 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatialV2A: Visual-Guided High-fidelity Spatial Audio Generation
Jan 21, 2026While video-to-audio generation has achieved remarkable progress in semantic and temporal alignment, most existing studies focus solely on these aspects, paying limited attention to the spatial perception and immersive quality of the synthesized audio. This limitation stems largely from current models' reliance on mono audio datasets, which lack the binaural spatial information needed to learn visual-to-spatial audio mappings. To address this gap, we introduce two key contributions: we construct BinauralVGGSound, the first large-scale video-binaural audio dataset designed to support spatially aware video-to-audio generation; and we propose a end-to-end spatial audio generation framework guided by visual cues, which explicitly models spatial features. Our framework incorporates a visual-guided audio spatialization module that ensures the generated audio exhibits realistic spatial attributes and layered spatial depth while maintaining semantic and temporal alignment. Experiments show that our approach substantially outperforms state-of-the-art models in spatial fidelity and delivers a more immersive auditory experience, without sacrificing temporal or semantic consistency. All datasets, code, and model checkpoints will be publicly released to facilitate future research.
BMRL: Bi-Modal Guided Multi-Perspective Representation Learning for Zero-Shot Deepfake Attribution
Apr 19, 2025The challenge of tracing the source attribution of forged faces has gained significant attention due to the rapid advancement of generative models. However, existing deepfake attribution (DFA) works primarily focus on the interaction among various domains in vision modality, and other modalities such as texts and face parsing are not fully explored. Besides, they tend to fail to assess the generalization performance of deepfake attributors to unseen generators in a fine-grained manner. In this paper, we propose a novel bi-modal guided multi-perspective representation learning (BMRL) framework for zero-shot deepfake attribution (ZS-DFA), which facilitates effective traceability to unseen generators. Specifically, we design a multi-perspective visual encoder (MPVE) to explore general deepfake attribution visual characteristics across three views (i.e., image, noise, and edge). We devise a novel parsing encoder to focus on global face attribute embeddings, enabling parsing-guided DFA representation learning via vision-parsing matching. A language encoder is proposed to capture fine-grained language embeddings, facilitating language-guided general visual forgery representation learning through vision-language alignment. Additionally, we present a novel deepfake attribution contrastive center (DFACC) loss, to pull relevant generators closer and push irrelevant ones away, which can be introduced into DFA models to enhance traceability. Experimental results demonstrate that our method outperforms the state-of-the-art on the ZS-DFA task through various protocols evaluation.
Preview-based Category Contrastive Learning for Knowledge Distillation
Oct 18, 2024Knowledge distillation is a mainstream algorithm in model compression by transferring knowledge from the larger model (teacher) to the smaller model (student) to improve the performance of student. Despite many efforts, existing methods mainly investigate the consistency between instance-level feature representation or prediction, which neglects the category-level information and the difficulty of each sample, leading to undesirable performance. To address these issues, we propose a novel preview-based category contrastive learning method for knowledge distillation (PCKD). It first distills the structural knowledge of both instance-level feature correspondence and the relation between instance features and category centers in a contrastive learning fashion, which can explicitly optimize the category representation and explore the distinct correlation between representations of instances and categories, contributing to discriminative category centers and better classification results. Besides, we introduce a novel preview strategy to dynamically determine how much the student should learn from each sample according to their difficulty. Different from existing methods that treat all samples equally and curriculum learning that simply filters out hard samples, our method assigns a small weight for hard instances as a preview to better guide the student training. Extensive experiments on several challenging datasets, including CIFAR-100 and ImageNet, demonstrate the superiority over state-of-the-art methods.
Social Debiasing for Fair Multi-modal LLMs
Aug 13, 2024Multi-modal Large Language Models (MLLMs) have advanced significantly, offering powerful vision-language understanding capabilities. However, these models often inherit severe social biases from their training datasets, leading to unfair predictions based on attributes like race and gender. This paper addresses the issue of social biases in MLLMs by i) Introducing a comprehensive Counterfactual dataset with Multiple Social Concepts (CMSC), which provides a more diverse and extensive training set compared to existing datasets. ii) Proposing an Anti-Stereotype Debiasing strategy (ASD). Our method works by revisiting the MLLM training process, rescaling the autoregressive loss function, and improving data sampling methods to counteract biases. Through extensive experiments on various MLLMs, our CMSC dataset and ASD method demonstrate a significant reduction in social biases while maintaining the models' original performance.
SHE-Net: Syntax-Hierarchy-Enhanced Text-Video Retrieval
Apr 22, 2024The user base of short video apps has experienced unprecedented growth in recent years, resulting in a significant demand for video content analysis. In particular, text-video retrieval, which aims to find the top matching videos given text descriptions from a vast video corpus, is an essential function, the primary challenge of which is to bridge the modality gap. Nevertheless, most existing approaches treat texts merely as discrete tokens and neglect their syntax structures. Moreover, the abundant spatial and temporal clues in videos are often underutilized due to the lack of interaction with text. To address these issues, we argue that using texts as guidance to focus on relevant temporal frames and spatial regions within videos is beneficial. In this paper, we propose a novel Syntax-Hierarchy-Enhanced text-video retrieval method (SHE-Net) that exploits the inherent semantic and syntax hierarchy of texts to bridge the modality gap from two perspectives. First, to facilitate a more fine-grained integration of visual content, we employ the text syntax hierarchy, which reveals the grammatical structure of text descriptions, to guide the visual representations. Second, to further enhance the multi-modal interaction and alignment, we also utilize the syntax hierarchy to guide the similarity calculation. We evaluated our method on four public text-video retrieval datasets of MSR-VTT, MSVD, DiDeMo, and ActivityNet. The experimental results and ablation studies confirm the advantages of our proposed method.
SNP-S3: Shared Network Pre-training and Significant Semantic Strengthening for Various Video-Text Tasks
Jan 31, 2024We present a framework for learning cross-modal video representations by directly pre-training on raw data to facilitate various downstream video-text tasks. Our main contributions lie in the pre-training framework and proxy tasks. First, based on the shortcomings of two mainstream pixel-level pre-training architectures (limited applications or less efficient), we propose Shared Network Pre-training (SNP). By employing one shared BERT-type network to refine textual and cross-modal features simultaneously, SNP is lightweight and could support various downstream applications. Second, based on the intuition that people always pay attention to several "significant words" when understanding a sentence, we propose the Significant Semantic Strengthening (S3) strategy, which includes a novel masking and matching proxy task to promote the pre-training performance. Experiments conducted on three downstream video-text tasks and six datasets demonstrate that, we establish a new state-of-the-art in pixel-level video-text pre-training; we also achieve a satisfactory balance between the pre-training efficiency and the fine-tuning performance. The codebase are available at https://github.com/alipay/Ant-Multi-Modal-Framework/tree/main/prj/snps3_vtp.
Knowledge-enhanced Multi-perspective Video Representation Learning for Scene Recognition
Jan 09, 2024With the explosive growth of video data in real-world applications, a comprehensive representation of videos becomes increasingly important. In this paper, we address the problem of video scene recognition, whose goal is to learn a high-level video representation to classify scenes in videos. Due to the diversity and complexity of video contents in realistic scenarios, this task remains a challenge. Most existing works identify scenes for videos only from visual or textual information in a temporal perspective, ignoring the valuable information hidden in single frames, while several earlier studies only recognize scenes for separate images in a non-temporal perspective. We argue that these two perspectives are both meaningful for this task and complementary to each other, meanwhile, externally introduced knowledge can also promote the comprehension of videos. We propose a novel two-stream framework to model video representations from multiple perspectives, i.e. temporal and non-temporal perspectives, and integrate the two perspectives in an end-to-end manner by self-distillation. Besides, we design a knowledge-enhanced feature fusion and label prediction method that contributes to naturally introducing knowledge into the task of video scene recognition. Experiments conducted on a real-world dataset demonstrate the effectiveness of our proposed method.
RTQ: Rethinking Video-language Understanding Based on Image-text Model
Dec 01, 2023

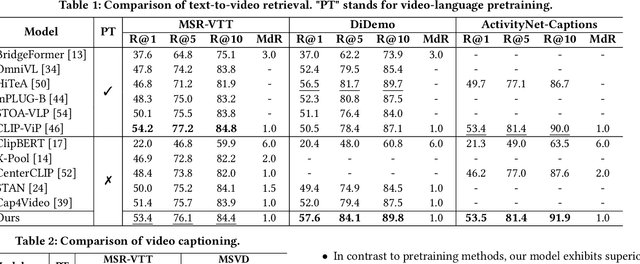
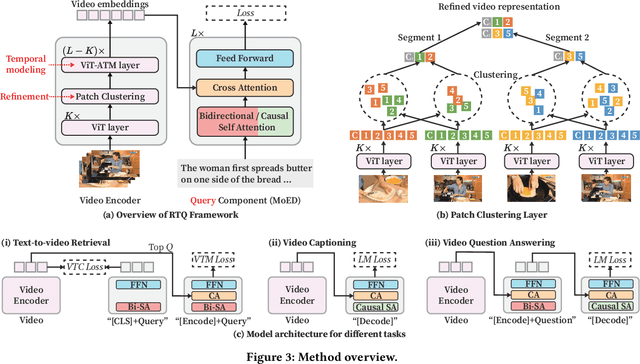
Recent advancements in video-language understanding have been established on the foundation of image-text models, resulting in promising outcomes due to the shared knowledge between images and videos. However, video-language understanding presents unique challenges due to the inclusion of highly complex semantic details, which result in information redundancy, temporal dependency, and scene complexity. Current techniques have only partially tackled these issues, and our quantitative analysis indicates that some of these methods are complementary. In light of this, we propose a novel framework called RTQ (Refine, Temporal model, and Query), which addresses these challenges simultaneously. The approach involves refining redundant information within frames, modeling temporal relations among frames, and querying task-specific information from the videos. Remarkably, our model demonstrates outstanding performance even in the absence of video-language pre-training, and the results are comparable with or superior to those achieved by state-of-the-art pre-training methods.
* Accepted by ACM MM 2023 as Oral representation
EVE: Efficient zero-shot text-based Video Editing with Depth Map Guidance and Temporal Consistency Constraints
Aug 21, 2023

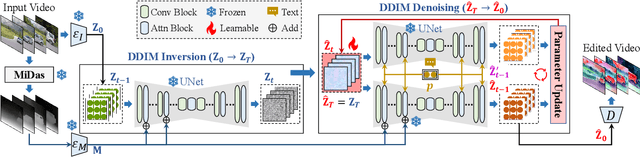

Motivated by the superior performance of image diffusion models, more and more researchers strive to extend these models to the text-based video editing task. Nevertheless, current video editing tasks mainly suffer from the dilemma between the high fine-tuning cost and the limited generation capacity. Compared with images, we conjecture that videos necessitate more constraints to preserve the temporal consistency during editing. Towards this end, we propose EVE, a robust and efficient zero-shot video editing method. Under the guidance of depth maps and temporal consistency constraints, EVE derives satisfactory video editing results with an affordable computational and time cost. Moreover, recognizing the absence of a publicly available video editing dataset for fair comparisons, we construct a new benchmark ZVE-50 dataset. Through comprehensive experimentation, we validate that EVE could achieve a satisfactory trade-off between performance and efficiency. We will release our dataset and codebase to facilitate future researchers.
Temporal Sentence Grounding in Streaming Videos
Aug 14, 2023This paper aims to tackle a novel task - Temporal Sentence Grounding in Streaming Videos (TSGSV). The goal of TSGSV is to evaluate the relevance between a video stream and a given sentence query. Unlike regular videos, streaming videos are acquired continuously from a particular source, and are always desired to be processed on-the-fly in many applications such as surveillance and live-stream analysis. Thus, TSGSV is challenging since it requires the model to infer without future frames and process long historical frames effectively, which is untouched in the early methods. To specifically address the above challenges, we propose two novel methods: (1) a TwinNet structure that enables the model to learn about upcoming events; and (2) a language-guided feature compressor that eliminates redundant visual frames and reinforces the frames that are relevant to the query. We conduct extensive experiments using ActivityNet Captions, TACoS, and MAD datasets. The results demonstrate the superiority of our proposed methods. A systematic ablation study also confirms their effectiveness.