 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeLTA: GPU Performance Model for Deep Learning Applications with In-depth Memory System Traffic Analysis
Paper and Code
Apr 02, 2019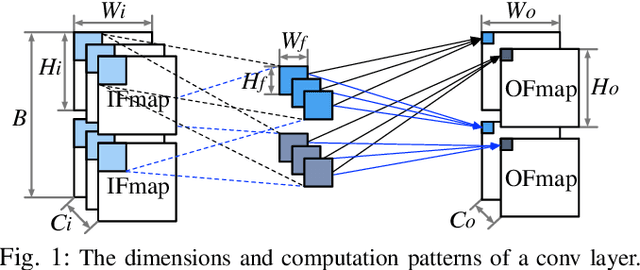
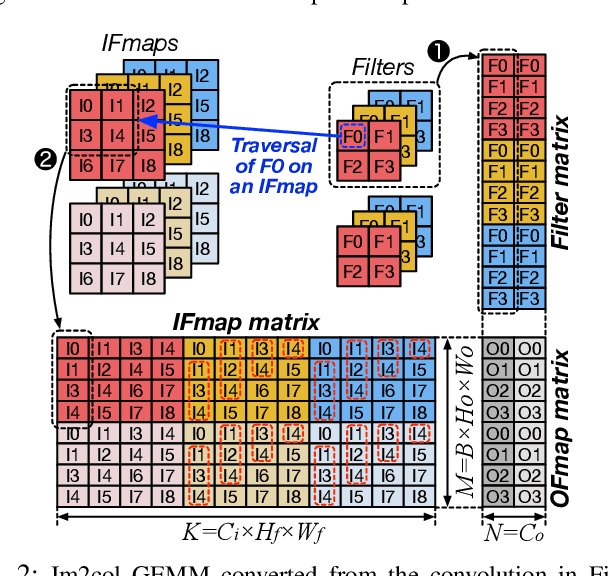
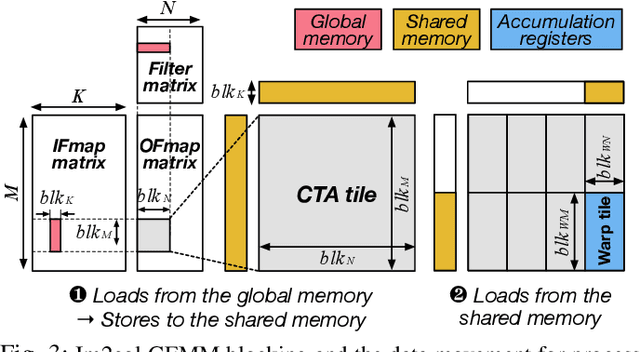
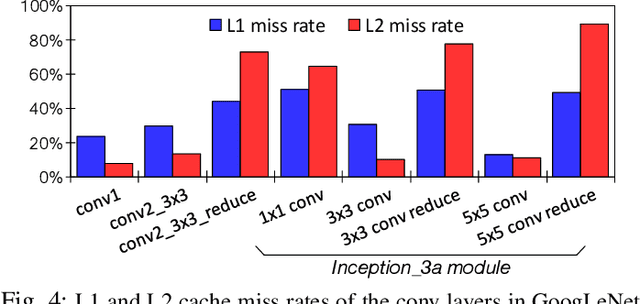
Training convolutional neural networks (CNNs) requires intense compute throughput and high memory bandwidth. Especially, convolution layers account for the majority of the execution time of CNN training, and GPUs are commonly used to accelerate these layer workloads. GPU design optimization for efficient CNN training acceleration requires the accurate modeling of how their performance improves when computing and memory resources are increased. We present DeLTA, the first analytical model that accurately estimates the traffic at each GPU memory hierarchy level, while accounting for the complex reuse patterns of a parallel convolution algorithm. We demonstrate that our model is both accurate and robust for different CNNs and GPU architectures. We then show how this model can be used to carefully balance the scaling of different GPU resources for efficient CNN performance improvement.