 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDA-$x$Net: Selective Depth Attention Networks for Adaptive Multi-scale Feature Representation
Sep 21, 2022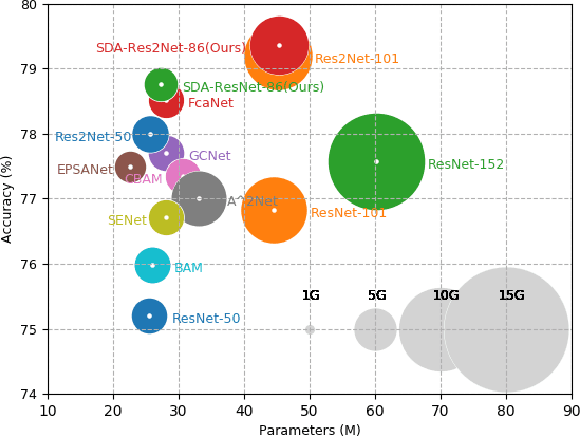
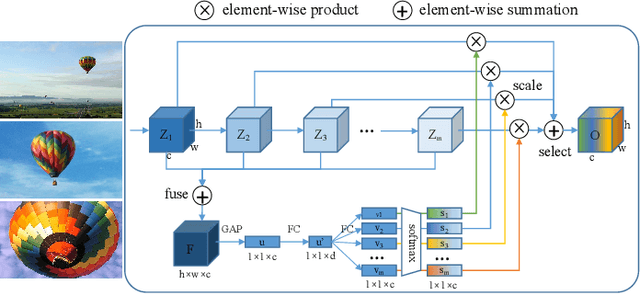
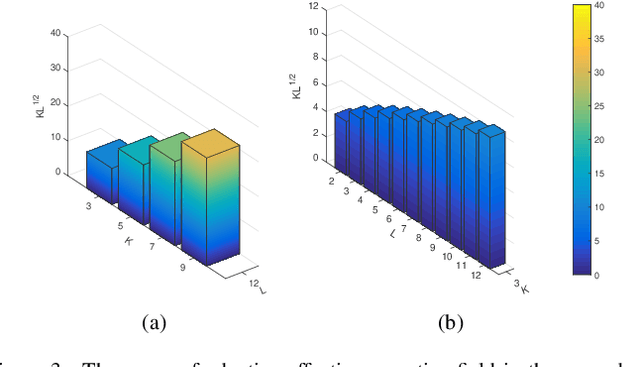

Existing multi-scale solutions lead to a risk of just increasing the receptive field sizes while neglecting small receptive fields. Thus, it is a challenging problem to effectively construct adaptive neural networks for recognizing various spatial-scale objects. To tackle this issue, we first introduce a new attention dimension, i.e., depth, in addition to existing attention dimensions such as channel, spatial, and branch, and present a novel selective depth attention network to symmetrically handle multi-scale objects in various vision tasks. Specifically, the blocks within each stage of a given neural network, i.e., ResNet, output hierarchical feature maps sharing the same resolution but with different receptive field sizes. Based on this structural property, we design a stage-wise building module, namely SDA, which includes a trunk branch and a SE-like attention branch. The block outputs of the trunk branch are fused to globally guide their depth attention allocation through the attention branch. According to the proposed attention mechanism, we can dynamically select different depth features, which contributes to adaptively adjusting the receptive field sizes for the variable-sized input objects. In this way, the cross-block information interaction leads to a long-range dependency along the depth direction. Compared with other multi-scale approaches, our SDA method combines multiple receptive fields from previous blocks into the stage output, thus offering a wider and richer range of effective receptive fields. Moreover, our method can be served as a pluggable module to other multi-scale networks as well as attention networks, coined as SDA-$x$Net. Their combination further extends the range of the effective receptive fields towards small receptive fields, enabling interpretable neural networks. Our source code is available at \url{https://github.com/QingbeiGuo/SDA-xNet.git}.
Differentiable Neural Architecture Learning for Efficient Neural Network Design
Mar 03, 2021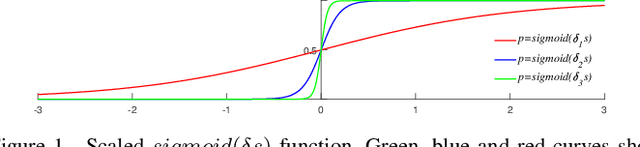

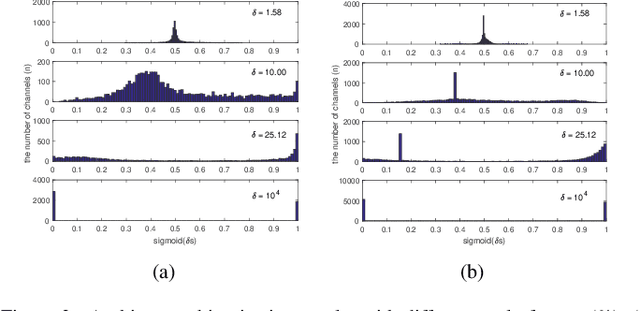
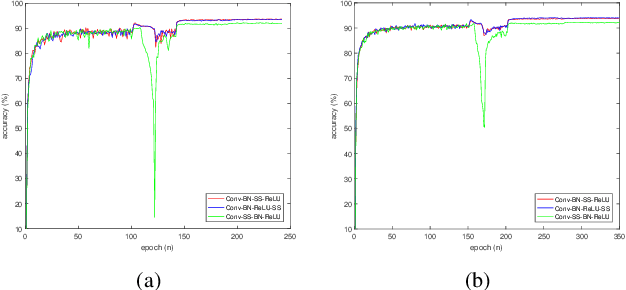
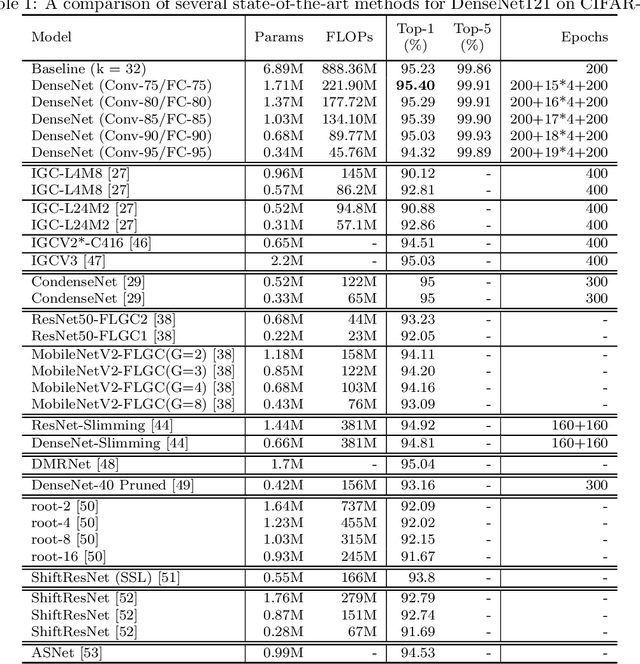
Automated neural network design has received ever-increasing attention with the evolution of deep convolutional neural networks (CNNs), especially involving their deployment on embedded and mobile platforms. One of the biggest problems that neural architecture search (NAS) confronts is that a large number of candidate neural architectures are required to train, using, for instance, reinforcement learning and evolutionary optimisation algorithms, at a vast computation cost. Even recent differentiable neural architecture search (DNAS) samples a small number of candidate neural architectures based on the probability distribution of learned architecture parameters to select the final neural architecture. To address this computational complexity issue, we introduce a novel \emph{architecture parameterisation} based on scaled sigmoid function, and propose a general \emph{Differentiable Neural Architecture Learning} (DNAL) method to optimize the neural architecture without the need to evaluate candidate neural networks. Specifically, for stochastic supernets as well as conventional CNNs, we build a new channel-wise module layer with the architecture components controlled by a scaled sigmoid function. We train these neural network models from scratch. The network optimization is decoupled into the weight optimization and the architecture optimization. We address the non-convex optimization problem of neural architecture by the continuous scaled sigmoid method with convergence guarantees. Extensive experiments demonstrate our DNAL method delivers superior performance in terms of neural architecture search cost. The optimal networks learned by DNAL surpass those produced by the state-of-the-art methods on the benchmark CIFAR-10 and ImageNet-1K dataset in accuracy, model size and computational complexity.
Self-grouping Convolutional Neural Networks
Sep 29, 2020
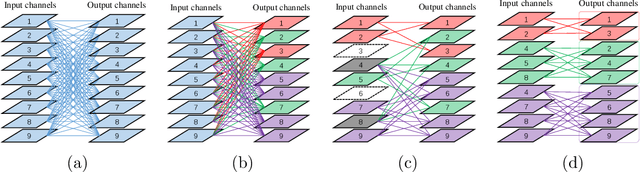
Although group convolution operators are increasingly used in deep convolutional neural networks to improve the computational efficiency and to reduce the number of parameters, most existing methods construct their group convolution architectures by a predefined partitioning of the filters of each convolutional layer into multiple regular filter groups with an equal spatial group size and data-independence, which prevents a full exploitation of their potential. To tackle this issue, we propose a novel method of designing self-grouping convolutional neural networks, called SG-CNN, in which the filters of each convolutional layer group themselves based on the similarity of their importance vectors. Concretely, for each filter, we first evaluate the importance value of their input channels to identify the importance vectors, and then group these vectors by clustering. Using the resulting \emph{data-dependent} centroids, we prune the less important connections, which implicitly minimizes the accuracy loss of the pruning, thus yielding a set of \emph{diverse} group convolution filters. Subsequently, we develop two fine-tuning schemes, i.e. (1) both local and global fine-tuning and (2) global only fine-tuning, which experimentally deliver comparable results, to recover the recognition capacity of the pruned network. Comprehensive experiments carried out on the CIFAR-10/100 and ImageNet datasets demonstrate that our self-grouping convolution method adapts to various state-of-the-art CNN architectures, such as ResNet and DenseNet, and delivers superior performance in terms of compression ratio, speedup and recognition accuracy. We demonstrate the ability of SG-CNN to generalise by transfer learning, including domain adaption and object detection, showing competitive results. Our source code is available at https://github.com/QingbeiGuo/SG-CNN.git.