 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Word Representations with Universal Visual Guidance
Paper and Code
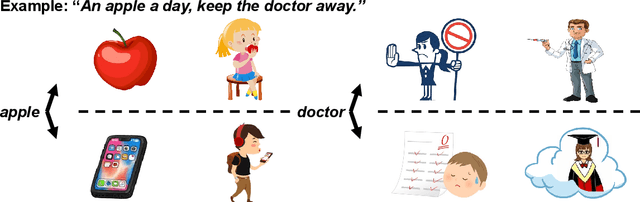



Word representation is a fundamental component in neural language understanding models. Recently, pre-trained language models (PrLMs) offer a new performant method of contextualized word representations by leveraging the sequence-level context for modeling. Although the PrLMs generally give more accurate contextualized word representations than non-contextualized models do, they are still subject to a sequence of text contexts without diverse hints for word representation from multimodality. This paper thus proposes a visual representation method to explicitly enhance conventional word embedding with multiple-aspect senses from visual guidance. In detail, we build a small-scale word-image dictionary from a multimodal seed dataset where each word corresponds to diverse related images. The texts and paired images are encoded in parallel, followed by an attention layer to integrate the multimodal representations. We show that the method substantially improves the accuracy of disambiguation. Experiments on 12 natural language understanding and machine translation tasks further verify the effectiveness and the generalization capability of the proposed approach.