 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRA-BLIP: Multimodal Adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training
Oct 18, 2024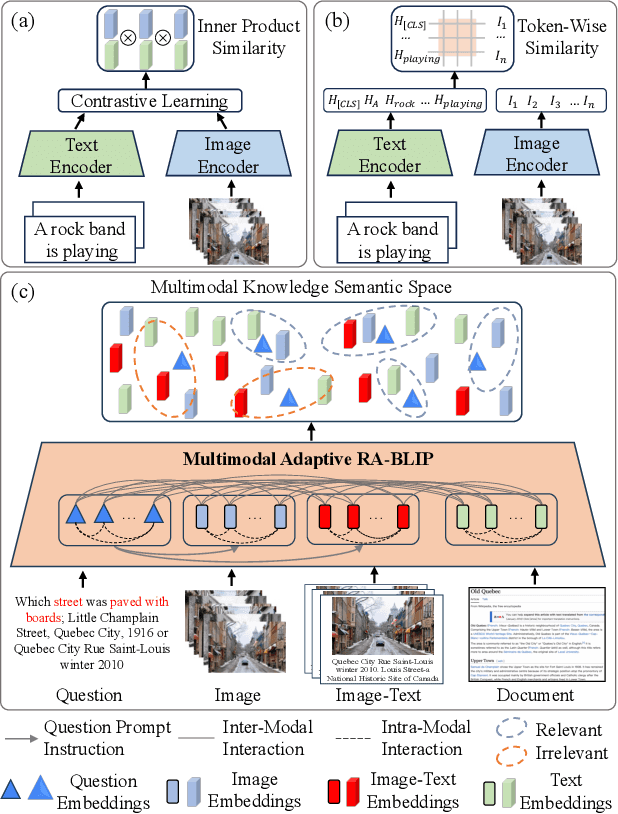
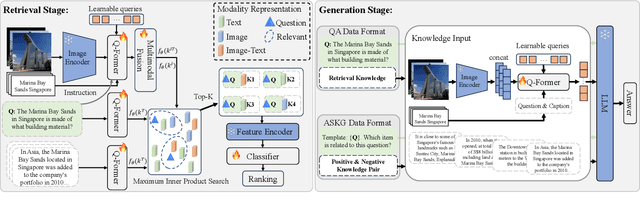
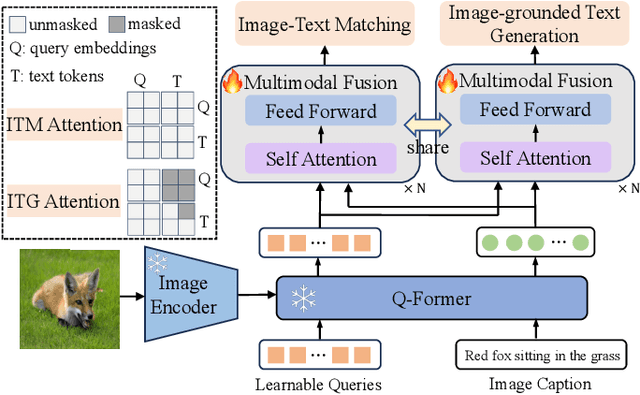
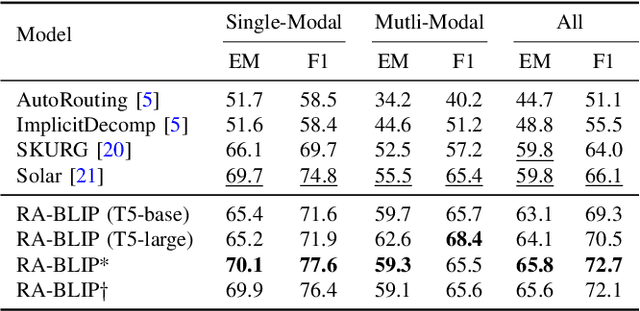
Multimodal Large Language Models (MLLMs) have recently received substantial interest, which shows their emerging potential as general-purpose models for various vision-language tasks. MLLMs involve significant external knowledge within their parameters; however, it is challenging to continually update these models with the latest knowledge, which involves huge computational costs and poor interpretability. Retrieval augmentation techniques have proven to be effective plugins for both LLMs and MLLMs. In this study, we propose multimodal adaptive Retrieval-Augmented Bootstrapping Language-Image Pre-training (RA-BLIP), a novel retrieval-augmented framework for various MLLMs. Considering the redundant information within vision modality, we first leverage the question to instruct the extraction of visual information through interactions with one set of learnable queries, minimizing irrelevant interference during retrieval and generation. Besides, we introduce a pre-trained multimodal adaptive fusion module to achieve question text-to-multimodal retrieval and integration of multimodal knowledge by projecting visual and language modalities into a unified semantic space. Furthermore, we present an Adaptive Selection Knowledge Generation (ASKG) strategy to train the generator to autonomously discern the relevance of retrieved knowledge, which realizes excellent denoising performance. Extensive experiments on open multimodal question-answering datasets demonstrate that RA-BLIP achieves significant performance and surpasses the state-of-the-art retrieval-augmented models.
Preview-based Category Contrastive Learning for Knowledge Distillation
Oct 18, 2024Knowledge distillation is a mainstream algorithm in model compression by transferring knowledge from the larger model (teacher) to the smaller model (student) to improve the performance of student. Despite many efforts, existing methods mainly investigate the consistency between instance-level feature representation or prediction, which neglects the category-level information and the difficulty of each sample, leading to undesirable performance. To address these issues, we propose a novel preview-based category contrastive learning method for knowledge distillation (PCKD). It first distills the structural knowledge of both instance-level feature correspondence and the relation between instance features and category centers in a contrastive learning fashion, which can explicitly optimize the category representation and explore the distinct correlation between representations of instances and categories, contributing to discriminative category centers and better classification results. Besides, we introduce a novel preview strategy to dynamically determine how much the student should learn from each sample according to their difficulty. Different from existing methods that treat all samples equally and curriculum learning that simply filters out hard samples, our method assigns a small weight for hard instances as a preview to better guide the student training. Extensive experiments on several challenging datasets, including CIFAR-100 and ImageNet, demonstrate the superiority over state-of-the-art methods.