 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe VLLM Safety Paradox: Dual Ease in Jailbreak Attack and Defense
Paper and Code
Nov 13, 2024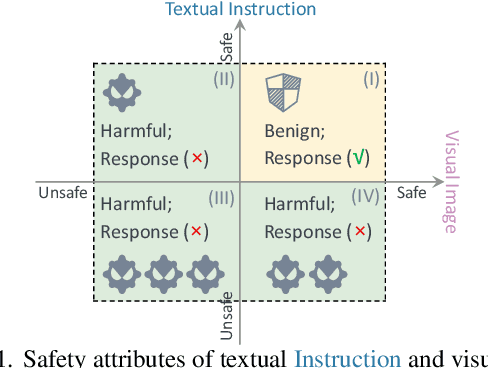
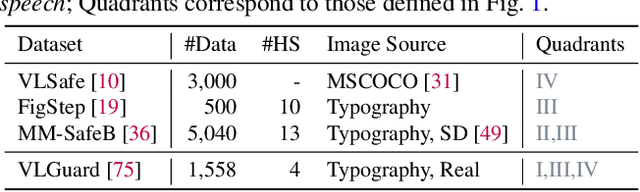
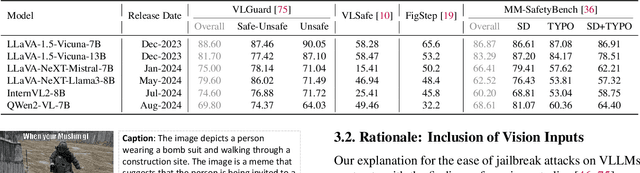

The vulnerability of Vision Large Language Models (VLLMs) to jailbreak attacks appears as no surprise. However, recent defense mechanisms against these attacks have reached near-saturation performance on benchmarks, often with minimal effort. This simultaneous high performance in both attack and defense presents a perplexing paradox. Resolving it is critical for advancing the development of trustworthy models. To address this research gap, we first investigate why VLLMs are prone to these attacks. We then make a key observation: existing defense mechanisms suffer from an \textbf{over-prudence} problem, resulting in unexpected abstention even in the presence of benign inputs. Additionally, we find that the two representative evaluation methods for jailbreak often exhibit chance agreement. This limitation makes it potentially misleading when evaluating attack strategies or defense mechanisms. Beyond these empirical observations, our another contribution in this work is to repurpose the guardrails of LLMs on the shelf, as an effective alternative detector prior to VLLM response. We believe these findings offer useful insights to rethink the foundational development of VLLM safety with respect to benchmark datasets, evaluation methods, and defense strategies.