 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated and Efficient Sampling-Free Confidence Estimation for LiDAR Scene Semantic Segmentation
Nov 18, 2024Reliable deep learning models require not only accurate predictions but also well-calibrated confidence estimates to ensure dependable uncertainty estimation. This is crucial in safety-critical applications like autonomous driving, which depend on rapid and precise semantic segmentation of LiDAR point clouds for real-time 3D scene understanding. In this work, we introduce a sampling-free approach for estimating well-calibrated confidence values for classification tasks, achieving alignment with true classification accuracy and significantly reducing inference time compared to sampling-based methods. Our evaluation using the Adaptive Calibration Error (ACE) metric for LiDAR semantic segmentation shows that our approach maintains well-calibrated confidence values while achieving increased processing speed compared to a sampling baseline. Additionally, reliability diagrams reveal that our method produces underconfidence rather than overconfident predictions, an advantage for safety-critical applications. Our sampling-free approach offers well-calibrated and time-efficient predictions for LiDAR scene semantic segmentation.
Gap Completion in Point Cloud Scene occluded by Vehicles using SGC-Net
Jul 11, 2024Recent advances in mobile mapping systems have greatly enhanced the efficiency and convenience of acquiring urban 3D data. These systems utilize LiDAR sensors mounted on vehicles to capture vast cityscapes. However, a significant challenge arises due to occlusions caused by roadside parked vehicles, leading to the loss of scene information, particularly on the roads, sidewalks, curbs, and the lower sections of buildings. In this study, we present a novel approach that leverages deep neural networks to learn a model capable of filling gaps in urban scenes that are obscured by vehicle occlusion. We have developed an innovative technique where we place virtual vehicle models along road boundaries in the gap-free scene and utilize a ray-casting algorithm to create a new scene with occluded gaps. This allows us to generate diverse and realistic urban point cloud scenes with and without vehicle occlusion, surpassing the limitations of real-world training data collection and annotation. Furthermore, we introduce the Scene Gap Completion Network (SGC-Net), an end-to-end model that can generate well-defined shape boundaries and smooth surfaces within occluded gaps. The experiment results reveal that 97.66% of the filled points fall within a range of 5 centimeters relative to the high-density ground truth point cloud scene. These findings underscore the efficacy of our proposed model in gap completion and reconstructing urban scenes affected by vehicle occlusions.
Maximum Consensus Localization using an Objective Function based on Helmert's Point Error
Feb 21, 2023Ego-localization is a crucial task for autonomous vehicles. On the one hand, it needs to be very accurate, and on the other hand, very robust to provide reliable pose (position and orientation) information, even in challenging environments. Finding the best ego-position is usually tied to optimizing an objective function based on the sensor measurements. The most common approach is to maximize the likelihood, which leads under the assumption of normally distributed random variables to the well-known least squares minimization, often used in conjunction with recursive estimation, e. g. using a Kalman filter. However, least squares minimization is inherently sensitive to outliers, and consequently, more robust loss functions, such as L1 norm or Huber loss have been proposed. Arguably the most robust loss function is the outlier count, also known as maximum consensus optimization, where the outcome is independent of the outlier magnitude. In this paper, we investigate in detail the performance of maximum consensus localization based on LiDAR data. We elaborate on its shortcomings and propose a novel objective function based on Helmert's point error. In an experiment using 3001 measurement epochs, we show that the maximum consensus localization based on the introduced objective function provides superior results with respect to robustness.
Gaussian Process Mapping of Uncertain Building Models with GMM as Prior
Dec 15, 2022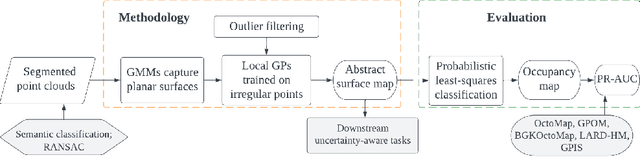

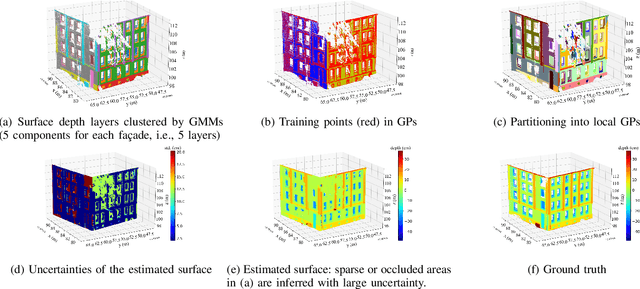
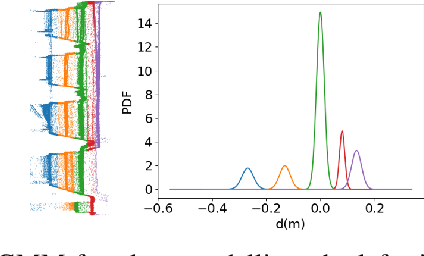
Mapping with uncertainty representation is required in many research domains, such as localization and sensor fusion. Although there are many uncertainty explorations in pose estimation of an ego-robot with map information, the quality of the reference maps is often neglected. To avoid the potential problems caused by the errors of maps and a lack of the uncertainty quantification, an adequate uncertainty measure for the maps is required. In this paper, uncertain building models with abstract map surface using Gaussian Process (GP) is proposed to measure the map uncertainty in a probabilistic way. To reduce the redundant computation for simple planar objects, extracted facets from a Gaussian Mixture Model (GMM) are combined with the implicit GP map while local GP-block techniques are used as well. The proposed method is evaluated on LiDAR point clouds of city buildings collected by a mobile mapping system. Compared to the performances of other methods such like Octomap, Gaussian Process Occupancy Map (GPOM) and Bayersian Generalized Kernel Inference (BGKOctomap), our method has achieved higher Precision-Recall AUC for evaluated buildings.
Determination of building flood risk maps from LiDAR mobile mapping data
Jan 14, 2022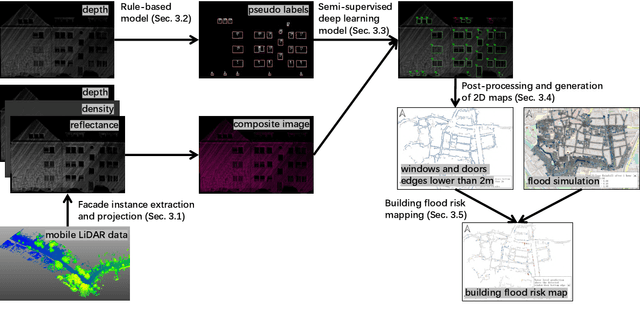
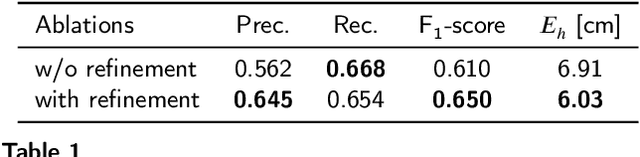
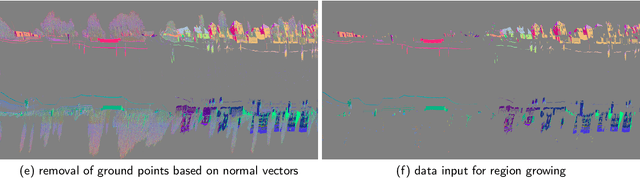
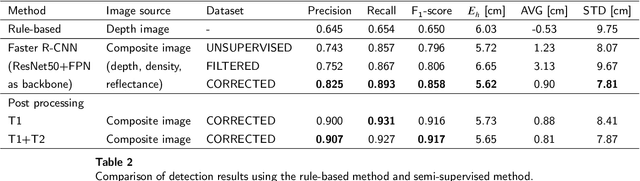
With increasing urbanization, flooding is a major challenge for many cities today. Based on forecast precipitation, topography, and pipe networks, flood simulations can provide early warnings for areas and buildings at risk of flooding. Basement windows, doors, and underground garage entrances are common places where floodwater can flow into a building. Some buildings have been prepared or designed considering the threat of flooding, but others have not. Therefore, knowing the heights of these facade openings helps to identify places that are more susceptible to water ingress. However, such data is not yet readily available in most cities. Traditional surveying of the desired targets may be used, but this is a very time-consuming and laborious process. This research presents a new process for the extraction of windows and doors from LiDAR mobile mapping data. Deep learning object detection models are trained to identify these objects. Usually, this requires to provide large amounts of manual annotations. In this paper, we mitigate this problem by leveraging a rule-based method. In a first step, the rule-based method is used to generate pseudo-labels. A semi-supervised learning strategy is then applied with three different levels of supervision. The results show that using only automatically generated pseudo-labels, the learning-based model outperforms the rule-based approach by 14.6% in terms of F1-score. After five hours of human supervision, it is possible to improve the model by another 6.2%. By comparing the detected facade openings' heights with the predicted water levels from a flood simulation model, a map can be produced which assigns per-building flood risk levels. This information can be combined with flood forecasting to provide a more targeted disaster prevention guide for the city's infrastructure and residential buildings.
Flood severity mapping from Volunteered Geographic Information by interpreting water level from images containing people: a case study of Hurricane Harvey
Jun 21, 2020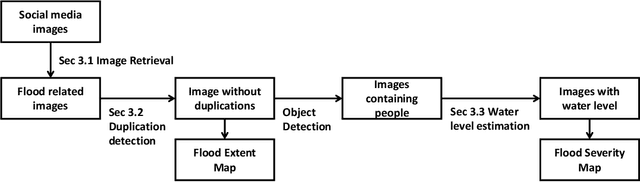

With increasing urbanization, in recent years there has been a growing interest and need in monitoring and analyzing urban flood events. Social media, as a new data source, can provide real-time information for flood monitoring. The social media posts with locations are often referred to as Volunteered Geographic Information (VGI), which can reveal the spatial pattern of such events. Since more images are shared on social media than ever before, recent research focused on the extraction of flood-related posts by analyzing images in addition to texts. Apart from merely classifying posts as flood relevant or not, more detailed information, e.g. the flood severity, can also be extracted based on image interpretation. However, it has been less tackled and has not yet been applied for flood severity mapping. In this paper, we propose a novel three-step pipeline method to extract and map flood severity information. First, flood relevant images are retrieved with the help of pre-trained convolutional neural networks as feature extractors. Second, the images containing people are further classified into four severity levels by observing the relationship between body parts and their partial inundation, i.e. images are classified according to the water level with respect to different body parts, namely ankle, knee, hip, and chest. Lastly, locations of the Tweets are used for generating a map of estimated flood extent and severity. This pipeline was applied to an image dataset collected during Hurricane Harvey in 2017, as a proof of concept. The results show that VGI can be used as a supplement to remote sensing observations for flood extent mapping and is beneficial, especially for urban areas, where the infrastructure is often occluding water. Based on the extracted water level information, an integrated overview of flood severity can be provided for the early stages of emergency response.
Scalable Estimation of Precision Maps in a MapReduce Framework
Sep 24, 2016



This paper presents a large-scale strip adjustment method for LiDAR mobile mapping data, yielding highly precise maps. It uses several concepts to achieve scalability. First, an efficient graph-based pre-segmentation is used, which directly operates on LiDAR scan strip data, rather than on point clouds. Second, observation equations are obtained from a dense matching, which is formulated in terms of an estimation of a latent map. As a result of this formulation, the number of observation equations is not quadratic, but rather linear in the number of scan strips. Third, the dynamic Bayes network, which results from all observation and condition equations, is partitioned into two sub-networks. Consequently, the estimation matrices for all position and orientation corrections are linear instead of quadratic in the number of unknowns and can be solved very efficiently using an alternating least squares approach. It is shown how this approach can be mapped to a standard key/value MapReduce implementation, where each of the processing nodes operates independently on small chunks of data, leading to essentially linear scalability. Results are demonstrated for a dataset of one billion measured LiDAR points and 278,000 unknowns, leading to maps with a precision of a few millimeters.