 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Subgoal Graphs with Reinforcement Learning to Build a Rational Pathfinder
Paper and Code
Nov 05, 2018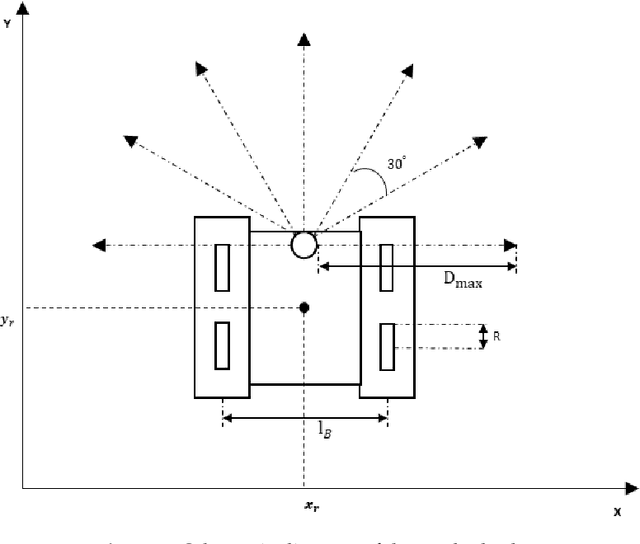

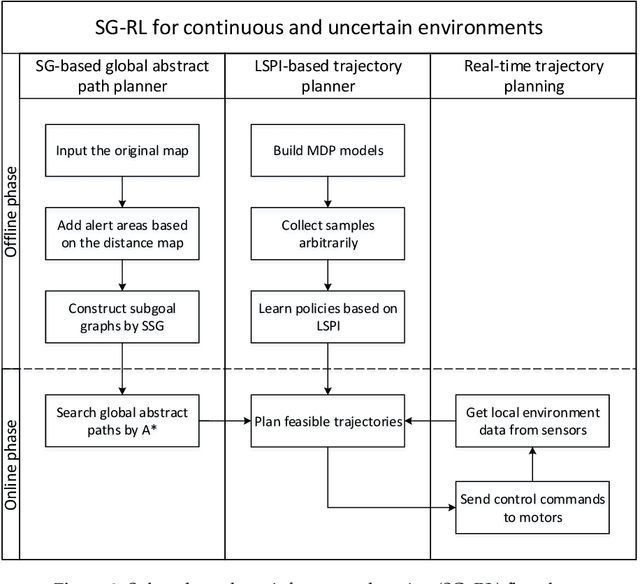
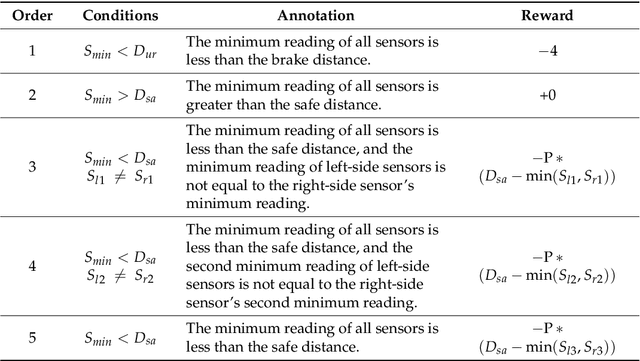
In this paper, we present a hierarchical path planning framework called SG-RL (subgoal graphs-reinforcement learning), to plan rational paths for agents maneuvering in continuous and uncertain environments. By "rational", we mean (1) efficient path planning to eliminate first-move lags; (2) collision-free and smooth for agents with kinematic constraints satisfied. SG-RL works in a two-level manner. At the first level, SG-RL uses a geometric path-planning method, i.e., Simple Subgoal Graphs (SSG), to efficiently find optimal abstract paths, also called subgoal sequences. At the second level, SG-RL uses an RL method, i.e., Least-Squares Policy Iteration (LSPI), to learn near-optimal motion-planning policies which can generate kinematically feasible and collision-free trajectories between adjacent subgoals. The first advantage of the proposed method is that SSG can solve the limitations of sparse reward and local minima trap for RL agents; thus, LSPI can be used to generate paths in complex environments. The second advantage is that, when the environment changes slightly (i.e., unexpected obstacles appearing), SG-RL does not need to reconstruct subgoal graphs and replan subgoal sequences using SSG, since LSPI can deal with uncertainties by exploiting its generalization ability to handle changes in environments. Simulation experiments in representative scenarios demonstrate that, compared with existing methods, SG-RL can work well on large-scale maps with relatively low action-switching frequencies and shorter path lengths, and SG-RL can deal with small changes in environments. We further demonstrate that the design of reward functions and the types of training environments are important factors for learning feasible policies.