 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Intent Gap: Knowledge-Enhanced Visual Generation
Paper and Code
May 21, 2024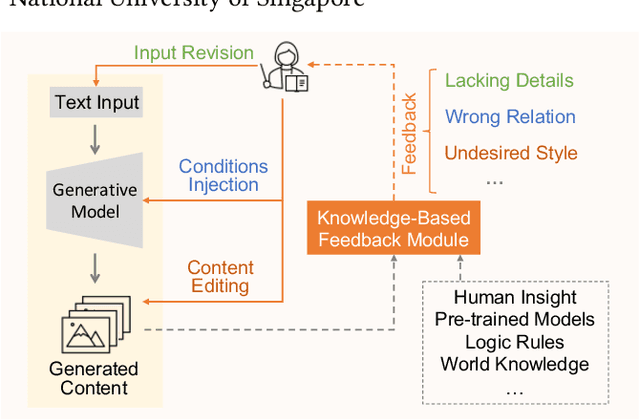
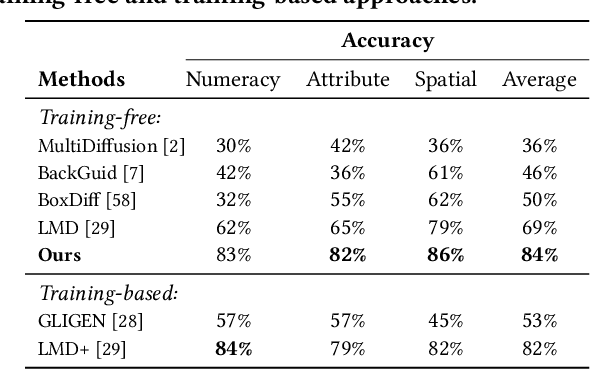
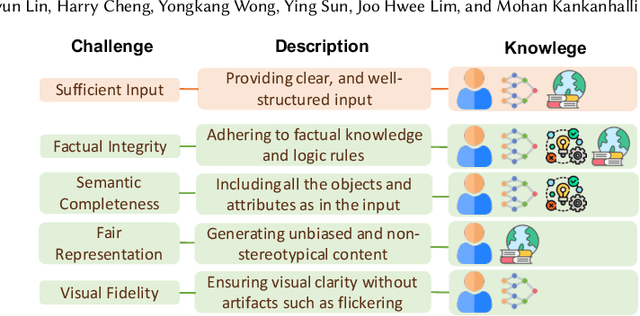
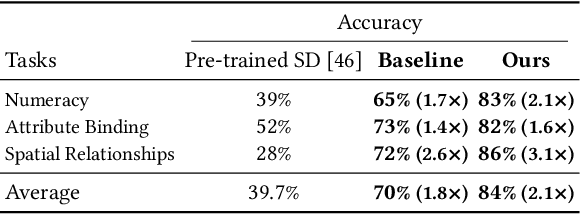
For visual content generation, discrepancies between user intentions and the generated content have been a longstanding problem. This discrepancy arises from two main factors. First, user intentions are inherently complex, with subtle details not fully captured by input prompts. The absence of such details makes it challenging for generative models to accurately reflect the intended meaning, leading to a mismatch between the desired and generated output. Second, generative models trained on visual-label pairs lack the comprehensive knowledge to accurately represent all aspects of the input data in their generated outputs. To address these challenges, we propose a knowledge-enhanced iterative refinement framework for visual content generation. We begin by analyzing and identifying the key challenges faced by existing generative models. Then, we introduce various knowledge sources, including human insights, pre-trained models, logic rules, and world knowledge, which can be leveraged to address these challenges. Furthermore, we propose a novel visual generation framework that incorporates a knowledge-based feedback module to iteratively refine the generation process. This module gradually improves the alignment between the generated content and user intentions. We demonstrate the efficacy of the proposed framework through preliminary results, highlighting the potential of knowledge-enhanced generative models for intention-aligned content generation.