 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidHal: Benchmarking Temporal Hallucinations in Vision LLMs
Nov 25, 2024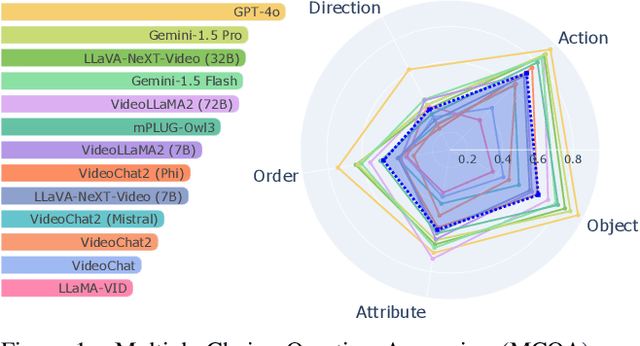
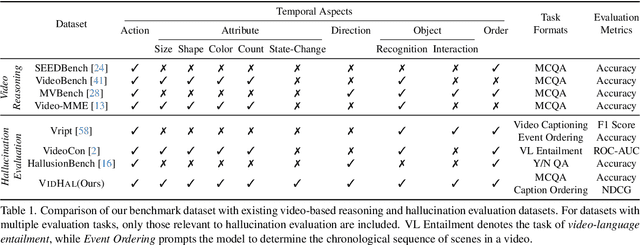
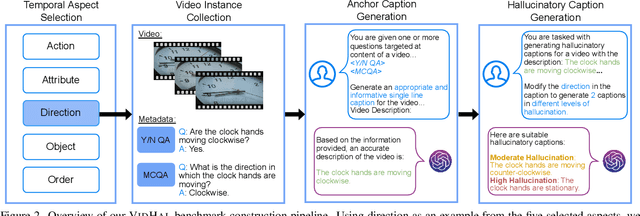
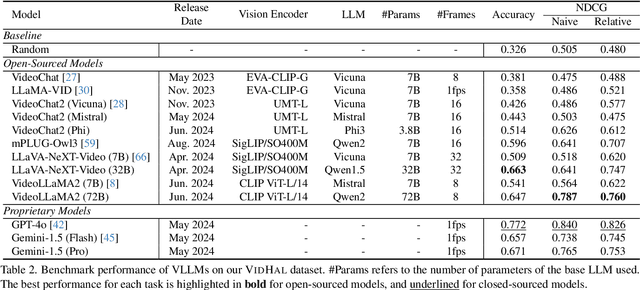
Vision Large Language Models (VLLMs) are widely acknowledged to be prone to hallucination. Existing research addressing this problem has primarily been confined to image inputs, with limited exploration of video-based hallucinations. Furthermore, current evaluation methods fail to capture nuanced errors in generated responses, which are often exacerbated by the rich spatiotemporal dynamics of videos. To address this, we introduce VidHal, a benchmark specially designed to evaluate video-based hallucinations in VLLMs. VidHal is constructed by bootstrapping video instances across common temporal aspects. A defining feature of our benchmark lies in the careful creation of captions which represent varying levels of hallucination associated with each video. To enable fine-grained evaluation, we propose a novel caption ordering task requiring VLLMs to rank captions by hallucinatory extent. We conduct extensive experiments on VidHal and comprehensively evaluate a broad selection of models. Our results uncover significant limitations in existing VLLMs regarding hallucination generation. Through our benchmark, we aim to inspire further research on 1) holistic understanding of VLLM capabilities, particularly regarding hallucination, and 2) extensive development of advanced VLLMs to alleviate this problem.