 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-enhanced Multi-perspective Video Representation Learning for Scene Recognition
Jan 09, 2024With the explosive growth of video data in real-world applications, a comprehensive representation of videos becomes increasingly important. In this paper, we address the problem of video scene recognition, whose goal is to learn a high-level video representation to classify scenes in videos. Due to the diversity and complexity of video contents in realistic scenarios, this task remains a challenge. Most existing works identify scenes for videos only from visual or textual information in a temporal perspective, ignoring the valuable information hidden in single frames, while several earlier studies only recognize scenes for separate images in a non-temporal perspective. We argue that these two perspectives are both meaningful for this task and complementary to each other, meanwhile, externally introduced knowledge can also promote the comprehension of videos. We propose a novel two-stream framework to model video representations from multiple perspectives, i.e. temporal and non-temporal perspectives, and integrate the two perspectives in an end-to-end manner by self-distillation. Besides, we design a knowledge-enhanced feature fusion and label prediction method that contributes to naturally introducing knowledge into the task of video scene recognition. Experiments conducted on a real-world dataset demonstrate the effectiveness of our proposed method.
PIE: a Parameter and Inference Efficient Solution for Large Scale Knowledge Graph Embedding Reasoning
May 05, 2022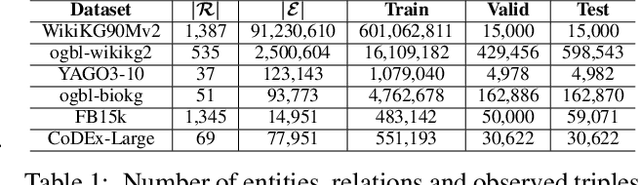
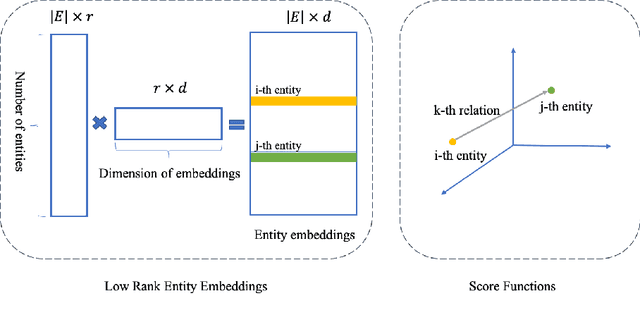

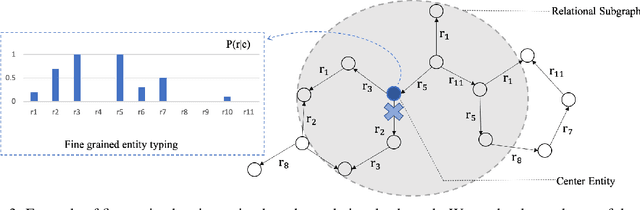
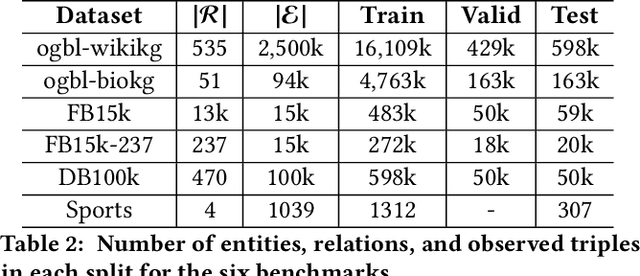
Knowledge graph (KG) embedding methods which map entities and relations to unique embeddings in the KG have shown promising results on many reasoning tasks. However, the same embedding dimension for both dense entities and sparse entities will cause either over parameterization (sparse entities) or under fitting (dense entities). Normally, a large dimension is set to get better performance. Meanwhile, the inference time grows log-linearly with the number of entities for all entities are traversed and compared. Both the parameter and inference become challenges when working with huge amounts of entities. Thus, we propose PIE, a \textbf{p}arameter and \textbf{i}nference \textbf{e}fficient solution. Inspired from tensor decomposition methods, we find that decompose entity embedding matrix into low rank matrices can reduce more than half of the parameters while maintaining comparable performance. To accelerate model inference, we propose a self-supervised auxiliary task, which can be seen as fine-grained entity typing. By randomly masking and recovering entities' connected relations, the task learns the co-occurrence of entity and relations. Utilizing the fine grained typing, we can filter unrelated entities during inference and get targets with possibly sub-linear time requirement. Experiments on link prediction benchmarks demonstrate the proposed key capabilities. Moreover, we prove effectiveness of the proposed solution on the Open Graph Benchmark large scale challenge dataset WikiKG90Mv2 and achieve the state of the art performance.
PairRE: Knowledge Graph Embeddings via Paired Relation Vectors
Nov 07, 2020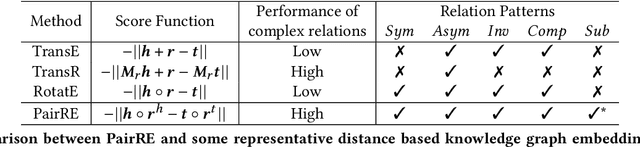
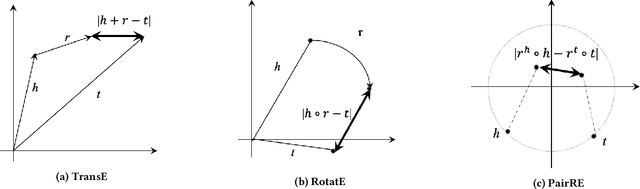

Distance based knowledge graph embedding methods show promising results on link prediction task, on which two topics have been widely studied: one is the ability to handle complex relations, such as N-to-1, 1-to-N and N-to-N, the other is to encode various relation patterns, such as symmetry/antisymmetry. However, the existing methods fail to solve these two problems at the same time, which leads to unsatisfactory results. To mitigate this problem, we propose PairRE, a model with improved expressiveness and low computational requirement. PairRE represents each relation with paired vectors, where these paired vectors project connected two entities to relation specific locations. Beyond its ability to solve the aforementioned two problems, PairRE is advantageous to represent subrelation as it can capture both the similarities and differences of subrelations effectively. Given simple constraints on relation representations, PairRE can be the first model that is capable of encoding symmetry/antisymmetry, inverse, composition and subrelation relations. Experiments on link prediction benchmarks show PairRE can achieve either state-of-the-art or highly competitive performances. In addition, PairRE has shown encouraging results for encoding subrelation.
Audio Visual Emotion Recognition with Temporal Alignment and Perception Attention
Mar 28, 2016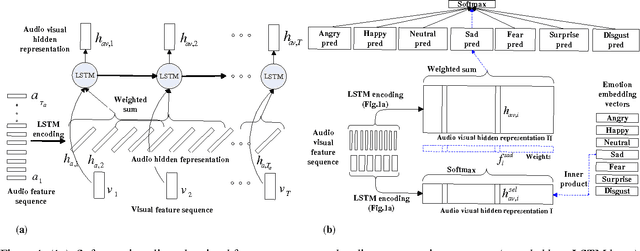
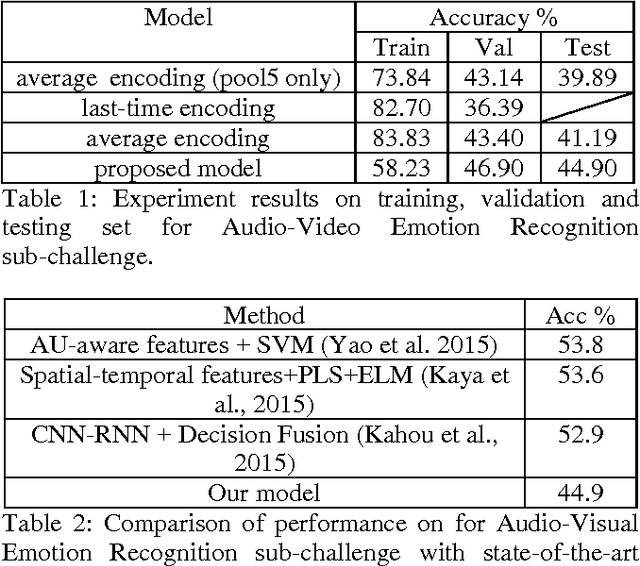

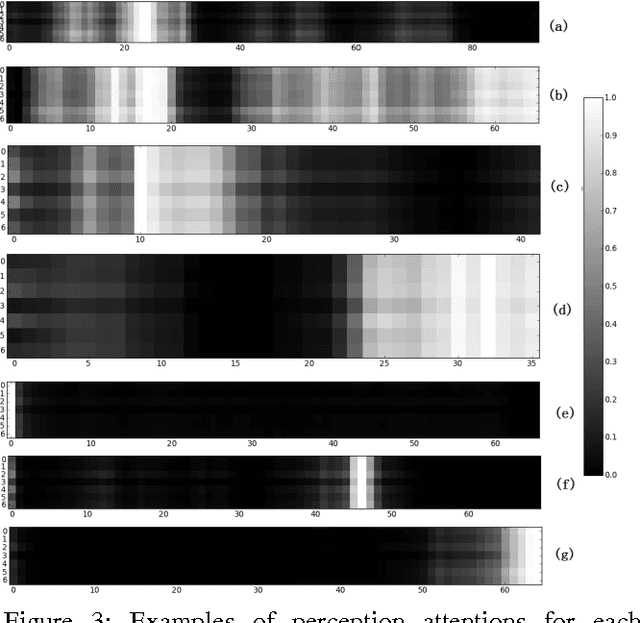
This paper focuses on two key problems for audio-visual emotion recognition in the video. One is the audio and visual streams temporal alignment for feature level fusion. The other one is locating and re-weighting the perception attentions in the whole audio-visual stream for better recognition. The Long Short Term Memory Recurrent Neural Network (LSTM-RNN) is employed as the main classification architecture. Firstly, soft attention mechanism aligns the audio and visual streams. Secondly, seven emotion embedding vectors, which are corresponding to each classification emotion type, are added to locate the perception attentions. The locating and re-weighting process is also based on the soft attention mechanism. The experiment results on EmotiW2015 dataset and the qualitative analysis show the efficiency of the proposed two techniques.