 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQUIDAM: A Framework for Quantization-Aware DNN Accelerator and Model Co-Exploration
Jun 30, 2022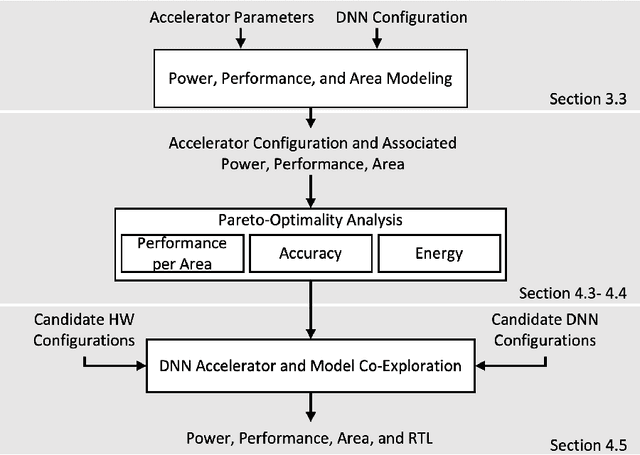
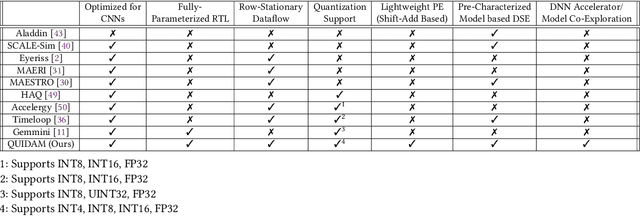
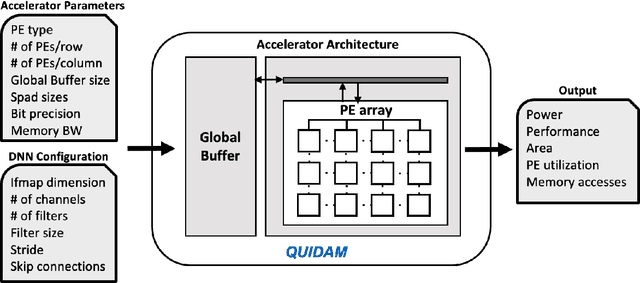
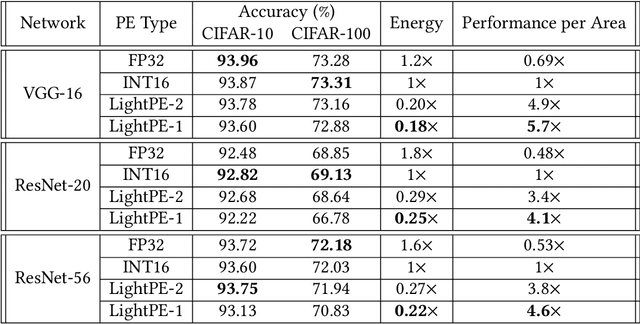
As the machine learning and systems communities strive to achieve higher energy-efficiency through custom deep neural network (DNN) accelerators, varied precision or quantization levels, and model compression techniques, there is a need for design space exploration frameworks that incorporate quantization-aware processing elements into the accelerator design space while having accurate and fast power, performance, and area models. In this work, we present QUIDAM, a highly parameterized quantization-aware DNN accelerator and model co-exploration framework. Our framework can facilitate future research on design space exploration of DNN accelerators for various design choices such as bit precision, processing element type, scratchpad sizes of processing elements, global buffer size, number of total processing elements, and DNN configurations. Our results show that different bit precisions and processing element types lead to significant differences in terms of performance per area and energy. Specifically, our framework identifies a wide range of design points where performance per area and energy varies more than 5x and 35x, respectively. With the proposed framework, we show that lightweight processing elements achieve on par accuracy results and up to 5.7x more performance per area and energy improvement when compared to the best INT16 based implementation. Finally, due to the efficiency of the pre-characterized power, performance, and area models, QUIDAM can speed up the design exploration process by 3-4 orders of magnitude as it removes the need for expensive synthesis and characterization of each design.
Width Transfer: On the variance of Width Optimization
Apr 24, 2021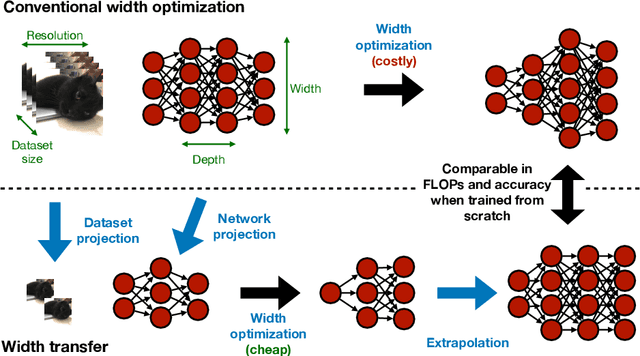

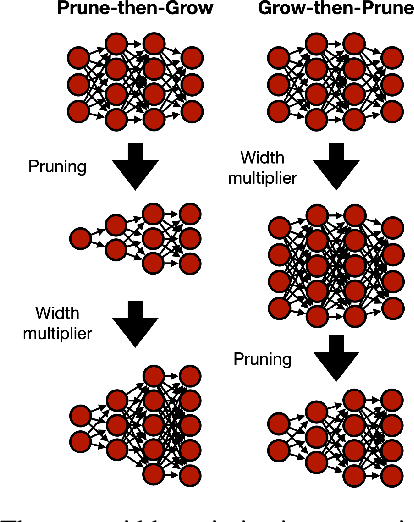
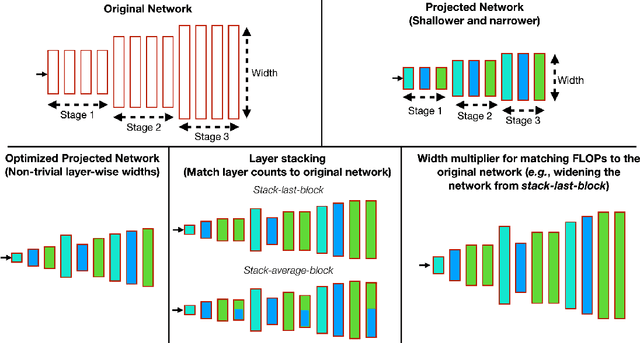
Optimizing the channel counts for different layers of a CNN has shown great promise in improving the efficiency of CNNs at test-time. However, these methods often introduce large computational overhead (e.g., an additional 2x FLOPs of standard training). Minimizing this overhead could therefore significantly speed up training. In this work, we propose width transfer, a technique that harnesses the assumptions that the optimized widths (or channel counts) are regular across sizes and depths. We show that width transfer works well across various width optimization algorithms and networks. Specifically, we can achieve up to 320x reduction in width optimization overhead without compromising the top-1 accuracy on ImageNet, making the additional cost of width optimization negligible relative to initial training. Our findings not only suggest an efficient way to conduct width optimization but also highlight that the widths that lead to better accuracy are invariant to various aspects of network architectures and training data.
One Weight Bitwidth to Rule Them All
Aug 28, 2020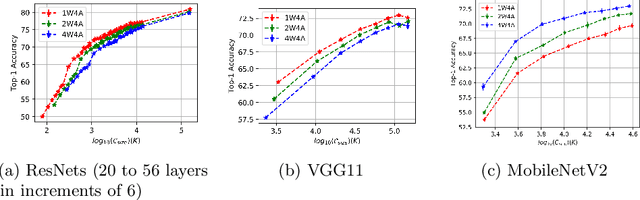

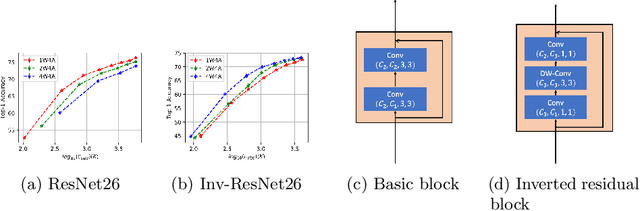
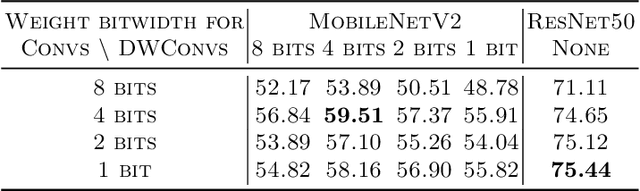
Weight quantization for deep ConvNets has shown promising results for applications such as image classification and semantic segmentation and is especially important for applications where memory storage is limited. However, when aiming for quantization without accuracy degradation, different tasks may end up with different bitwidths. This creates complexity for software and hardware support and the complexity accumulates when one considers mixed-precision quantization, in which case each layer's weights use a different bitwidth. Our key insight is that optimizing for the least bitwidth subject to no accuracy degradation is not necessarily an optimal strategy. This is because one cannot decide optimality between two bitwidths if one has a smaller model size while the other has better accuracy. In this work, we take the first step to understand if some weight bitwidth is better than others by aligning all to the same model size using a width-multiplier. Under this setting, somewhat surprisingly, we show that using a single bitwidth for the whole network can achieve better accuracy compared to mixed-precision quantization targeting zero accuracy degradation when both have the same model size. In particular, our results suggest that when the number of channels becomes a target hyperparameter, a single weight bitwidth throughout the network shows superior results for model compression.
PareCO: Pareto-aware Channel Optimization for Slimmable Neural Networks
Jul 23, 2020
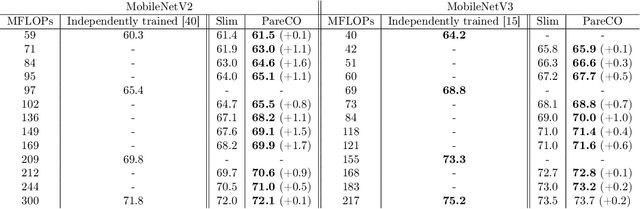

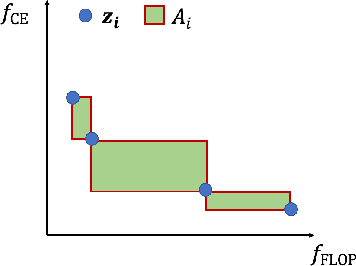
Slimmable neural networks provide a flexible trade-off front between prediction error and computational cost (such as the number of floating-point operations or FLOPs) with the same storage cost as a single model, have been proposed recently for resource-constrained settings such as mobile devices. However, current slimmable neural networks use a single width-multiplier for all the layers to arrive at sub-networks with different performance profiles, which neglects that different layers affect the network's prediction accuracy differently and have different FLOP requirements. Hence, developing a principled approach for deciding width-multipliers across different layers could potentially improve the performance of slimmable networks. To allow for heterogeneous width-multipliers across different layers, we formulate the problem of optimizing slimmable networks from a multi-objective optimization lens, which leads to a novel algorithm for optimizing both the shared weights and the width-multipliers for the sub-networks. We perform extensive empirical analysis with 14 network and dataset combinations and find that less over-parameterized networks benefit more from a joint channel and weight optimization than extremely over-parameterized networks. Quantitatively, improvements up to 1.7\% and 1\% in top-1 accuracy on the ImageNet dataset can be attained for MobileNetV2 and MobileNetV3, respectively. Our results highlight the potential of optimizing the channel counts for different layers jointly with the weights and demonstrate the power of such techniques for slimmable networks.
Improving the Adversarial Robustness of Transfer Learning via Noisy Feature Distillation
Feb 07, 2020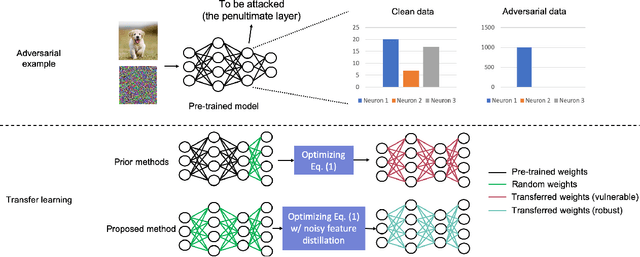

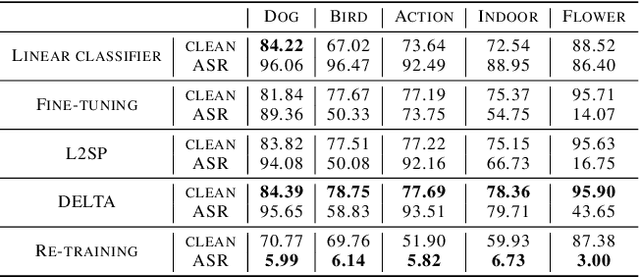
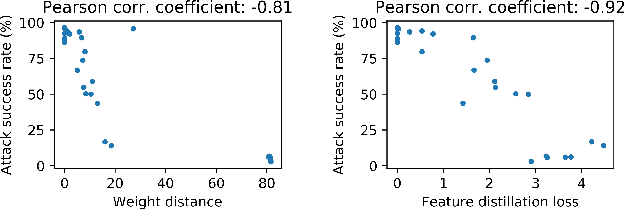
Fine-tuning through knowledge transfer from a pre-trained model on a large-scale dataset is a widely spread approach to effectively build models on small-scale datasets. However, recent literature has shown that such a fine-tuning approach is vulnerable to adversarial examples based on the pre-trained model, which raises security concerns for many industrial applications. In contrast, models trained with random initialization are much more robust to such attacks, although these models often exhibit much lower accuracy. In this work, we propose noisy feature distillation, a new transfer learning method that trains a network from random initialization while achieving clean-data performance competitive with fine-tuning. In addition, the method is shown empirically to significantly improve the robustness compared to fine-tuning with 15x reduction in attack success rate for ResNet-50, from 66% to 4.4% averaged across Stanford 120 Dogs, Caltech-UCSD 200 Birds, Stanford 40 Actions, MIT 67 Indoor Scenes, and Oxford 102 Flowers datasets. Code is available at https://github.com/cmu-enyac/Renofeation.
LeGR: Filter Pruning via Learned Global Ranking
Apr 28, 2019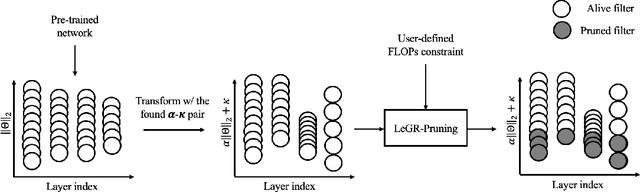
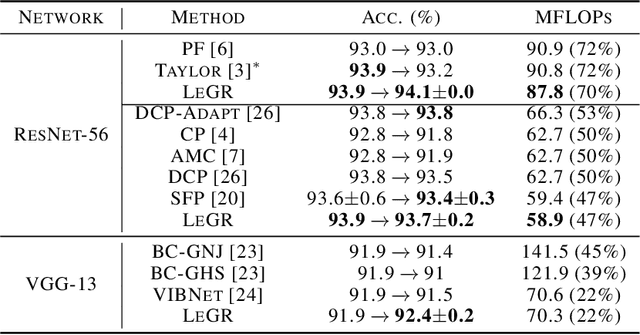
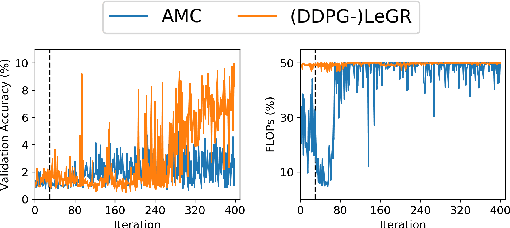
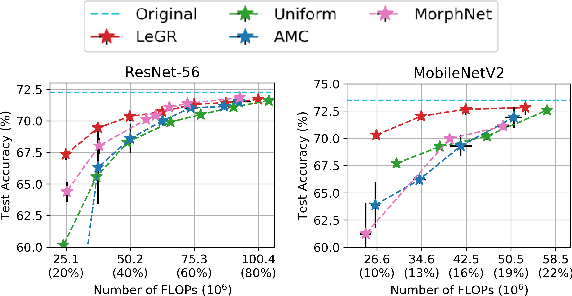
Filter pruning has shown to be effective for learning resource-constrained convolutional neural networks (CNNs). However, prior methods for resource-constrained filter pruning have some limitations that hinder their effectiveness and efficiency. When searching for constraint-satisfying CNNs, prior methods either alter the optimization objective or adopt local search algorithms with heuristic parameterization, which are sub-optimal, especially in low-resource regime. From the efficiency perspective, prior methods are often costly to search for constraint-satisfying CNNs. In this work, we propose learned global ranking, dubbed LeGR, which improves upon prior art in the two aforementioned dimensions. Inspired by theoretical analysis, LeGR is parameterized to learn layer-wise affine transformations over the filter norms to construct a learned global ranking. With global ranking, resource-constrained filter pruning at various constraint levels can be done efficiently. We conduct extensive empirical analyses to demonstrate the effectiveness of the proposed algorithm with ResNet and MobileNetV2 networks on CIFAR-10, CIFAR-100, Bird-200, and ImageNet datasets. Code is publicly available at https://github.com/cmu-enyac/LeGR.
FLightNNs: Lightweight Quantized Deep Neural Networks for Fast and Accurate Inference
Apr 05, 2019
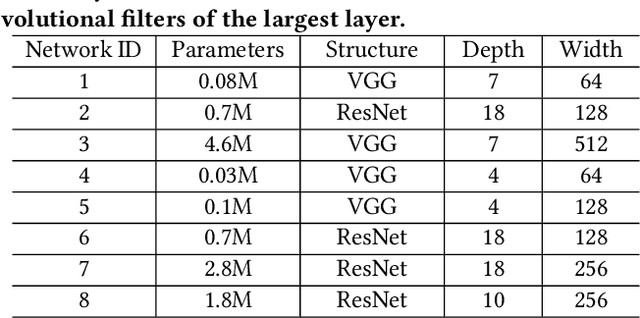
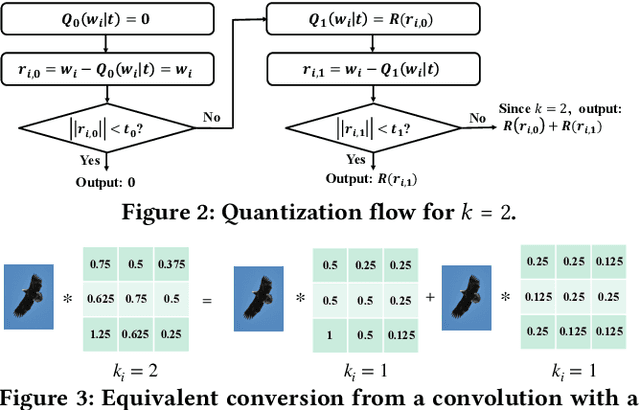
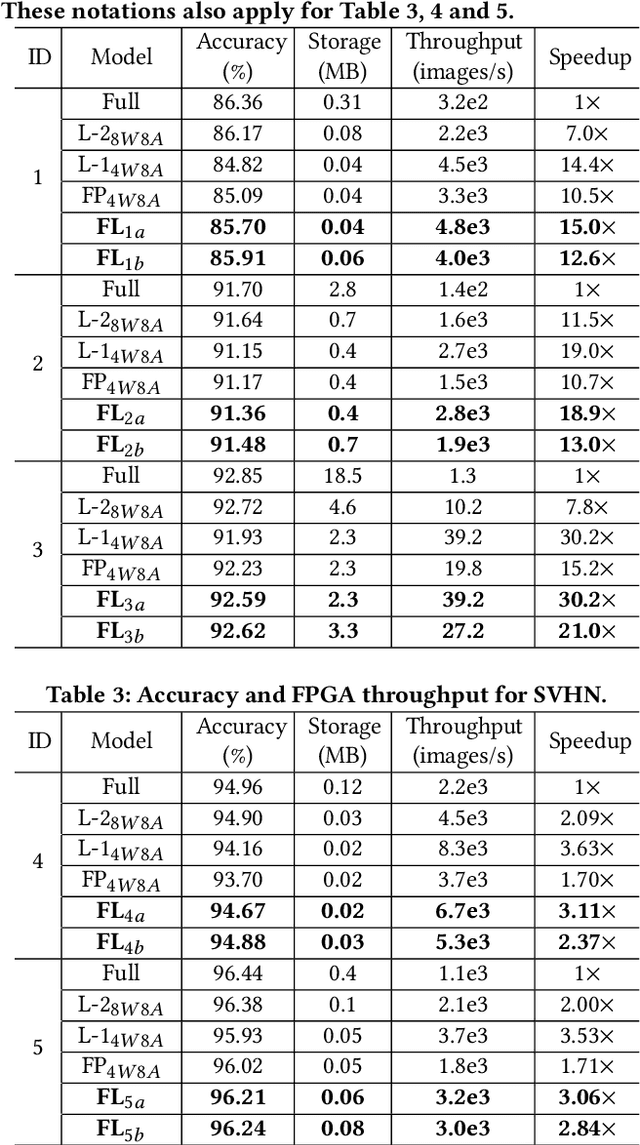
To improve the throughput and energy efficiency of Deep Neural Networks (DNNs) on customized hardware, lightweight neural networks constrain the weights of DNNs to be a limited combination (denoted as $k\in\{1,2\}$) of powers of 2. In such networks, the multiply-accumulate operation can be replaced with a single shift operation, or two shifts and an add operation. To provide even more design flexibility, the $k$ for each convolutional filter can be optimally chosen instead of being fixed for every filter. In this paper, we formulate the selection of $k$ to be differentiable, and describe model training for determining $k$-based weights on a per-filter basis. Over 46 FPGA-design experiments involving eight configurations and four data sets reveal that lightweight neural networks with a flexible $k$ value (dubbed FLightNNs) fully utilize the hardware resources on Field Programmable Gate Arrays (FPGAs), our experimental results show that FLightNNs can achieve 2$\times$ speedup when compared to lightweight NNs with $k=2$, with only 0.1\% accuracy degradation. Compared to a 4-bit fixed-point quantization, FLightNNs achieve higher accuracy and up to 2$\times$ inference speedup, due to their lightweight shift operations. In addition, our experiments also demonstrate that FLightNNs can achieve higher computational energy efficiency for ASIC implementation.
Regularizing Activation Distribution for Training Binarized Deep Networks
Apr 04, 2019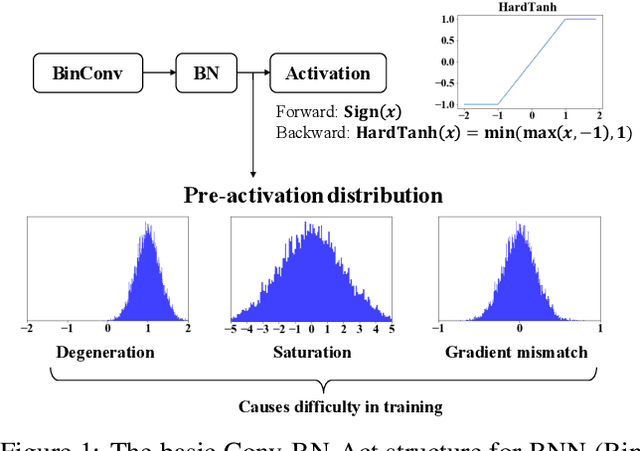
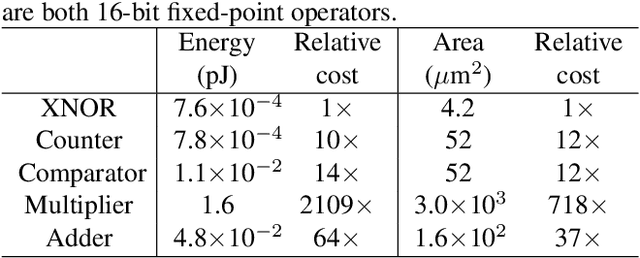
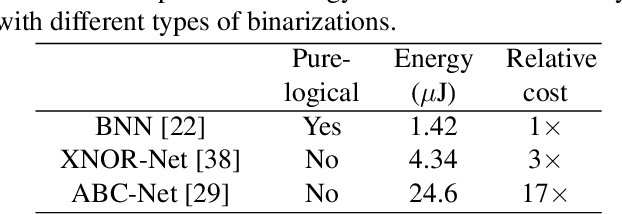
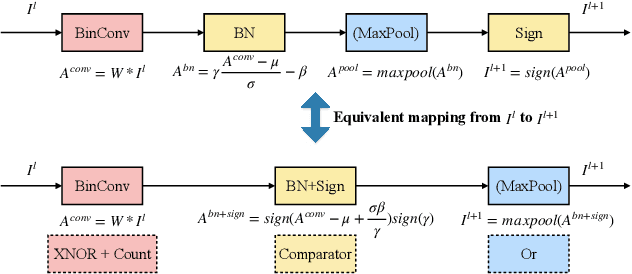
Binarized Neural Networks (BNNs) can significantly reduce the inference latency and energy consumption in resource-constrained devices due to their pure-logical computation and fewer memory accesses. However, training BNNs is difficult since the activation flow encounters degeneration, saturation, and gradient mismatch problems. Prior work alleviates these issues by increasing activation bits and adding floating-point scaling factors, thereby sacrificing BNN's energy efficiency. In this paper, we propose to use distribution loss to explicitly regularize the activation flow, and develop a framework to systematically formulate the loss. Our experiments show that the distribution loss can consistently improve the accuracy of BNNs without losing their energy benefits. Moreover, equipped with the proposed regularization, BNN training is shown to be robust to the selection of hyper-parameters including optimizer and learning rate.
AdaScale: Towards Real-time Video Object Detection Using Adaptive Scaling
Feb 08, 2019
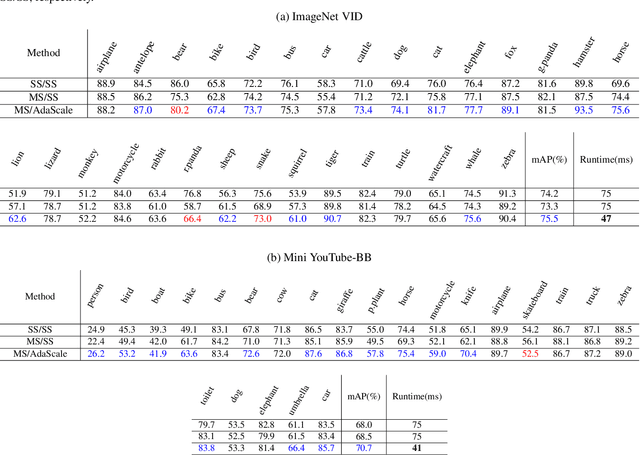

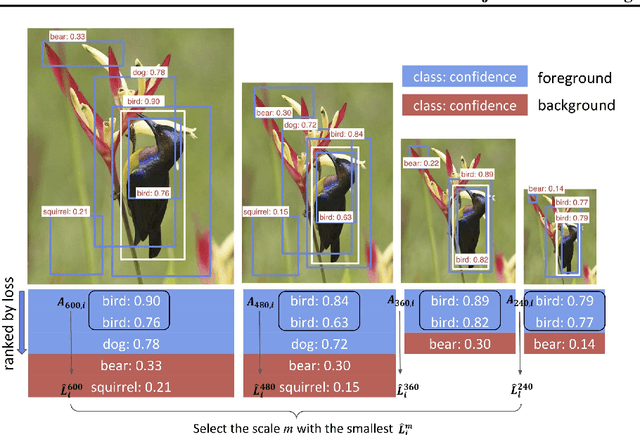
In vision-enabled autonomous systems such as robots and autonomous cars, video object detection plays a crucial role, and both its speed and accuracy are important factors to provide reliable operation. The key insight we show in this paper is that speed and accuracy are not necessarily a trade-off when it comes to image scaling. Our results show that re-scaling the image to a lower resolution will sometimes produce better accuracy. Based on this observation, we propose a novel approach, dubbed AdaScale, which adaptively selects the input image scale that improves both accuracy and speed for video object detection. To this end, our results on ImageNet VID and mini YouTube-BoundingBoxes datasets demonstrate 1.3 points and 2.7 points mAP improvement with 1.6x and 1.8x speedup, respectively. Additionally, we improve state-of-the-art video acceleration work by an extra 1.25x speedup with slightly better mAP on ImageNet VID dataset.
Understanding the Impact of Label Granularity on CNN-based Image Classification
Jan 21, 2019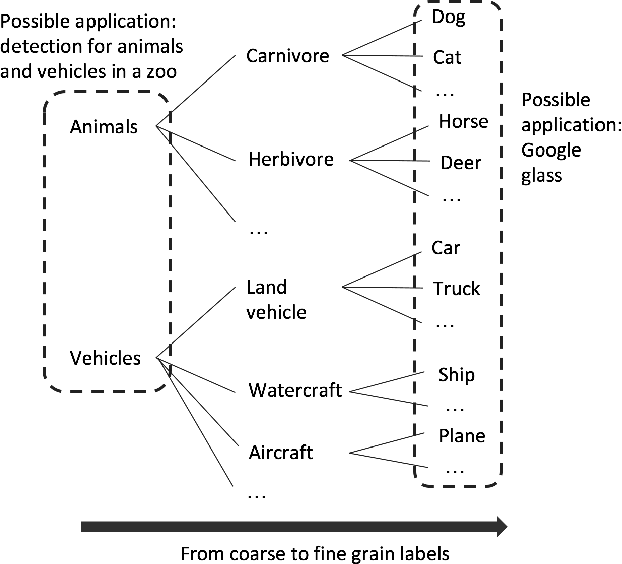
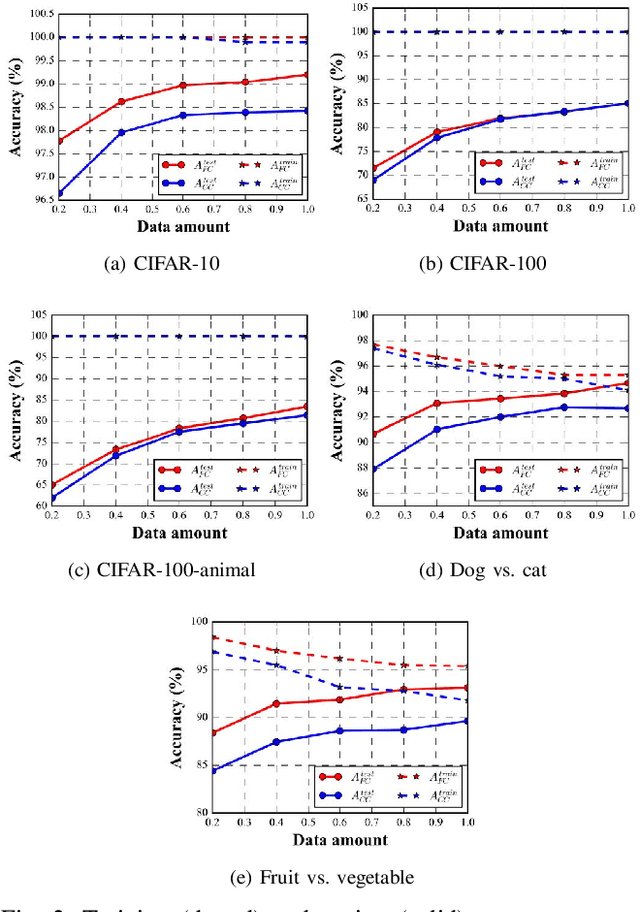
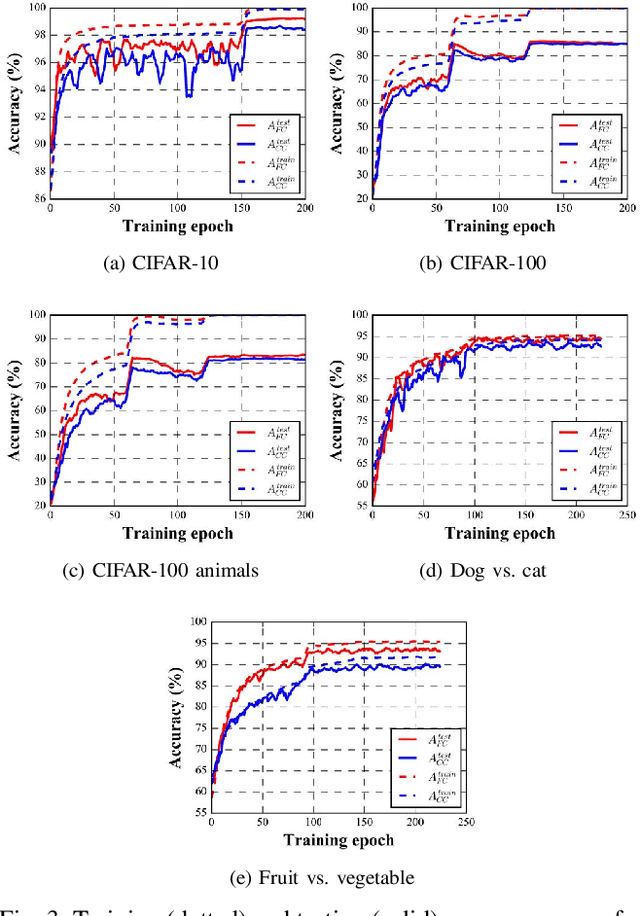
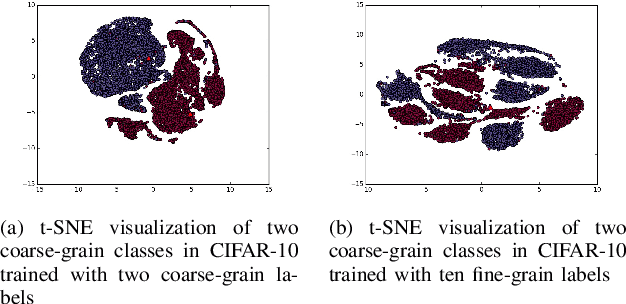
In recent years, supervised learning using Convolutional Neural Networks (CNNs) has achieved great success in image classification tasks, and large scale labeled datasets have contributed significantly to this achievement. However, the definition of a label is often application dependent. For example, an image of a cat can be labeled as "cat" or perhaps more specifically "Persian cat." We refer to this as label granularity. In this paper, we conduct extensive experiments using various datasets to demonstrate and analyze how and why training based on fine-grain labeling, such as "Persian cat" can improve CNN accuracy on classifying coarse-grain classes, in this case "cat." The experimental results show that training CNNs with fine-grain labels improves both network's optimization and generalization capabilities, as intuitively it encourages the network to learn more features, and hence increases classification accuracy on coarse-grain classes under all datasets considered. Moreover, fine-grain labels enhance data efficiency in CNN training. For example, a CNN trained with fine-grain labels and only 40% of the total training data can achieve higher accuracy than a CNN trained with the full training dataset and coarse-grain labels. These results point to two possible applications of this work: (i) with sufficient human resources, one can improve CNN performance by re-labeling the dataset with fine-grain labels, and (ii) with limited human resources, to improve CNN performance, rather than collecting more training data, one may instead use fine-grain labels for the dataset. We further propose a metric called Average Confusion Ratio to characterize the effectiveness of fine-grain labeling, and show its use through extensive experimentation. Code is available at https://github.com/cmu-enyac/Label-Granularity.