 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Neural Architecture Learning for Efficient Neural Network Design
Paper and Code
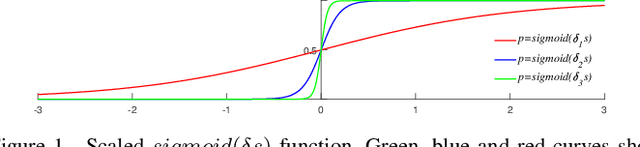

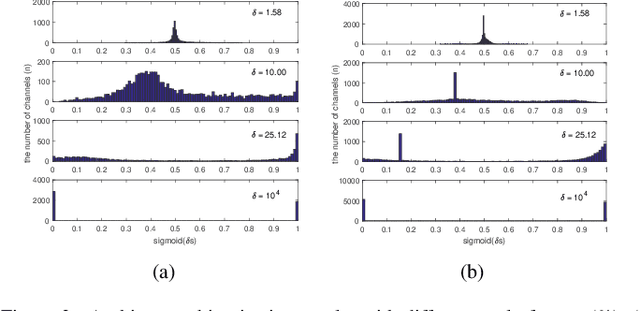
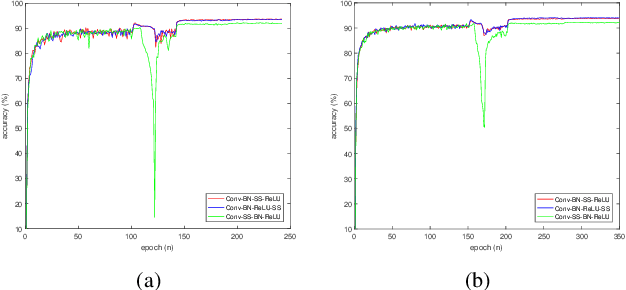
Automated neural network design has received ever-increasing attention with the evolution of deep convolutional neural networks (CNNs), especially involving their deployment on embedded and mobile platforms. One of the biggest problems that neural architecture search (NAS) confronts is that a large number of candidate neural architectures are required to train, using, for instance, reinforcement learning and evolutionary optimisation algorithms, at a vast computation cost. Even recent differentiable neural architecture search (DNAS) samples a small number of candidate neural architectures based on the probability distribution of learned architecture parameters to select the final neural architecture. To address this computational complexity issue, we introduce a novel \emph{architecture parameterisation} based on scaled sigmoid function, and propose a general \emph{Differentiable Neural Architecture Learning} (DNAL) method to optimize the neural architecture without the need to evaluate candidate neural networks. Specifically, for stochastic supernets as well as conventional CNNs, we build a new channel-wise module layer with the architecture components controlled by a scaled sigmoid function. We train these neural network models from scratch. The network optimization is decoupled into the weight optimization and the architecture optimization. We address the non-convex optimization problem of neural architecture by the continuous scaled sigmoid method with convergence guarantees. Extensive experiments demonstrate our DNAL method delivers superior performance in terms of neural architecture search cost. The optimal networks learned by DNAL surpass those produced by the state-of-the-art methods on the benchmark CIFAR-10 and ImageNet-1K dataset in accuracy, model size and computational complexity.