 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Encoder-Decoder based Generative Adversarial Networks for Disentangled Facial Representation Learning
Paper and Code
Sep 19, 2019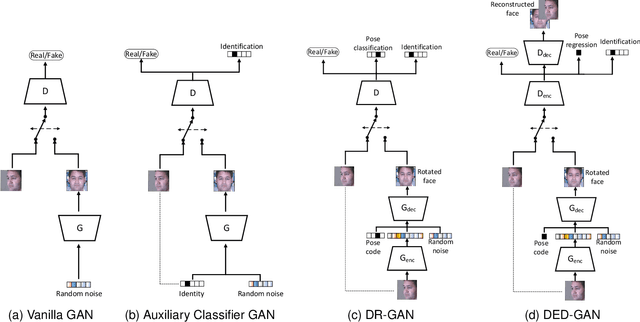

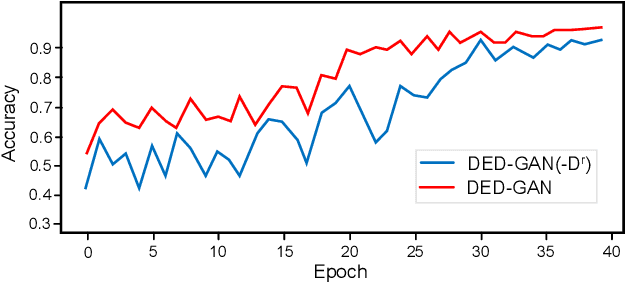
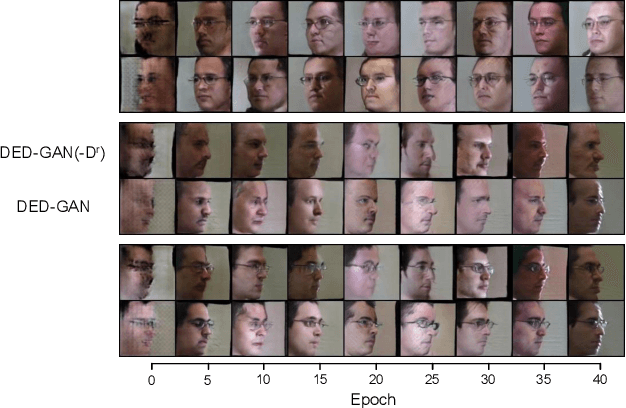
To learn disentangled representations of facial images, we present a Dual Encoder-Decoder based Generative Adversarial Network (DED-GAN). In the proposed method, both the generator and discriminator are designed with deep encoder-decoder architectures as their backbones. To be more specific, the encoder-decoder structured generator is used to learn a pose disentangled face representation, and the encoder-decoder structured discriminator is tasked to perform real/fake classification, face reconstruction, determining identity and estimating face pose. We further improve the proposed network architecture by minimising the additional pixel-wise loss defined by the Wasserstein distance at the output of the discriminator so that the adversarial framework can be better trained. Additionally, we consider face pose variation to be continuous, rather than discrete in existing literature, to inject richer pose information into our model. The pose estimation task is formulated as a regression problem, which helps to disentangle identity information from pose variations. The proposed network is evaluated on the tasks of pose-invariant face recognition (PIFR) and face synthesis across poses. An extensive quantitative and qualitative evaluation carried out on several controlled and in-the-wild benchmarking datasets demonstrates the superiority of the proposed DED-GAN method over the state-of-the-art approaches.