 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMRL: Bi-Modal Guided Multi-Perspective Representation Learning for Zero-Shot Deepfake Attribution
Apr 19, 2025The challenge of tracing the source attribution of forged faces has gained significant attention due to the rapid advancement of generative models. However, existing deepfake attribution (DFA) works primarily focus on the interaction among various domains in vision modality, and other modalities such as texts and face parsing are not fully explored. Besides, they tend to fail to assess the generalization performance of deepfake attributors to unseen generators in a fine-grained manner. In this paper, we propose a novel bi-modal guided multi-perspective representation learning (BMRL) framework for zero-shot deepfake attribution (ZS-DFA), which facilitates effective traceability to unseen generators. Specifically, we design a multi-perspective visual encoder (MPVE) to explore general deepfake attribution visual characteristics across three views (i.e., image, noise, and edge). We devise a novel parsing encoder to focus on global face attribute embeddings, enabling parsing-guided DFA representation learning via vision-parsing matching. A language encoder is proposed to capture fine-grained language embeddings, facilitating language-guided general visual forgery representation learning through vision-language alignment. Additionally, we present a novel deepfake attribution contrastive center (DFACC) loss, to pull relevant generators closer and push irrelevant ones away, which can be introduced into DFA models to enhance traceability. Experimental results demonstrate that our method outperforms the state-of-the-art on the ZS-DFA task through various protocols evaluation.
Distilled Transformers with Locally Enhanced Global Representations for Face Forgery Detection
Dec 28, 2024
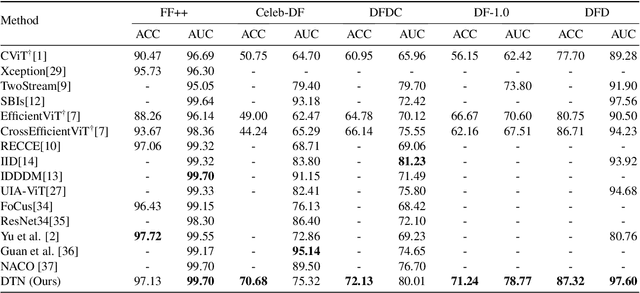


Face forgery detection (FFD) is devoted to detecting the authenticity of face images. Although current CNN-based works achieve outstanding performance in FFD, they are susceptible to capturing local forgery patterns generated by various manipulation methods. Though transformer-based detectors exhibit improvements in modeling global dependencies, they are not good at exploring local forgery artifacts. Hybrid transformer-based networks are designed to capture local and global manipulated traces, but they tend to suffer from the attention collapse issue as the transformer block goes deeper. Besides, soft labels are rarely available. In this paper, we propose a distilled transformer network (DTN) to capture both rich local and global forgery traces and learn general and common representations for different forgery faces. Specifically, we design a mixture of expert (MoE) module to mine various robust forgery embeddings. Moreover, a locally-enhanced vision transformer (LEVT) module is proposed to learn locally-enhanced global representations. We design a lightweight multi-attention scaling (MAS) module to avoid attention collapse, which can be plugged and played in any transformer-based models with only a slight increase in computational costs. In addition, we propose a deepfake self-distillation (DSD) scheme to provide the model with abundant soft label information. Extensive experiments show that the proposed method surpasses the state of the arts on five deepfake datasets.
MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection
Sep 15, 2024The rapid development of photo-realistic face generation methods has raised significant concerns in society and academia, highlighting the urgent need for robust and generalizable face forgery detection (FFD) techniques. Although existing approaches mainly capture face forgery patterns using image modality, other modalities like fine-grained noises and texts are not fully explored, which limits the generalization capability of the model. In addition, most FFD methods tend to identify facial images generated by GAN, but struggle to detect unseen diffusion-synthesized ones. To address the limitations, we aim to leverage the cutting-edge foundation model, contrastive language-image pre-training (CLIP), to achieve generalizable diffusion face forgery detection (DFFD). In this paper, we propose a novel multi-modal fine-grained CLIP (MFCLIP) model, which mines comprehensive and fine-grained forgery traces across image-noise modalities via language-guided face forgery representation learning, to facilitate the advancement of DFFD. Specifically, we devise a fine-grained language encoder (FLE) that extracts fine global language features from hierarchical text prompts. We design a multi-modal vision encoder (MVE) to capture global image forgery embeddings as well as fine-grained noise forgery patterns extracted from the richest patch, and integrate them to mine general visual forgery traces. Moreover, we build an innovative plug-and-play sample pair attention (SPA) method to emphasize relevant negative pairs and suppress irrelevant ones, allowing cross-modality sample pairs to conduct more flexible alignment. Extensive experiments and visualizations show that our model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations.
GenFace: A Large-Scale Fine-Grained Face Forgery Benchmark and Cross Appearance-Edge Learning
Feb 03, 2024



The rapid advancement of photorealistic generators has reached a critical juncture where the discrepancy between authentic and manipulated images is increasingly indistinguishable. Thus, benchmarking and advancing techniques detecting digital manipulation become an urgent issue. Although there have been a number of publicly available face forgery datasets, the forgery faces are mostly generated using GAN-based synthesis technology, which does not involve the most recent technologies like diffusion. The diversity and quality of images generated by diffusion models have been significantly improved and thus a much more challenging face forgery dataset shall be used to evaluate SOTA forgery detection literature. In this paper, we propose a large-scale, diverse, and fine-grained high-fidelity dataset, namely GenFace, to facilitate the advancement of deepfake detection, which contains a large number of forgery faces generated by advanced generators such as the diffusion-based model and more detailed labels about the manipulation approaches and adopted generators. In addition to evaluating SOTA approaches on our benchmark, we design an innovative cross appearance-edge learning (CAEL) detector to capture multi-grained appearance and edge global representations, and detect discriminative and general forgery traces. Moreover, we devise an appearance-edge cross-attention (AECA) module to explore the various integrations across two domains. Extensive experiment results and visualizations show that our detection model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations. Code and datasets will be available at \url{https://github.com/Jenine-321/GenFace
AerialVLN: Vision-and-Language Navigation for UAVs
Aug 13, 2023



Recently emerged Vision-and-Language Navigation (VLN) tasks have drawn significant attention in both computer vision and natural language processing communities. Existing VLN tasks are built for agents that navigate on the ground, either indoors or outdoors. However, many tasks require intelligent agents to carry out in the sky, such as UAV-based goods delivery, traffic/security patrol, and scenery tour, to name a few. Navigating in the sky is more complicated than on the ground because agents need to consider the flying height and more complex spatial relationship reasoning. To fill this gap and facilitate research in this field, we propose a new task named AerialVLN, which is UAV-based and towards outdoor environments. We develop a 3D simulator rendered by near-realistic pictures of 25 city-level scenarios. Our simulator supports continuous navigation, environment extension and configuration. We also proposed an extended baseline model based on the widely-used cross-modal-alignment (CMA) navigation methods. We find that there is still a significant gap between the baseline model and human performance, which suggests AerialVLN is a new challenging task. Dataset and code is available at https://github.com/AirVLN/AirVLN.