 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLightNNs: Lightweight Quantized Deep Neural Networks for Fast and Accurate Inference
Apr 05, 2019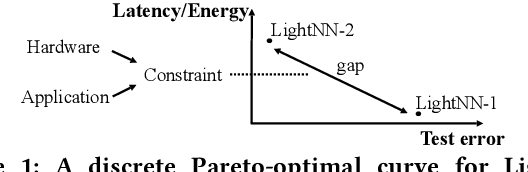
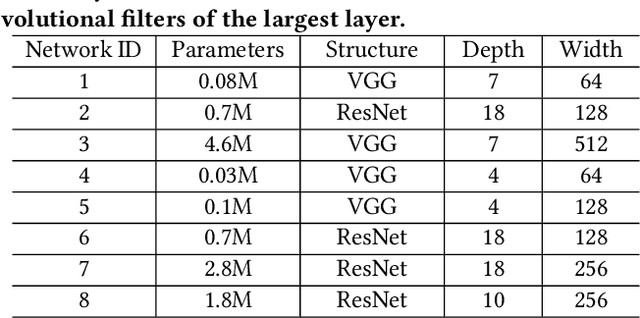
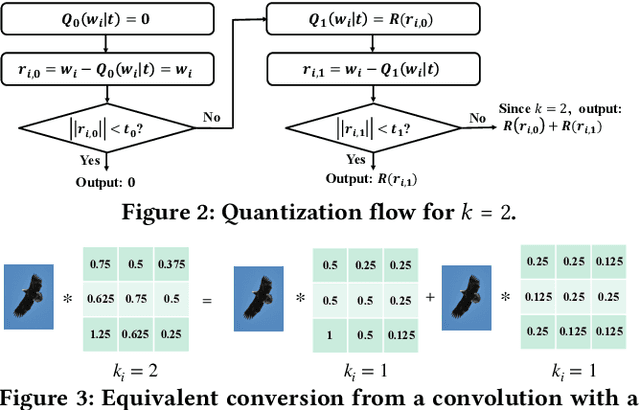
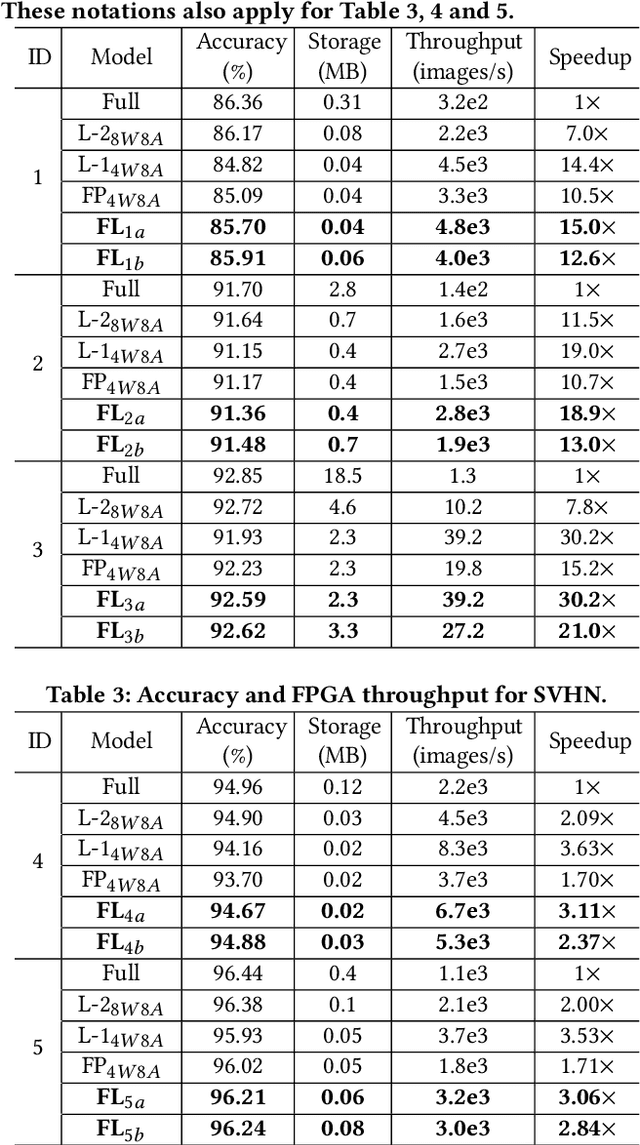
To improve the throughput and energy efficiency of Deep Neural Networks (DNNs) on customized hardware, lightweight neural networks constrain the weights of DNNs to be a limited combination (denoted as $k\in\{1,2\}$) of powers of 2. In such networks, the multiply-accumulate operation can be replaced with a single shift operation, or two shifts and an add operation. To provide even more design flexibility, the $k$ for each convolutional filter can be optimally chosen instead of being fixed for every filter. In this paper, we formulate the selection of $k$ to be differentiable, and describe model training for determining $k$-based weights on a per-filter basis. Over 46 FPGA-design experiments involving eight configurations and four data sets reveal that lightweight neural networks with a flexible $k$ value (dubbed FLightNNs) fully utilize the hardware resources on Field Programmable Gate Arrays (FPGAs), our experimental results show that FLightNNs can achieve 2$\times$ speedup when compared to lightweight NNs with $k=2$, with only 0.1\% accuracy degradation. Compared to a 4-bit fixed-point quantization, FLightNNs achieve higher accuracy and up to 2$\times$ inference speedup, due to their lightweight shift operations. In addition, our experiments also demonstrate that FLightNNs can achieve higher computational energy efficiency for ASIC implementation.
Regularizing Activation Distribution for Training Binarized Deep Networks
Apr 04, 2019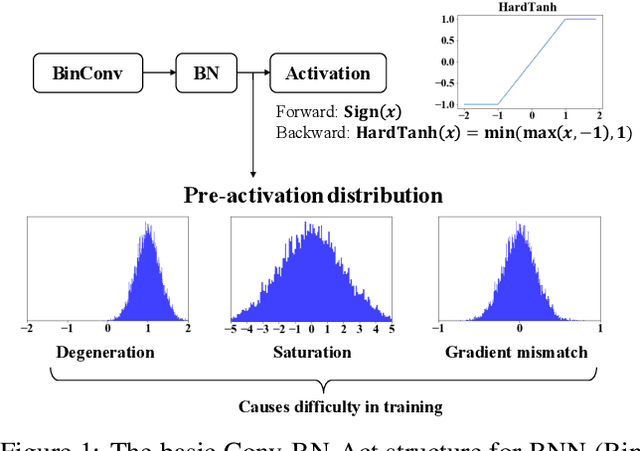
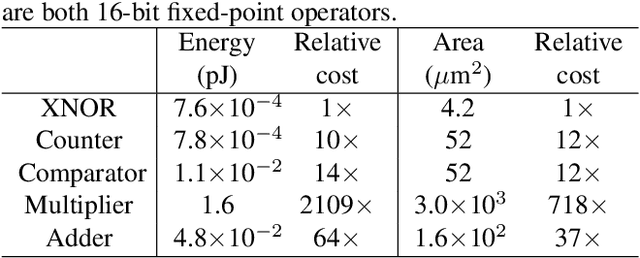
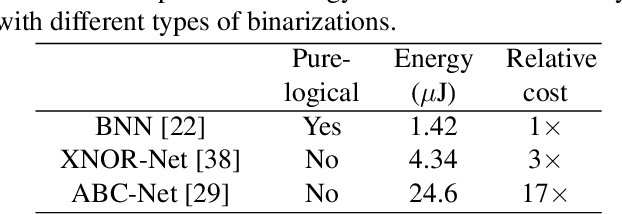
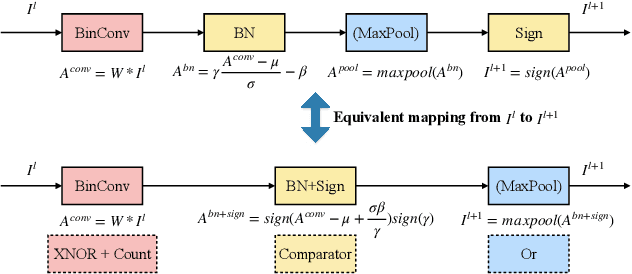
Binarized Neural Networks (BNNs) can significantly reduce the inference latency and energy consumption in resource-constrained devices due to their pure-logical computation and fewer memory accesses. However, training BNNs is difficult since the activation flow encounters degeneration, saturation, and gradient mismatch problems. Prior work alleviates these issues by increasing activation bits and adding floating-point scaling factors, thereby sacrificing BNN's energy efficiency. In this paper, we propose to use distribution loss to explicitly regularize the activation flow, and develop a framework to systematically formulate the loss. Our experiments show that the distribution loss can consistently improve the accuracy of BNNs without losing their energy benefits. Moreover, equipped with the proposed regularization, BNN training is shown to be robust to the selection of hyper-parameters including optimizer and learning rate.
LightNN: Filling the Gap between Conventional Deep Neural Networks and Binarized Networks
Dec 02, 2017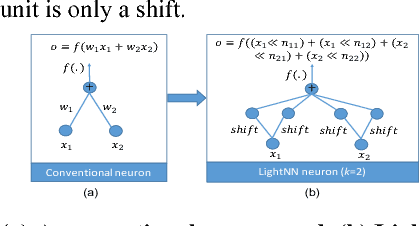
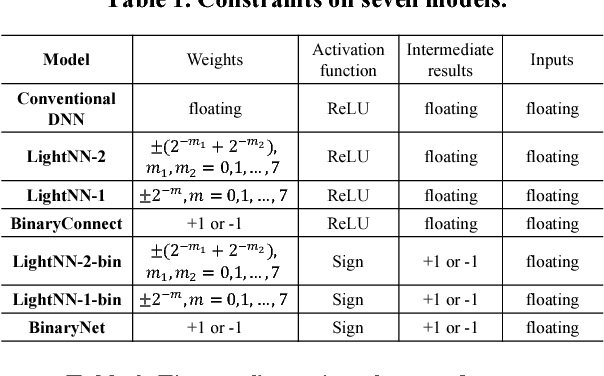

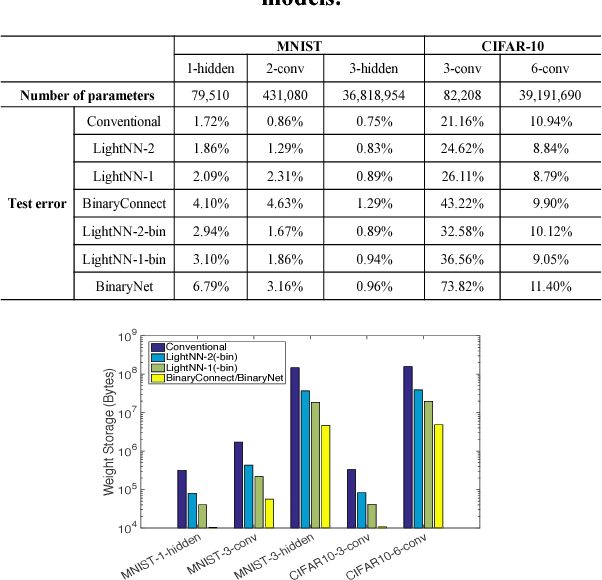
Application-specific integrated circuit (ASIC) implementations for Deep Neural Networks (DNNs) have been adopted in many systems because of their higher classification speed. However, although they may be characterized by better accuracy, larger DNNs require significant energy and area, thereby limiting their wide adoption. The energy consumption of DNNs is driven by both memory accesses and computation. Binarized Neural Networks (BNNs), as a trade-off between accuracy and energy consumption, can achieve great energy reduction, and have good accuracy for large DNNs due to its regularization effect. However, BNNs show poor accuracy when a smaller DNN configuration is adopted. In this paper, we propose a new DNN model, LightNN, which replaces the multiplications to one shift or a constrained number of shifts and adds. For a fixed DNN configuration, LightNNs have better accuracy at a slight energy increase than BNNs, yet are more energy efficient with only slightly less accuracy than conventional DNNs. Therefore, LightNNs provide more options for hardware designers to make trade-offs between accuracy and energy. Moreover, for large DNN configurations, LightNNs have a regularization effect, making them better in accuracy than conventional DNNs. These conclusions are verified by experiment using the MNIST and CIFAR-10 datasets for different DNN configurations.