 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCAN: Bootstrapping Contrastive Pre-training for Data Efficiency
Paper and Code
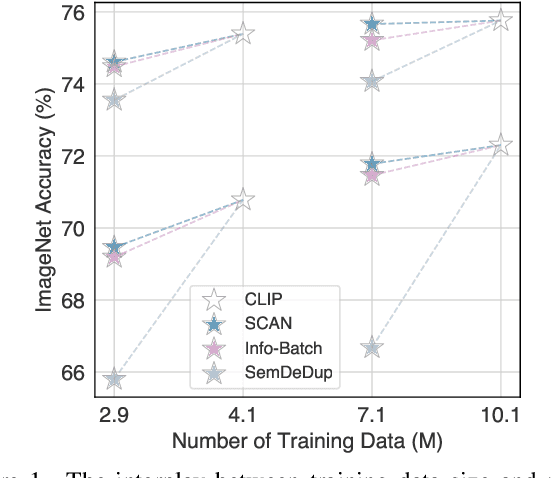
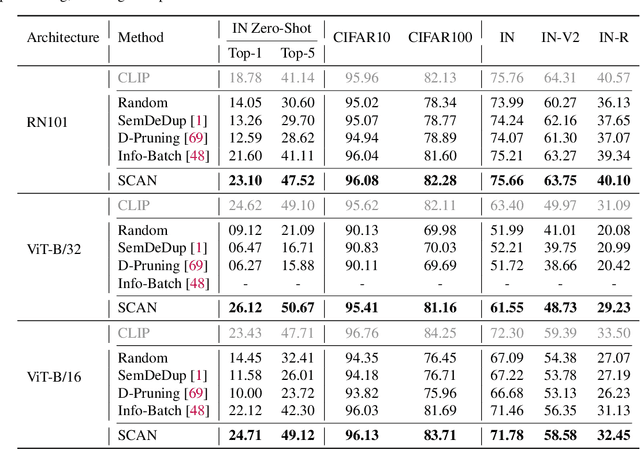
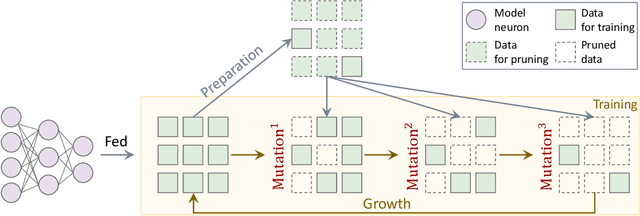
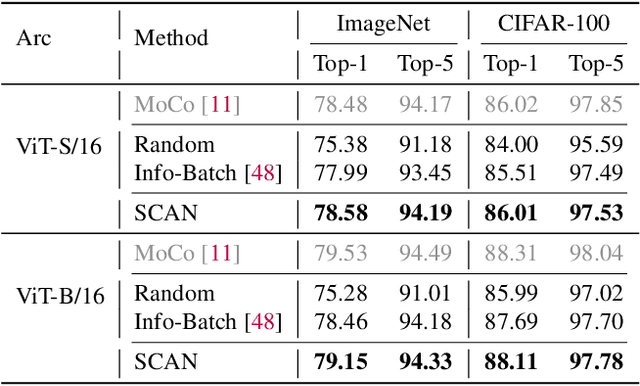
While contrastive pre-training is widely employed, its data efficiency problem has remained relatively under-explored thus far. Existing methods often rely on static coreset selection algorithms to pre-identify important data for training. However, this static nature renders them unable to dynamically track the data usefulness throughout pre-training, leading to subpar pre-trained models. To address this challenge, our paper introduces a novel dynamic bootstrapping dataset pruning method. It involves pruning data preparation followed by dataset mutation operations, both of which undergo iterative and dynamic updates. We apply this method to two prevalent contrastive pre-training frameworks: \textbf{CLIP} and \textbf{MoCo}, representing vision-language and vision-centric domains, respectively. In particular, we individually pre-train seven CLIP models on two large-scale image-text pair datasets, and two MoCo models on the ImageNet dataset, resulting in a total of 16 pre-trained models. With a data pruning rate of 30-35\% across all 16 models, our method exhibits only marginal performance degradation (less than \textbf{1\%} on average) compared to corresponding models trained on the full dataset counterparts across various downstream datasets, and also surpasses several baselines with a large performance margin. Additionally, the byproduct from our method, \ie coresets derived from the original datasets after pre-training, also demonstrates significant superiority in terms of downstream performance over other static coreset selection approaches.