 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report for ICML 2024 TiFA Workshop MLLM Attack Challenge: Suffix Injection and Projected Gradient Descent Can Easily Fool An MLLM
Dec 20, 2024


This technical report introduces our top-ranked solution that employs two approaches, \ie suffix injection and projected gradient descent (PGD) , to address the TiFA workshop MLLM attack challenge. Specifically, we first append the text from an incorrectly labeled option (pseudo-labeled) to the original query as a suffix. Using this modified query, our second approach applies the PGD method to add imperceptible perturbations to the image. Combining these two techniques enables successful attacks on the LLaVA 1.5 model.
Privacy-Preserving Low-Rank Adaptation for Latent Diffusion Models
Feb 19, 2024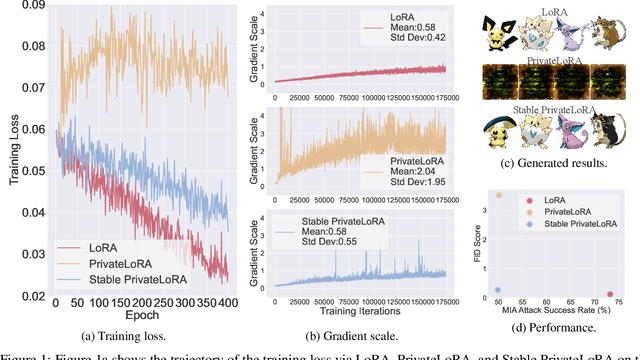
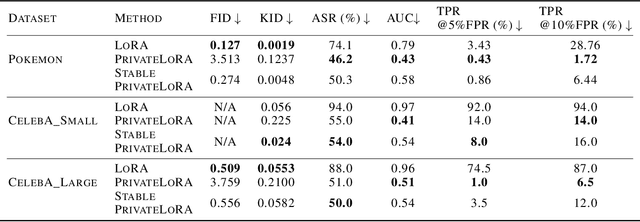
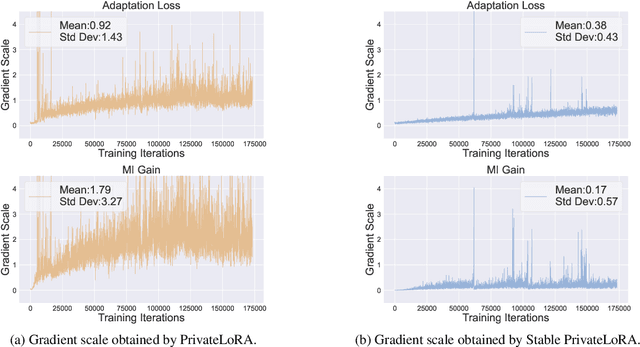
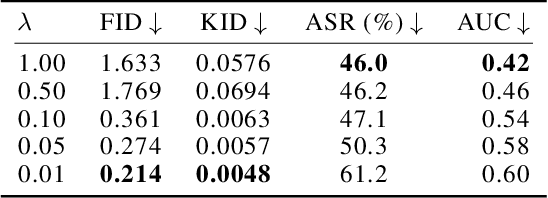
Low-rank adaptation (LoRA) is an efficient strategy for adapting latent diffusion models (LDMs) on a training dataset to generate specific objects by minimizing the adaptation loss. However, adapted LDMs via LoRA are vulnerable to membership inference (MI) attacks that can judge whether a particular data point belongs to private training datasets, thus facing severe risks of privacy leakage. To defend against MI attacks, we make the first effort to propose a straightforward solution: privacy-preserving LoRA (PrivateLoRA). PrivateLoRA is formulated as a min-max optimization problem where a proxy attack model is trained by maximizing its MI gain while the LDM is adapted by minimizing the sum of the adaptation loss and the proxy attack model's MI gain. However, we empirically disclose that PrivateLoRA has the issue of unstable optimization due to the large fluctuation of the gradient scale which impedes adaptation. To mitigate this issue, we propose Stable PrivateLoRA that adapts the LDM by minimizing the ratio of the adaptation loss to the MI gain, which implicitly rescales the gradient and thus stabilizes the optimization. Our comprehensive empirical results corroborate that adapted LDMs via Stable PrivateLoRA can effectively defend against MI attacks while generating high-quality images. Our code is available at https://github.com/WilliamLUO0/StablePrivateLoRA.
AutoLoRa: A Parameter-Free Automated Robust Fine-Tuning Framework
Oct 03, 2023Robust Fine-Tuning (RFT) is a low-cost strategy to obtain adversarial robustness in downstream applications, without requiring a lot of computational resources and collecting significant amounts of data. This paper uncovers an issue with the existing RFT, where optimizing both adversarial and natural objectives through the feature extractor (FE) yields significantly divergent gradient directions. This divergence introduces instability in the optimization process, thereby hindering the attainment of adversarial robustness and rendering RFT highly sensitive to hyperparameters. To mitigate this issue, we propose a low-rank (LoRa) branch that disentangles RFT into two distinct components: optimizing natural objectives via the LoRa branch and adversarial objectives via the FE. Besides, we introduce heuristic strategies for automating the scheduling of the learning rate and the scalars of loss terms. Extensive empirical evaluations demonstrate that our proposed automated RFT disentangled via the LoRa branch (AutoLoRa) achieves new state-of-the-art results across a range of downstream tasks. AutoLoRa holds significant practical utility, as it automatically converts a pre-trained FE into an adversarially robust model for downstream tasks without the need for searching hyperparameters.
Enhancing Adversarial Contrastive Learning via Adversarial Invariant Regularization
Apr 30, 2023



Adversarial contrastive learning (ACL), without requiring labels, incorporates adversarial data with standard contrastive learning (SCL) and outputs a robust representation which is generalizable and resistant to adversarial attacks and common corruptions. The style-independence property of representations has been validated to be beneficial in improving robustness transferability. Standard invariant regularization (SIR) has been proposed to make the learned representations via SCL to be independent of the style factors. However, how to equip robust representations learned via ACL with the style-independence property is still unclear so far. To this end, we leverage the technique of causal reasoning to propose an adversarial invariant regularization (AIR) that enforces robust representations learned via ACL to be style-independent. Then, we enhance ACL using invariant regularization (IR), which is a weighted sum of SIR and AIR. Theoretically, we show that AIR implicitly encourages the prediction of adversarial data and consistency between adversarial and natural data to be independent of data augmentations. We also theoretically demonstrate that the style-independence property of robust representation learned via ACL still holds in downstream tasks, providing generalization guarantees. Empirically, our comprehensive experimental results corroborate that IR can significantly improve the performance of ACL and its variants on various datasets.
Efficient Adversarial Contrastive Learning via Robustness-Aware Coreset Selection
Feb 08, 2023



Adversarial contrastive learning (ACL) does not require expensive data annotations but outputs a robust representation that withstands adversarial attacks and also generalizes to a wide range of downstream tasks. However, ACL needs tremendous running time to generate the adversarial variants of all training data, which limits its scalability to large datasets. To speed up ACL, this paper proposes a robustness-aware coreset selection (RCS) method. RCS does not require label information and searches for an informative subset that minimizes a representational divergence, which is the distance of the representation between natural data and their virtual adversarial variants. The vanilla solution of RCS via traversing all possible subsets is computationally prohibitive. Therefore, we theoretically transform RCS into a surrogate problem of submodular maximization, of which the greedy search is an efficient solution with an optimality guarantee for the original problem. Empirically, our comprehensive results corroborate that RCS can speed up ACL by a large margin without significantly hurting the robustness and standard transferability. Notably, to the best of our knowledge, we are the first to conduct ACL efficiently on the large-scale ImageNet-1K dataset to obtain an effective robust representation via RCS.
Adversarial Attacks and Defense for Non-Parametric Two-Sample Tests
Feb 07, 2022


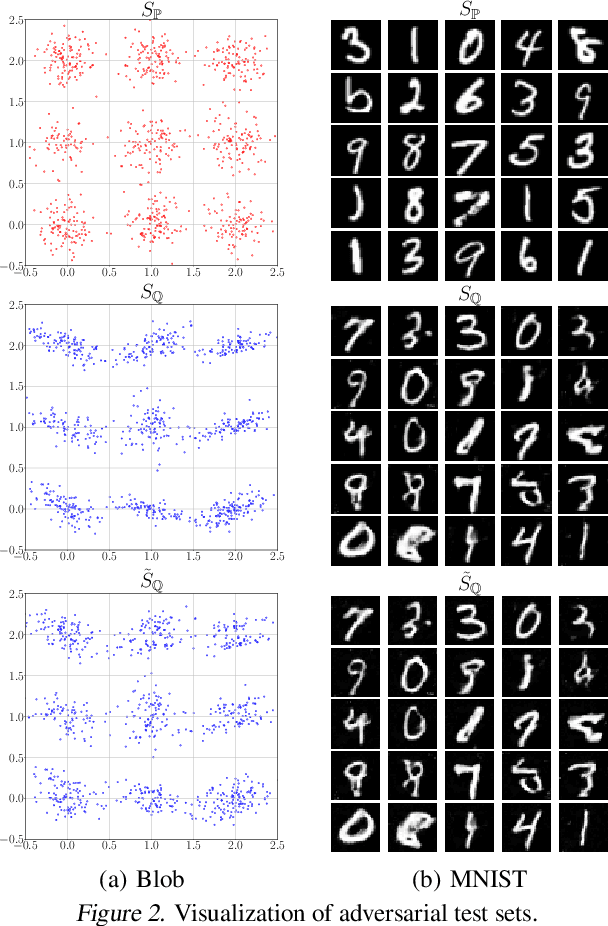
Non-parametric two-sample tests (TSTs) that judge whether two sets of samples are drawn from the same distribution, have been widely used in the analysis of critical data. People tend to employ TSTs as trusted basic tools and rarely have any doubt about their reliability. This paper systematically uncovers the failure mode of non-parametric TSTs through adversarial attacks and then proposes corresponding defense strategies. First, we theoretically show that an adversary can upper-bound the distributional shift which guarantees the attack's invisibility. Furthermore, we theoretically find that the adversary can also degrade the lower bound of a TST's test power, which enables us to iteratively minimize the test criterion in order to search for adversarial pairs. To enable TST-agnostic attacks, we propose an ensemble attack (EA) framework that jointly minimizes the different types of test criteria. Second, to robustify TSTs, we propose a max-min optimization that iteratively generates adversarial pairs to train the deep kernels. Extensive experiments on both simulated and real-world datasets validate the adversarial vulnerabilities of non-parametric TSTs and the effectiveness of our proposed defense.
NoiLIn: Do Noisy Labels Always Hurt Adversarial Training?
May 31, 2021

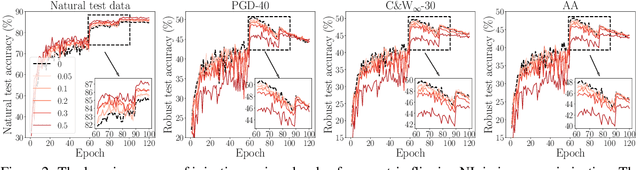

Adversarial training (AT) based on minimax optimization is a popular learning style that enhances the model's adversarial robustness. Noisy labels (NL) commonly undermine the learning and hurt the model's performance. Interestingly, both research directions hardly crossover and hit sparks. In this paper, we raise an intriguing question -- Does NL always hurt AT? Firstly, we find that NL injection in inner maximization for generating adversarial data augments natural data implicitly, which benefits AT's generalization. Secondly, we find NL injection in outer minimization for the learning serves as regularization that alleviates robust overfitting, which benefits AT's robustness. To enhance AT's adversarial robustness, we propose "NoiLIn" that gradually increases \underline{Noi}sy \underline{L}abels \underline{In}jection over the AT's training process. Empirically, NoiLIn answers the previous question negatively -- the adversarial robustness can be indeed enhanced by NL injection. Philosophically, we provide a new perspective of the learning with NL: NL should not always be deemed detrimental, and even in the absence of NL in the training set, we may consider injecting it deliberately.
Guided Interpolation for Adversarial Training
Feb 15, 2021

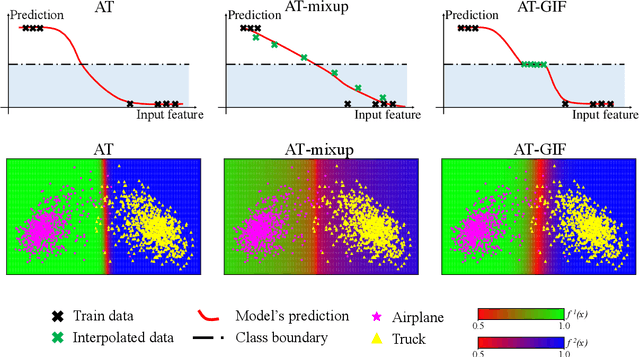

To enhance adversarial robustness, adversarial training learns deep neural networks on the adversarial variants generated by their natural data. However, as the training progresses, the training data becomes less and less attackable, undermining the robustness enhancement. A straightforward remedy is to incorporate more training data, but sometimes incurring an unaffordable cost. In this paper, to mitigate this issue, we propose the guided interpolation framework (GIF): in each epoch, the GIF employs the previous epoch's meta information to guide the data's interpolation. Compared with the vanilla mixup, the GIF can provide a higher ratio of attackable data, which is beneficial to the robustness enhancement; it meanwhile mitigates the model's linear behavior between classes, where the linear behavior is favorable to generalization but not to the robustness. As a result, the GIF encourages the model to predict invariantly in the cluster of each class. Experiments demonstrate that the GIF can indeed enhance adversarial robustness on various adversarial training methods and various datasets.
Attacks Which Do Not Kill Training Make Adversarial Learning Stronger
Feb 26, 2020
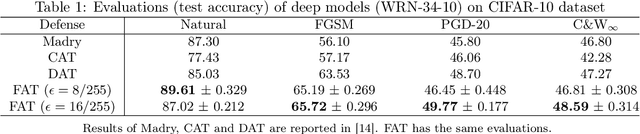


Adversarial training based on the minimax formulation is necessary for obtaining adversarial robustness of trained models. However, it is conservative or even pessimistic so that it sometimes hurts the natural generalization. In this paper, we raise a fundamental question---do we have to trade off natural generalization for adversarial robustness? We argue that adversarial training is to employ confident adversarial data for updating the current model. We propose a novel approach of friendly adversarial training (FAT): rather than employing most adversarial data maximizing the loss, we search for least adversarial (i.e., friendly adversarial) data minimizing the loss, among the adversarial data that are confidently misclassified. Our novel formulation is easy to implement by just stopping the most adversarial data searching algorithms such as PGD (projected gradient descent) early, which we call early-stopped PGD. Theoretically, FAT is justified by an upper bound of the adversarial risk. Empirically, early-stopped PGD allows us to answer the earlier question negatively---adversarial robustness can indeed be achieved without compromising the natural generalization.