 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Deepfake Detection via Real Distribution Bias Correction
Mar 14, 2026To generalize deepfake detectors to future unseen forgeries, most existing methods attempt to simulate the dynamically evolving forgery types using available source domain data. However, predicting an unbounded set of future manipulations from limited prior examples is infeasible. To overcome this limitation, we propose to exploit the invariance of \textbf{real data} from two complementary perspectives: the fixed population distribution of the entire real class and the inherent Gaussianity of individual real images. Building on these properties, we introduce the Real Distribution Bias Correction (RDBC) framework, which consists of two key components: the Real Population Distribution Estimation module and the Distribution-Sampled Feature Whitening module. The former utilizes the independent and identically distributed (\iid) property of real samples to derive the normal distribution form of their statistics, from which the distribution parameters can be estimated using limited source domain data. Based on the learned population distribution, the latter utilizes the inherent Gaussianity of real data as a discriminative prior and performs a sampling-based whitening operation to amplify the Gaussianity gap between real and fake samples. Through synergistic coupling of the two modules, our model captures the real-world properties of real samples, thereby enhancing its generalizability to unseen target domains. Extensive experiments demonstrate that RDBC achieves state-of-the-art performance in both in-domain and cross-domain deepfake detection.
Multimodal Fact-Checking: An Agent-based Approach
Dec 31, 2025The rapid spread of multimodal misinformation poses a growing challenge for automated fact-checking systems. Existing approaches, including large vision language models (LVLMs) and deep multimodal fusion methods, often fall short due to limited reasoning and shallow evidence utilization. A key bottleneck is the lack of dedicated datasets that provide complete real-world multimodal misinformation instances accompanied by annotated reasoning processes and verifiable evidence. To address this limitation, we introduce RW-Post, a high-quality and explainable dataset for real-world multimodal fact-checking. RW-Post aligns real-world multimodal claims with their original social media posts, preserving the rich contextual information in which the claims are made. In addition, the dataset includes detailed reasoning and explicitly linked evidence, which are derived from human written fact-checking articles via a large language model assisted extraction pipeline, enabling comprehensive verification and explanation. Building upon RW-Post, we propose AgentFact, an agent-based multimodal fact-checking framework designed to emulate the human verification workflow. AgentFact consists of five specialized agents that collaboratively handle key fact-checking subtasks, including strategy planning, high-quality evidence retrieval, visual analysis, reasoning, and explanation generation. These agents are orchestrated through an iterative workflow that alternates between evidence searching and task-aware evidence filtering and reasoning, facilitating strategic decision-making and systematic evidence analysis. Extensive experimental results demonstrate that the synergy between RW-Post and AgentFact substantially improves both the accuracy and interpretability of multimodal fact-checking.
Fair Deepfake Detectors Can Generalize
Jul 03, 2025Deepfake detection models face two critical challenges: generalization to unseen manipulations and demographic fairness among population groups. However, existing approaches often demonstrate that these two objectives are inherently conflicting, revealing a trade-off between them. In this paper, we, for the first time, uncover and formally define a causal relationship between fairness and generalization. Building on the back-door adjustment, we show that controlling for confounders (data distribution and model capacity) enables improved generalization via fairness interventions. Motivated by this insight, we propose Demographic Attribute-insensitive Intervention Detection (DAID), a plug-and-play framework composed of: i) Demographic-aware data rebalancing, which employs inverse-propensity weighting and subgroup-wise feature normalization to neutralize distributional biases; and ii) Demographic-agnostic feature aggregation, which uses a novel alignment loss to suppress sensitive-attribute signals. Across three cross-domain benchmarks, DAID consistently achieves superior performance in both fairness and generalization compared to several state-of-the-art detectors, validating both its theoretical foundation and practical effectiveness.
Learning Real Facial Concepts for Independent Deepfake Detection
May 07, 2025Deepfake detection models often struggle with generalization to unseen datasets, manifesting as misclassifying real instances as fake in target domains. This is primarily due to an overreliance on forgery artifacts and a limited understanding of real faces. To address this challenge, we propose a novel approach RealID to enhance generalization by learning a comprehensive concept of real faces while assessing the probabilities of belonging to the real and fake classes independently. RealID comprises two key modules: the Real Concept Capture Module (RealC2) and the Independent Dual-Decision Classifier (IDC). With the assistance of a MultiReal Memory, RealC2 maintains various prototypes for real faces, allowing the model to capture a comprehensive concept of real class. Meanwhile, IDC redefines the classification strategy by making independent decisions based on the concept of the real class and the presence of forgery artifacts. Through the combined effect of the above modules, the influence of forgery-irrelevant patterns is alleviated, and extensive experiments on five widely used datasets demonstrate that RealID significantly outperforms existing state-of-the-art methods, achieving a 1.74% improvement in average accuracy.
FractalForensics: Proactive Deepfake Detection and Localization via Fractal Watermarks
Apr 13, 2025Proactive Deepfake detection via robust watermarks has been raised ever since passive Deepfake detectors encountered challenges in identifying high-quality synthetic images. However, while demonstrating reasonable detection performance, they lack localization functionality and explainability in detection results. Additionally, the unstable robustness of watermarks can significantly affect the detection performance accordingly. In this study, we propose novel fractal watermarks for proactive Deepfake detection and localization, namely FractalForensics. Benefiting from the characteristics of fractals, we devise a parameter-driven watermark generation pipeline that derives fractal-based watermarks and conducts one-way encryption regarding the parameters selected. Subsequently, we propose a semi-fragile watermarking framework for watermark embedding and recovery, trained to be robust against benign image processing operations and fragile when facing Deepfake manipulations in a black-box setting. Meanwhile, we introduce an entry-to-patch strategy that implicitly embeds the watermark matrix entries into image patches at corresponding positions, achieving localization of Deepfake manipulations. Extensive experiments demonstrate satisfactory robustness and fragility of our approach against common image processing operations and Deepfake manipulations, outperforming state-of-the-art semi-fragile watermarking algorithms and passive detectors for Deepfake detection. Furthermore, by highlighting the areas manipulated, our method provides explainability for the proactive Deepfake detection results.
NullSwap: Proactive Identity Cloaking Against Deepfake Face Swapping
Mar 24, 2025Suffering from performance bottlenecks in passively detecting high-quality Deepfake images due to the advancement of generative models, proactive perturbations offer a promising approach to disabling Deepfake manipulations by inserting signals into benign images. However, existing proactive perturbation approaches remain unsatisfactory in several aspects: 1) visual degradation due to direct element-wise addition; 2) limited effectiveness against face swapping manipulation; 3) unavoidable reliance on white- and grey-box settings to involve generative models during training. In this study, we analyze the essence of Deepfake face swapping and argue the necessity of protecting source identities rather than target images, and we propose NullSwap, a novel proactive defense approach that cloaks source image identities and nullifies face swapping under a pure black-box scenario. We design an Identity Extraction module to obtain facial identity features from the source image, while a Perturbation Block is then devised to generate identity-guided perturbations accordingly. Meanwhile, a Feature Block extracts shallow-level image features, which are then fused with the perturbation in the Cloaking Block for image reconstruction. Furthermore, to ensure adaptability across different identity extractors in face swapping algorithms, we propose Dynamic Loss Weighting to adaptively balance identity losses. Experiments demonstrate the outstanding ability of our approach to fool various identity recognition models, outperforming state-of-the-art proactive perturbations in preventing face swapping models from generating images with correct source identities.
LampMark: Proactive Deepfake Detection via Training-Free Landmark Perceptual Watermarks
Nov 26, 2024


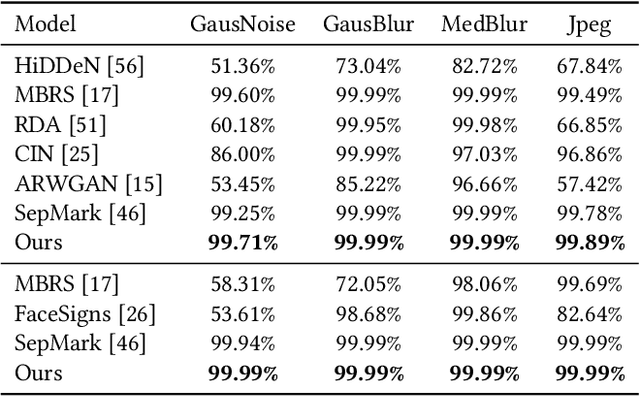
Deepfake facial manipulation has garnered significant public attention due to its impacts on enhancing human experiences and posing privacy threats. Despite numerous passive algorithms that have been attempted to thwart malicious Deepfake attacks, they mostly struggle with the generalizability challenge when confronted with hyper-realistic synthetic facial images. To tackle the problem, this paper proposes a proactive Deepfake detection approach by introducing a novel training-free landmark perceptual watermark, LampMark for short. We first analyze the structure-sensitive characteristics of Deepfake manipulations and devise a secure and confidential transformation pipeline from the structural representations, i.e. facial landmarks, to binary landmark perceptual watermarks. Subsequently, we present an end-to-end watermarking framework that imperceptibly and robustly embeds and extracts watermarks concerning the images to be protected. Relying on promising watermark recovery accuracies, Deepfake detection is accomplished by assessing the consistency between the content-matched landmark perceptual watermark and the robustly recovered watermark of the suspect image. Experimental results demonstrate the superior performance of our approach in watermark recovery and Deepfake detection compared to state-of-the-art methods across in-dataset, cross-dataset, and cross-manipulation scenarios.
Social Debiasing for Fair Multi-modal LLMs
Aug 13, 2024Multi-modal Large Language Models (MLLMs) have advanced significantly, offering powerful vision-language understanding capabilities. However, these models often inherit severe social biases from their training datasets, leading to unfair predictions based on attributes like race and gender. This paper addresses the issue of social biases in MLLMs by i) Introducing a comprehensive Counterfactual dataset with Multiple Social Concepts (CMSC), which provides a more diverse and extensive training set compared to existing datasets. ii) Proposing an Anti-Stereotype Debiasing strategy (ASD). Our method works by revisiting the MLLM training process, rescaling the autoregressive loss function, and improving data sampling methods to counteract biases. Through extensive experiments on various MLLMs, our CMSC dataset and ASD method demonstrate a significant reduction in social biases while maintaining the models' original performance.
Bridging the Intent Gap: Knowledge-Enhanced Visual Generation
May 21, 2024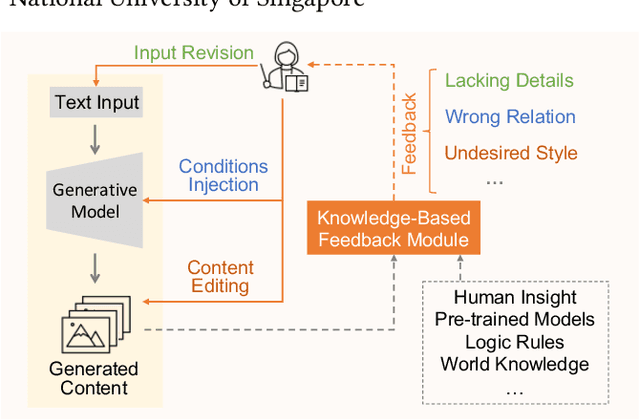
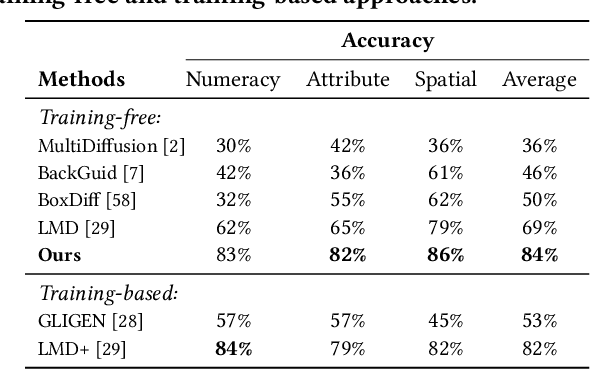
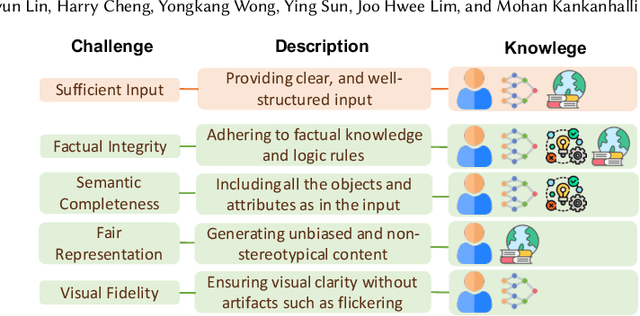
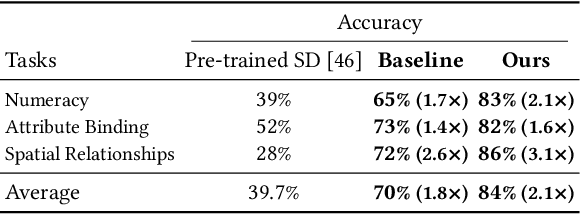
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.
LOC-ZSON: Language-driven Object-Centric Zero-Shot Object Retrieval and Navigation
May 08, 2024



In this paper, we present LOC-ZSON, a novel Language-driven Object-Centric image representation for object navigation task within complex scenes. We propose an object-centric image representation and corresponding losses for visual-language model (VLM) fine-tuning, which can handle complex object-level queries. In addition, we design a novel LLM-based augmentation and prompt templates for stability during training and zero-shot inference. We implement our method on Astro robot and deploy it in both simulated and real-world environments for zero-shot object navigation. We show that our proposed method can achieve an improvement of 1.38 - 13.38% in terms of text-to-image recall on different benchmark settings for the retrieval task. For object navigation, we show the benefit of our approach in simulation and real world, showing 5% and 16.67% improvement in terms of navigation success rate, respectively.