 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Vision-Language Social Bias Removal for CLIP
Paper and Code
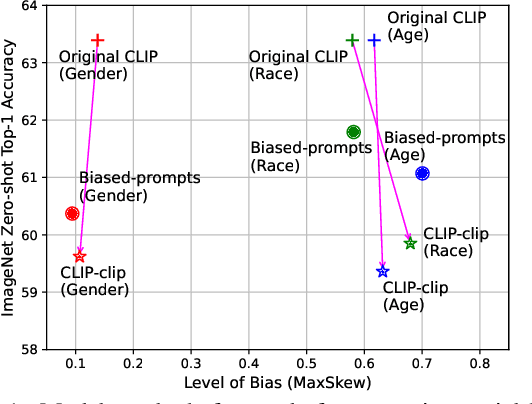
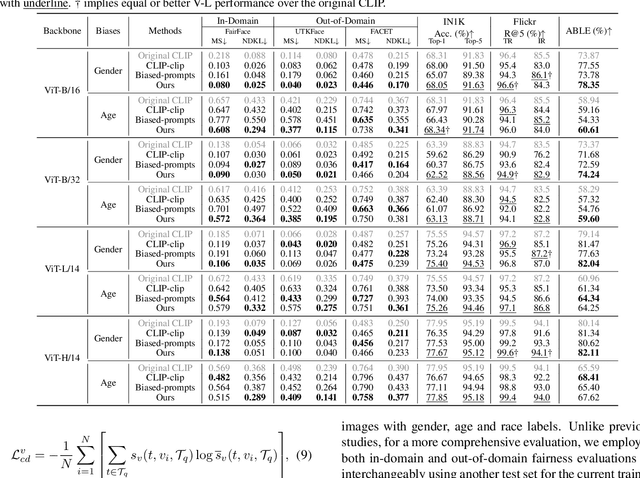
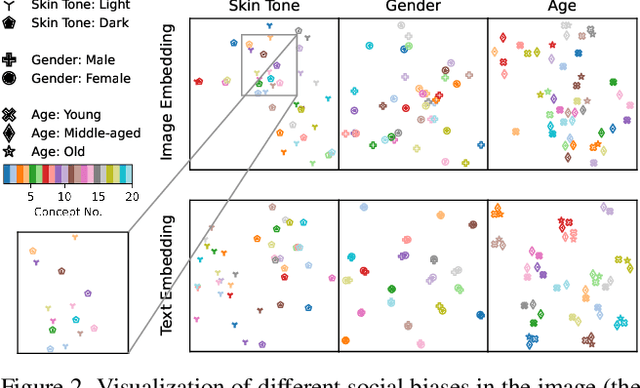
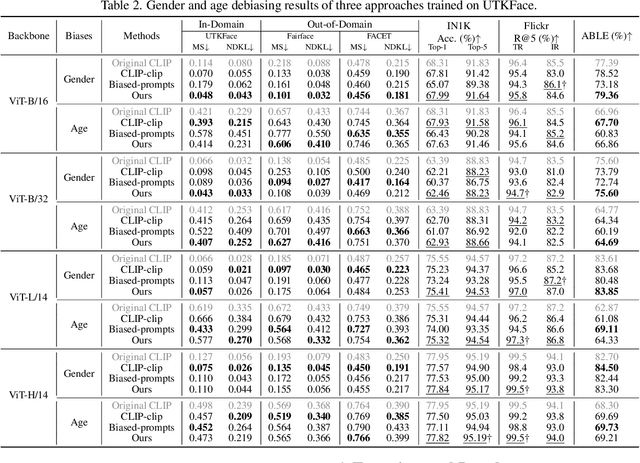
Vision-Language (V-L) pre-trained models such as CLIP show prominent capabilities in various downstream tasks. Despite this promise, V-L models are notoriously limited by their inherent social biases. A typical demonstration is that V-L models often produce biased predictions against specific groups of people, significantly undermining their real-world applicability. Existing approaches endeavor to mitigate the social bias problem in V-L models by removing biased attribute information from model embeddings. However, after our revisiting of these methods, we find that their bias removal is frequently accompanied by greatly compromised V-L alignment capabilities. We then reveal that this performance degradation stems from the unbalanced debiasing in image and text embeddings. To address this issue, we propose a novel V-L debiasing framework to align image and text biases followed by removing them from both modalities. By doing so, our method achieves multi-modal bias mitigation while maintaining the V-L alignment in the debiased embeddings. Additionally, we advocate a new evaluation protocol that can 1) holistically quantify the model debiasing and V-L alignment ability, and 2) evaluate the generalization of social bias removal models. We believe this work will offer new insights and guidance for future studies addressing the social bias problem in CLIP.