bias in Video-Involved LVLMs
Paper and Code
Feb 23, 2025
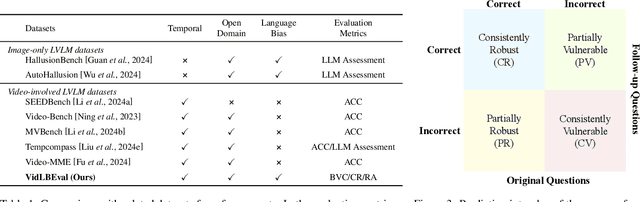
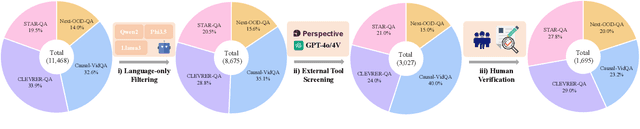
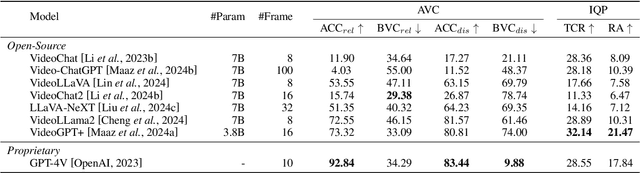
Recently, Large Vision-Language Models (LVLMs) have made significant strides across diverse multimodal tasks and benchmarks. This paper reveals a largely under-explored problem from existing video-involved LVLMs - language bias, where models tend to prioritize language over video and thus result in incorrect responses. To address this research gap, we first collect a Video Language Bias Evaluation Benchmark, which is specifically designed to assess the language bias in video-involved LVLMs through two key tasks: ambiguous video contrast and interrogative question probing. Accordingly, we design accompanied evaluation metrics that aim to penalize LVLMs being biased by language. In addition, we also propose Multi-branch Contrastive Decoding (MCD), introducing two expert branches to simultaneously counteract language bias potentially generated by the amateur text-only branch. Our experiments demonstrate that i) existing video-involved LVLMs, including both proprietary and open-sourced, are largely limited by the language bias problem; ii) our MCD can effectively mitigate this issue and maintain general-purpose capabilities in various video-involved LVLMs without any additional retraining or alteration to model architectures.