 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidth Transfer: On the variance of Width Optimization
Paper and Code
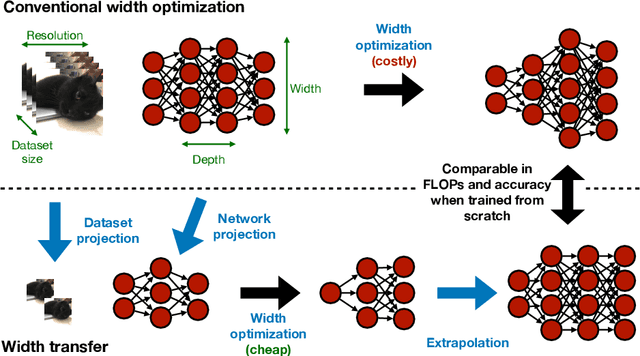

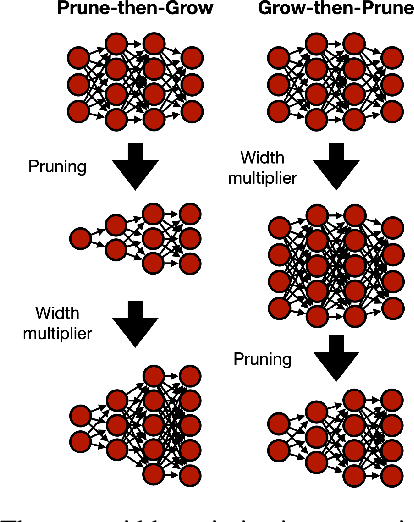
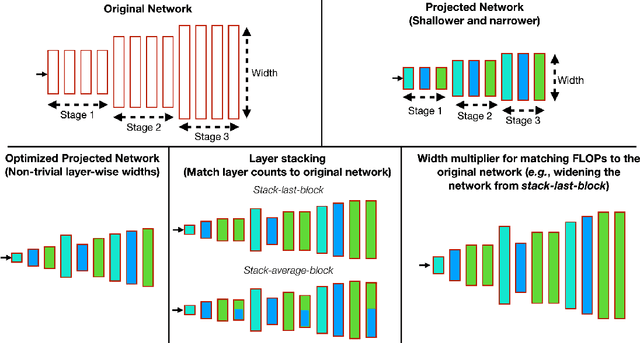
Optimizing the channel counts for different layers of a CNN has shown great promise in improving the efficiency of CNNs at test-time. However, these methods often introduce large computational overhead (e.g., an additional 2x FLOPs of standard training). Minimizing this overhead could therefore significantly speed up training. In this work, we propose width transfer, a technique that harnesses the assumptions that the optimized widths (or channel counts) are regular across sizes and depths. We show that width transfer works well across various width optimization algorithms and networks. Specifically, we can achieve up to 320x reduction in width optimization overhead without compromising the top-1 accuracy on ImageNet, making the additional cost of width optimization negligible relative to initial training. Our findings not only suggest an efficient way to conduct width optimization but also highlight that the widths that lead to better accuracy are invariant to various aspects of network architectures and training data.