 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Domain Specialization via Composable On-Package Architecture
Apr 05, 2021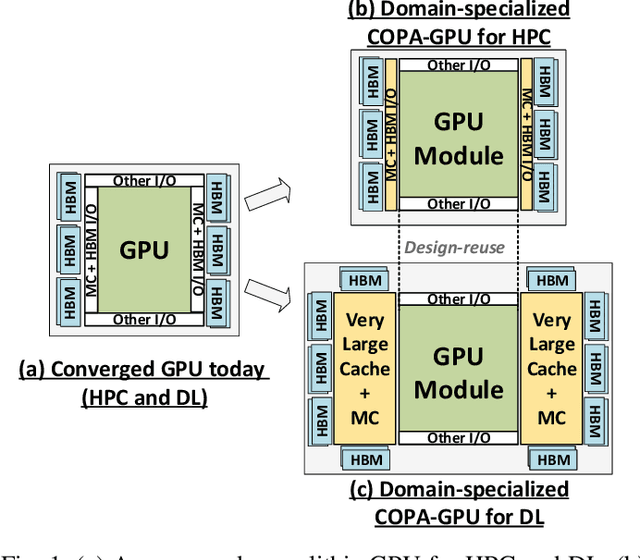
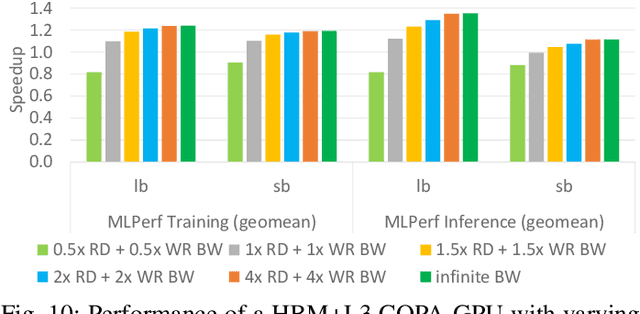
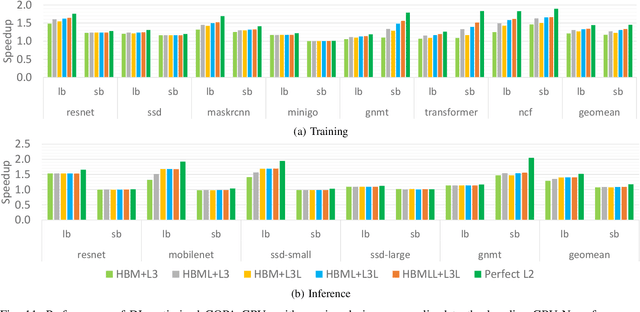
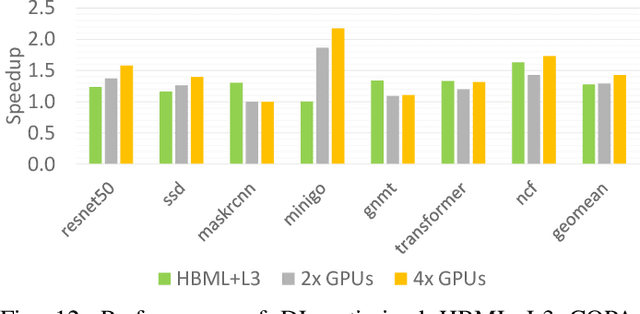
As GPUs scale their low precision matrix math throughput to boost deep learning (DL) performance, they upset the balance between math throughput and memory system capabilities. We demonstrate that converged GPU design trying to address diverging architectural requirements between FP32 (or larger) based HPC and FP16 (or smaller) based DL workloads results in sub-optimal configuration for either of the application domains. We argue that a Composable On-PAckage GPU (COPAGPU) architecture to provide domain-specialized GPU products is the most practical solution to these diverging requirements. A COPA-GPU leverages multi-chip-module disaggregation to support maximal design reuse, along with memory system specialization per application domain. We show how a COPA-GPU enables DL-specialized products by modular augmentation of the baseline GPU architecture with up to 4x higher off-die bandwidth, 32x larger on-package cache, 2.3x higher DRAM bandwidth and capacity, while conveniently supporting scaled-down HPC-oriented designs. This work explores the microarchitectural design necessary to enable composable GPUs and evaluates the benefits composability can provide to HPC, DL training, and DL inference. We show that when compared to a converged GPU design, a DL-optimized COPA-GPU featuring a combination of 16x larger cache capacity and 1.6x higher DRAM bandwidth scales per-GPU training and inference performance by 31% and 35% respectively and reduces the number of GPU instances by 50% in scale-out training scenarios.
DeLTA: GPU Performance Model for Deep Learning Applications with In-depth Memory System Traffic Analysis
Apr 02, 2019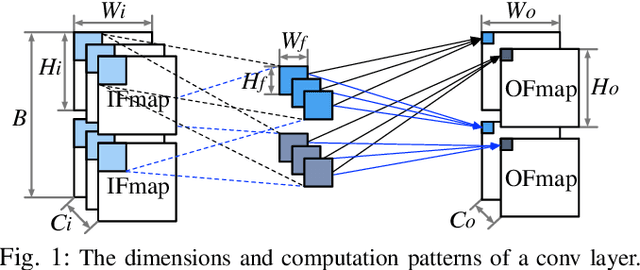
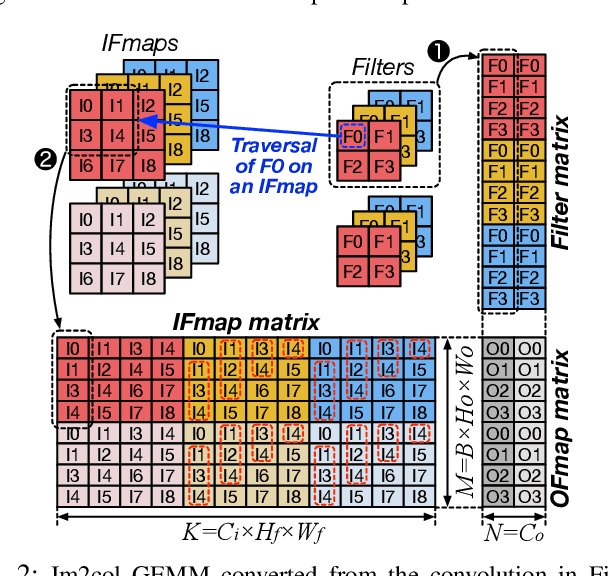
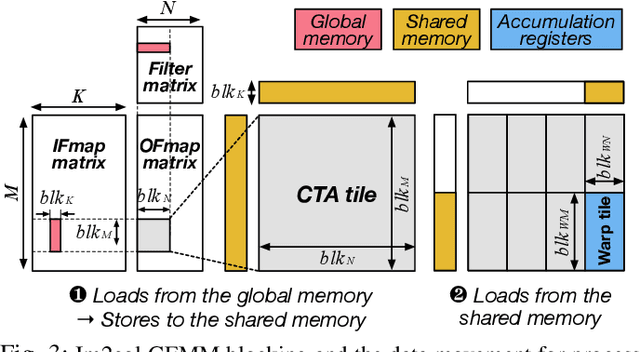
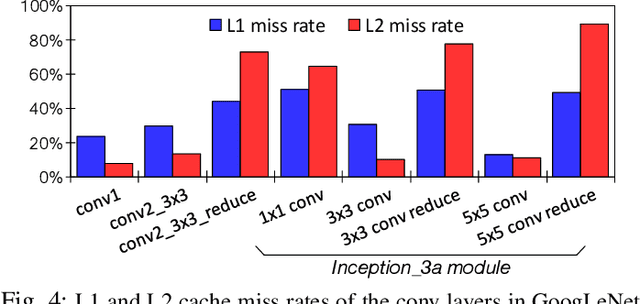
Training convolutional neural networks (CNNs) requires intense compute throughput and high memory bandwidth. Especially, convolution layers account for the majority of the execution time of CNN training, and GPUs are commonly used to accelerate these layer workloads. GPU design optimization for efficient CNN training acceleration requires the accurate modeling of how their performance improves when computing and memory resources are increased. We present DeLTA, the first analytical model that accurately estimates the traffic at each GPU memory hierarchy level, while accounting for the complex reuse patterns of a parallel convolution algorithm. We demonstrate that our model is both accurate and robust for different CNNs and GPU architectures. We then show how this model can be used to carefully balance the scaling of different GPU resources for efficient CNN performance improvement.
Compressing DMA Engine: Leveraging Activation Sparsity for Training Deep Neural Networks
May 03, 2017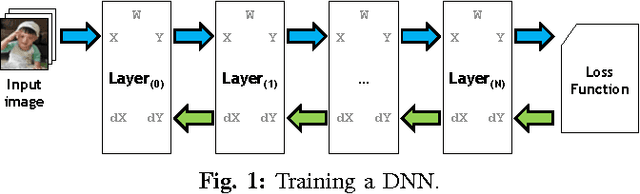
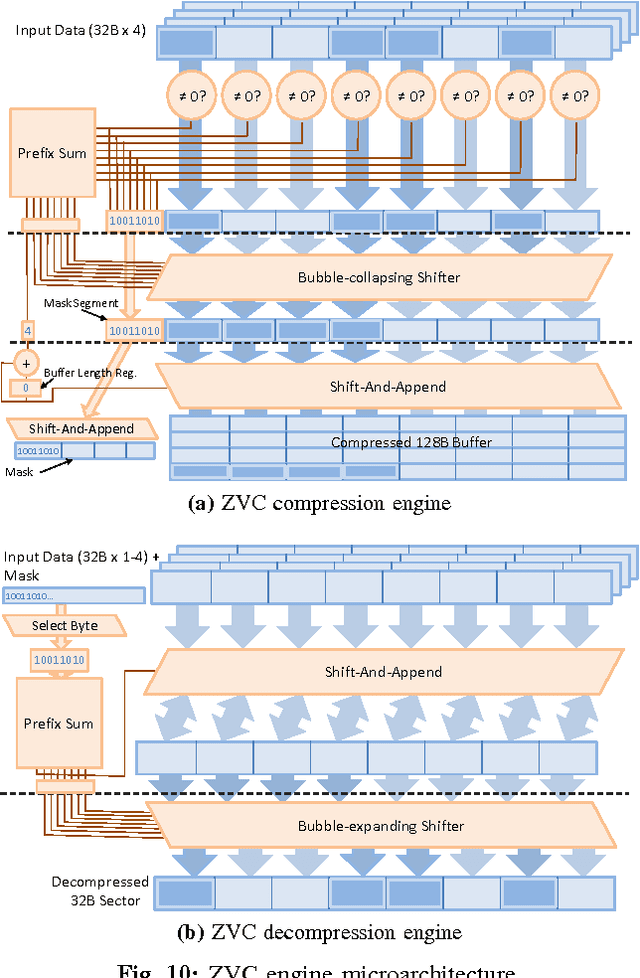
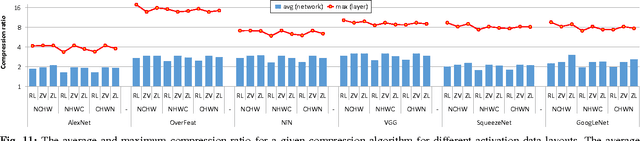

Popular deep learning frameworks require users to fine-tune their memory usage so that the training data of a deep neural network (DNN) fits within the GPU physical memory. Prior work tries to address this restriction by virtualizing the memory usage of DNNs, enabling both CPU and GPU memory to be utilized for memory allocations. Despite its merits, virtualizing memory can incur significant performance overheads when the time needed to copy data back and forth from CPU memory is higher than the latency to perform the computations required for DNN forward and backward propagation. We introduce a high-performance virtualization strategy based on a "compressing DMA engine" (cDMA) that drastically reduces the size of the data structures that are targeted for CPU-side allocations. The cDMA engine offers an average 2.6x (maximum 13.8x) compression ratio by exploiting the sparsity inherent in offloaded data, improving the performance of virtualized DNNs by an average 32% (maximum 61%).