 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFB-CLIP: Fine-Grained Zero-Shot Anomaly Detection with Foreground-Background Disentanglement
Mar 20, 2026Fine-grained anomaly detection is crucial in industrial and medical applications, but labeled anomalies are often scarce, making zero-shot detection challenging. While vision-language models like CLIP offer promising solutions, they struggle with foreground-background feature entanglement and coarse textual semantics. We propose FB-CLIP, a framework that enhances anomaly localization via multi-strategy textual representations and foreground-background separation. In the textual modality, it combines End-of-Text features, global-pooled representations, and attention-weighted token features for richer semantic cues. In the visual modality, multi-view soft separation along identity, semantic, and spatial dimensions, together with background suppression, reduces interference and improves discriminability. Semantic Consistency Regularization (SCR) aligns image features with normal and abnormal textual prototypes, suppressing uncertain matches and enlarging semantic gaps. Experiments show that FB-CLIP effectively distinguishes anomalies from complex backgrounds, achieving accurate fine-grained anomaly detection and localization under zero-shot settings.
Multi-Paradigm Collaborative Adversarial Attack Against Multi-Modal Large Language Models
Mar 05, 2026The rapid progress of Multi-Modal Large Language Models (MLLMs) has significantly advanced downstream applications. However, this progress also exposes serious transferable adversarial vulnerabilities. In general, existing adversarial attacks against MLLMs typically rely on surrogate models trained within a single learning paradigm and perform independent optimisation in their respective feature spaces. This straightforward setting naturally restricts the richness of feature representations, delivering limits on the search space and thus impeding the diversity of adversarial perturbations. To address this, we propose a novel Multi-Paradigm Collaborative Attack (MPCAttack) framework to boost the transferability of adversarial examples against MLLMs. In principle, MPCAttack aggregates semantic representations, from both visual images and language texts, to facilitate joint adversarial optimisation on the aggregated features through a Multi-Paradigm Collaborative Optimisation (MPCO) strategy. By performing contrastive matching on multi-paradigm features, MPCO adaptively balances the importance of different paradigm representations and guides the global perturbation optimisation, effectively alleviating the representation bias. Extensive experimental results on multiple benchmarks demonstrate the superiority of MPCAttack, indicating that our solution consistently outperforms state-of-the-art methods in both targeted and untargeted attacks on open-source and closed-source MLLMs. The code is released at https://github.com/LiYuanBoJNU/MPCAttack.
Towards Highly Transferable Vision-Language Attack via Semantic-Augmented Dynamic Contrastive Interaction
Mar 05, 2026With the rapid advancement and widespread application of vision-language pre-training (VLP) models, their vulnerability to adversarial attacks has become a critical concern. In general, the adversarial examples can typically be designed to exhibit transferable power, attacking not only different models but also across diverse tasks. However, existing attacks on language-vision models mainly rely on static cross-modal interactions and focus solely on disrupting positive image-text pairs, resulting in limited cross-modal disruption and poor transferability. To address this issue, we propose a Semantic-Augmented Dynamic Contrastive Attack (SADCA) that enhances adversarial transferability through progressive and semantically guided perturbation. SADCA progressively disrupts cross-modal alignment through dynamic interactions between adversarial images and texts. This is accomplished by SADCA establishing a contrastive learning mechanism involving adversarial, positive and negative samples, to reinforce the semantic inconsistency of the obtained perturbations. Moreover, we empirically find that input transformations commonly used in traditional transfer-based attacks also benefit VLPs, which motivates a semantic augmentation module that increases the diversity and generalization of adversarial examples. Extensive experiments on multiple datasets and models demonstrate that SADCA significantly improves adversarial transferability and consistently surpasses state-of-the-art methods. The code is released at https://github.com/LiYuanBoJNU/SADCA.
Conditional Variational Autoencoder for Sign Language Translation with Cross-Modal Alignment
Dec 25, 2023



Sign language translation (SLT) aims to convert continuous sign language videos into textual sentences. As a typical multi-modal task, there exists an inherent modality gap between sign language videos and spoken language text, which makes the cross-modal alignment between visual and textual modalities crucial. However, previous studies tend to rely on an intermediate sign gloss representation to help alleviate the cross-modal problem thereby neglecting the alignment across modalities that may lead to compromised results. To address this issue, we propose a novel framework based on Conditional Variational autoencoder for SLT (CV-SLT) that facilitates direct and sufficient cross-modal alignment between sign language videos and spoken language text. Specifically, our CV-SLT consists of two paths with two Kullback-Leibler (KL) divergences to regularize the outputs of the encoder and decoder, respectively. In the prior path, the model solely relies on visual information to predict the target text; whereas in the posterior path, it simultaneously encodes visual information and textual knowledge to reconstruct the target text. The first KL divergence optimizes the conditional variational autoencoder and regularizes the encoder outputs, while the second KL divergence performs a self-distillation from the posterior path to the prior path, ensuring the consistency of decoder outputs. We further enhance the integration of textual information to the posterior path by employing a shared Attention Residual Gaussian Distribution (ARGD), which considers the textual information in the posterior path as a residual component relative to the prior path. Extensive experiments conducted on public datasets (PHOENIX14T and CSL-daily) demonstrate the effectiveness of our framework, achieving new state-of-the-art results while significantly alleviating the cross-modal representation discrepancy.
SDA-$x$Net: Selective Depth Attention Networks for Adaptive Multi-scale Feature Representation
Sep 21, 2022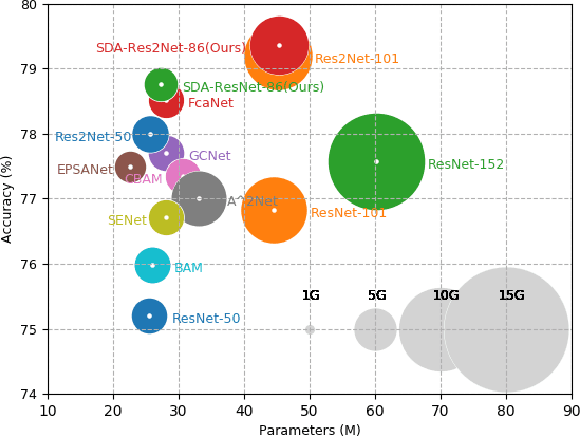
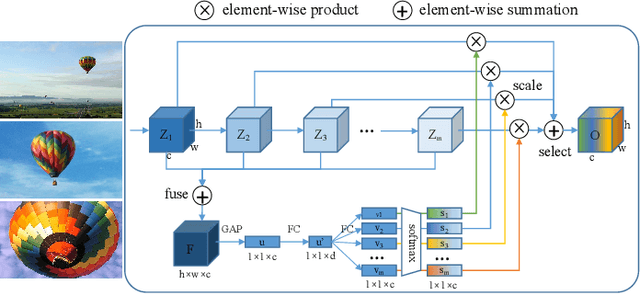
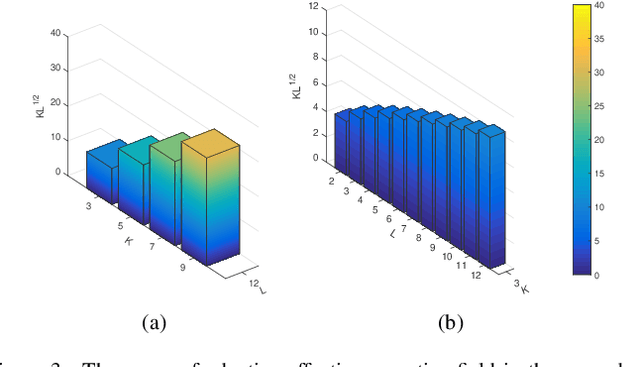

Existing multi-scale solutions lead to a risk of just increasing the receptive field sizes while neglecting small receptive fields. Thus, it is a challenging problem to effectively construct adaptive neural networks for recognizing various spatial-scale objects. To tackle this issue, we first introduce a new attention dimension, i.e., depth, in addition to existing attention dimensions such as channel, spatial, and branch, and present a novel selective depth attention network to symmetrically handle multi-scale objects in various vision tasks. Specifically, the blocks within each stage of a given neural network, i.e., ResNet, output hierarchical feature maps sharing the same resolution but with different receptive field sizes. Based on this structural property, we design a stage-wise building module, namely SDA, which includes a trunk branch and a SE-like attention branch. The block outputs of the trunk branch are fused to globally guide their depth attention allocation through the attention branch. According to the proposed attention mechanism, we can dynamically select different depth features, which contributes to adaptively adjusting the receptive field sizes for the variable-sized input objects. In this way, the cross-block information interaction leads to a long-range dependency along the depth direction. Compared with other multi-scale approaches, our SDA method combines multiple receptive fields from previous blocks into the stage output, thus offering a wider and richer range of effective receptive fields. Moreover, our method can be served as a pluggable module to other multi-scale networks as well as attention networks, coined as SDA-$x$Net. Their combination further extends the range of the effective receptive fields towards small receptive fields, enabling interpretable neural networks. Our source code is available at \url{https://github.com/QingbeiGuo/SDA-xNet.git}.
ConSLT: A Token-level Contrastive Framework for Sign Language Translation
Apr 11, 2022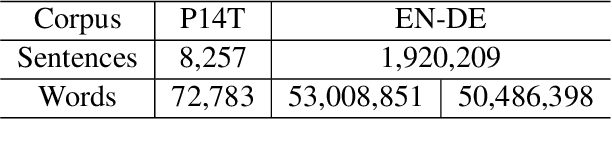
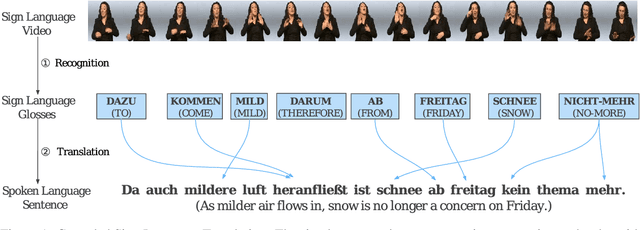
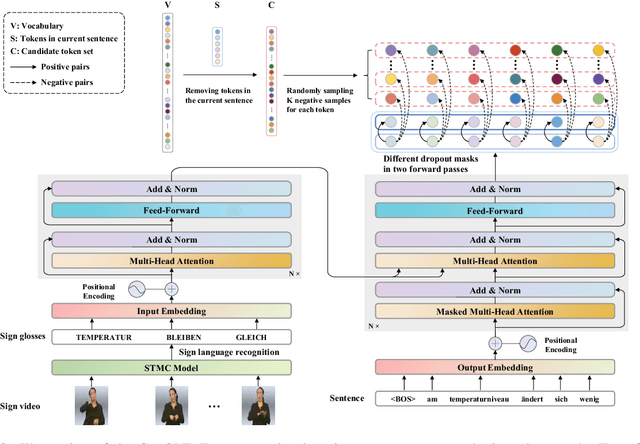
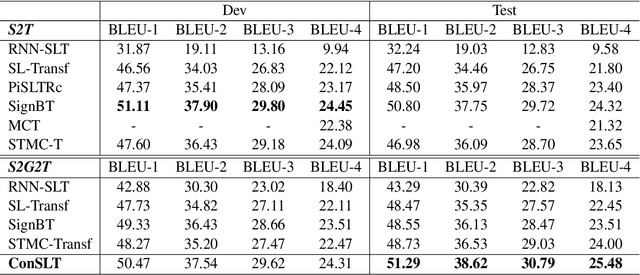
Sign language translation (SLT) is an important technology that can bridge the communication gap between the deaf and the hearing people. SLT task is essentially a low-resource problem due to the scarcity of publicly available parallel data. To this end, inspired by the success of neural machine translation methods based on contrastive learning, we propose ConSLT, a novel token-level \textbf{Con}trastive learning framework for \textbf{S}ign \textbf{L}anguage \textbf{T}ranslation. Unlike previous contrastive learning based works whose goal is to obtain better sentence representation, ConSLT aims to learn effective token representation by pushing apart tokens from different sentences. Concretely, our model follows the two-stage SLT method. First, in the recoginition stage, we use a state-of-the-art continuous sign language recognition model to recognize glosses from sign frames. Then, in the translation stage, we adopt the Transformer framework while introducing contrastive learning. Specifically, we pass each sign glosses to the Transformer model twice to obtain two different hidden layer representations for each token as "positive examples" and randomly sample K tokens that are not in the current sentence from the vocabulary as "negative examples" for each token. Experimental results demonstrate that ConSLT achieves new state-of-the-art performance on PHOENIX14T dataset, with +1.48 BLEU improvements.
Dual Encoder-Decoder based Generative Adversarial Networks for Disentangled Facial Representation Learning
Sep 19, 2019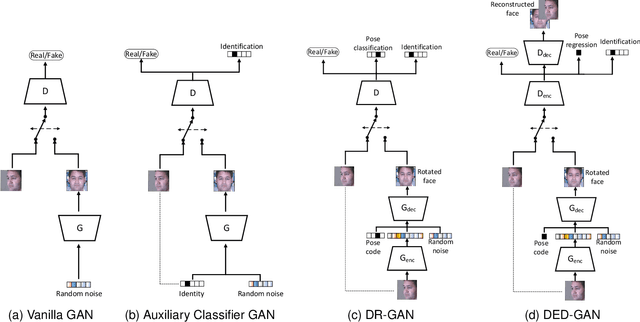

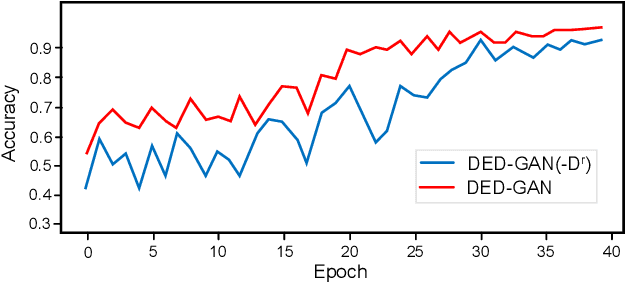
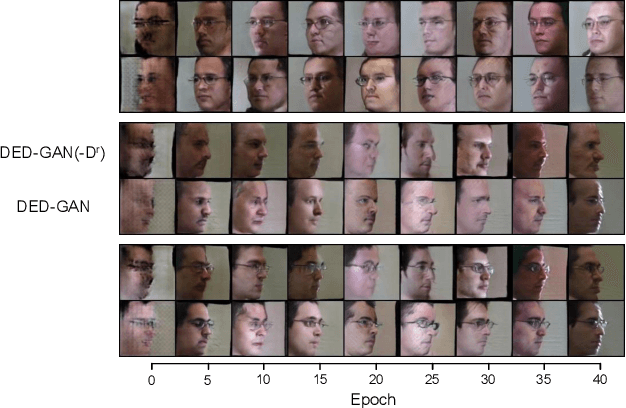
To learn disentangled representations of facial images, we present a Dual Encoder-Decoder based Generative Adversarial Network (DED-GAN). In the proposed method, both the generator and discriminator are designed with deep encoder-decoder architectures as their backbones. To be more specific, the encoder-decoder structured generator is used to learn a pose disentangled face representation, and the encoder-decoder structured discriminator is tasked to perform real/fake classification, face reconstruction, determining identity and estimating face pose. We further improve the proposed network architecture by minimising the additional pixel-wise loss defined by the Wasserstein distance at the output of the discriminator so that the adversarial framework can be better trained. Additionally, we consider face pose variation to be continuous, rather than discrete in existing literature, to inject richer pose information into our model. The pose estimation task is formulated as a regression problem, which helps to disentangle identity information from pose variations. The proposed network is evaluated on the tasks of pose-invariant face recognition (PIFR) and face synthesis across poses. An extensive quantitative and qualitative evaluation carried out on several controlled and in-the-wild benchmarking datasets demonstrates the superiority of the proposed DED-GAN method over the state-of-the-art approaches.
Combining Subgoal Graphs with Reinforcement Learning to Build a Rational Pathfinder
Nov 05, 2018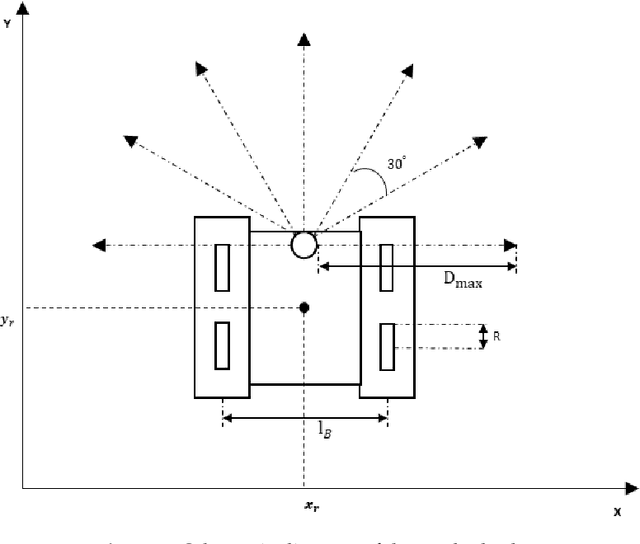

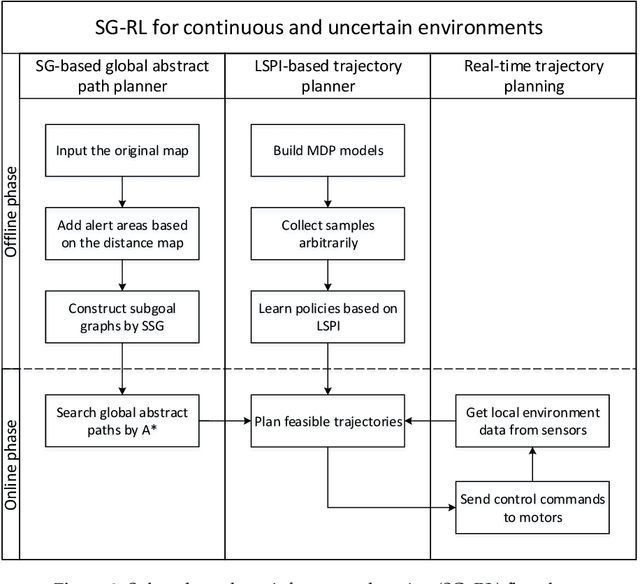
In this paper, we present a hierarchical path planning framework called SG-RL (subgoal graphs-reinforcement learning), to plan rational paths for agents maneuvering in continuous and uncertain environments. By "rational", we mean (1) efficient path planning to eliminate first-move lags; (2) collision-free and smooth for agents with kinematic constraints satisfied. SG-RL works in a two-level manner. At the first level, SG-RL uses a geometric path-planning method, i.e., Simple Subgoal Graphs (SSG), to efficiently find optimal abstract paths, also called subgoal sequences. At the second level, SG-RL uses an RL method, i.e., Least-Squares Policy Iteration (LSPI), to learn near-optimal motion-planning policies which can generate kinematically feasible and collision-free trajectories between adjacent subgoals. The first advantage of the proposed method is that SSG can solve the limitations of sparse reward and local minima trap for RL agents; thus, LSPI can be used to generate paths in complex environments. The second advantage is that, when the environment changes slightly (i.e., unexpected obstacles appearing), SG-RL does not need to reconstruct subgoal graphs and replan subgoal sequences using SSG, since LSPI can deal with uncertainties by exploiting its generalization ability to handle changes in environments. Simulation experiments in representative scenarios demonstrate that, compared with existing methods, SG-RL can work well on large-scale maps with relatively low action-switching frequencies and shorter path lengths, and SG-RL can deal with small changes in environments. We further demonstrate that the design of reward functions and the types of training environments are important factors for learning feasible policies.