 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTQ: Rethinking Video-language Understanding Based on Image-text Model
Paper and Code


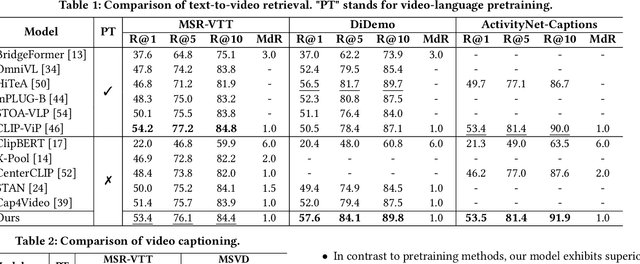
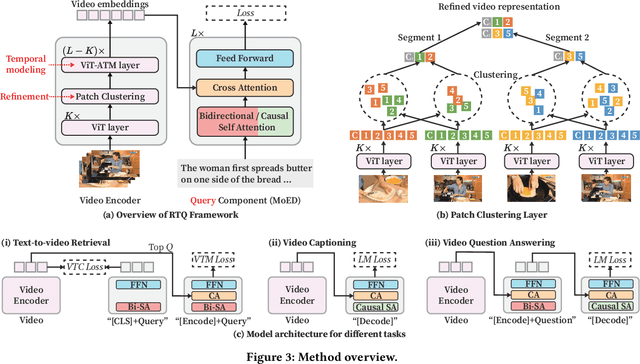
Recent advancements in video-language understanding have been established on the foundation of image-text models, resulting in promising outcomes due to the shared knowledge between images and videos. However, video-language understanding presents unique challenges due to the inclusion of highly complex semantic details, which result in information redundancy, temporal dependency, and scene complexity. Current techniques have only partially tackled these issues, and our quantitative analysis indicates that some of these methods are complementary. In light of this, we propose a novel framework called RTQ (Refine, Temporal model, and Query), which addresses these challenges simultaneously. The approach involves refining redundant information within frames, modeling temporal relations among frames, and querying task-specific information from the videos. Remarkably, our model demonstrates outstanding performance even in the absence of video-language pre-training, and the results are comparable with or superior to those achieved by state-of-the-art pre-training methods.