 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLIA -- Enabling Low-Latency Interactive Avatars: Real-Time Audio-Driven Portrait Video Generation with Diffusion Models
Jun 06, 2025Diffusion-based models have gained wide adoption in the virtual human generation due to their outstanding expressiveness. However, their substantial computational requirements have constrained their deployment in real-time interactive avatar applications, where stringent speed, latency, and duration requirements are paramount. We present a novel audio-driven portrait video generation framework based on the diffusion model to address these challenges. Firstly, we propose robust variable-length video generation to reduce the minimum time required to generate the initial video clip or state transitions, which significantly enhances the user experience. Secondly, we propose a consistency model training strategy for Audio-Image-to-Video to ensure real-time performance, enabling a fast few-step generation. Model quantization and pipeline parallelism are further employed to accelerate the inference speed. To mitigate the stability loss incurred by the diffusion process and model quantization, we introduce a new inference strategy tailored for long-duration video generation. These methods ensure real-time performance and low latency while maintaining high-fidelity output. Thirdly, we incorporate class labels as a conditional input to seamlessly switch between speaking, listening, and idle states. Lastly, we design a novel mechanism for fine-grained facial expression control to exploit our model's inherent capacity. Extensive experiments demonstrate that our approach achieves low-latency, fluid, and authentic two-way communication. On an NVIDIA RTX 4090D, our model achieves a maximum of 78 FPS at a resolution of 384x384 and 45 FPS at a resolution of 512x512, with an initial video generation latency of 140 ms and 215 ms, respectively.
Semi-MAE: Masked Autoencoders for Semi-supervised Vision Transformers
Jan 04, 2023



Vision Transformer (ViT) suffers from data scarcity in semi-supervised learning (SSL). To alleviate this issue, inspired by masked autoencoder (MAE), which is a data-efficient self-supervised learner, we propose Semi-MAE, a pure ViT-based SSL framework consisting of a parallel MAE branch to assist the visual representation learning and make the pseudo labels more accurate. The MAE branch is designed as an asymmetric architecture consisting of a lightweight decoder and a shared-weights encoder. We feed the weakly-augmented unlabeled data with a high masking ratio to the MAE branch and reconstruct the missing pixels. Semi-MAE achieves 75.9% top-1 accuracy on ImageNet with 10% labels, surpassing prior state-of-the-art in semi-supervised image classification. In addition, extensive experiments demonstrate that Semi-MAE can be readily used for other ViT models and masked image modeling methods.
Accurate Word Representations with Universal Visual Guidance
Dec 30, 2020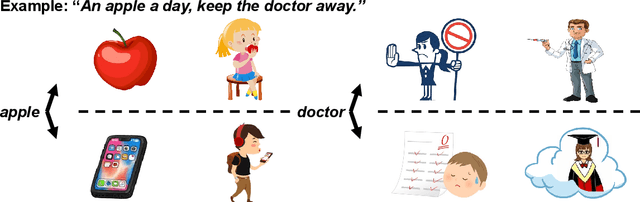



Word representation is a fundamental component in neural language understanding models. Recently, pre-trained language models (PrLMs) offer a new performant method of contextualized word representations by leveraging the sequence-level context for modeling. Although the PrLMs generally give more accurate contextualized word representations than non-contextualized models do, they are still subject to a sequence of text contexts without diverse hints for word representation from multimodality. This paper thus proposes a visual representation method to explicitly enhance conventional word embedding with multiple-aspect senses from visual guidance. In detail, we build a small-scale word-image dictionary from a multimodal seed dataset where each word corresponds to diverse related images. The texts and paired images are encoded in parallel, followed by an attention layer to integrate the multimodal representations. We show that the method substantially improves the accuracy of disambiguation. Experiments on 12 natural language understanding and machine translation tasks further verify the effectiveness and the generalization capability of the proposed approach.