 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtemis: HE-Aware Training for Efficient Privacy-Preserving Machine Learning
Oct 02, 2023

Privacy-Preserving ML (PPML) based on Homomorphic Encryption (HE) is a promising foundational privacy technology. Making it more practical requires lowering its computational cost, especially, in handling modern large deep neural networks. Model compression via pruning is highly effective in conventional plaintext ML but cannot be effectively applied to HE-PPML as is. We propose Artemis, a highly effective DNN pruning technique for HE-based inference. We judiciously investigate two HE-aware pruning strategies (positional and diagonal) to reduce the number of Rotation operations, which dominate compute time in HE convolution. We find that Pareto-optimal solutions are based fully on diagonal pruning. Artemis' benefits come from coupling DNN training, driven by a novel group Lasso regularization objective, with pruning to maximize HE-specific cost reduction (dominated by the Rotation operations). We show that Artemis improves on prior HE-oriented pruning and can achieve a 1.2-6x improvement when targeting modern convolutional models (ResNet18 and ResNet18) across three datasets.
Enhancing Cross-Category Learning in Recommendation Systems with Multi-Layer Embedding Training
Sep 27, 2023



Modern DNN-based recommendation systems rely on training-derived embeddings of sparse features. Input sparsity makes obtaining high-quality embeddings for rarely-occurring categories harder as their representations are updated infrequently. We demonstrate a training-time technique to produce superior embeddings via effective cross-category learning and theoretically explain its surprising effectiveness. The scheme, termed the multi-layer embeddings training (MLET), trains embeddings using factorization of the embedding layer, with an inner dimension higher than the target embedding dimension. For inference efficiency, MLET converts the trained two-layer embedding into a single-layer one thus keeping inference-time model size unchanged. Empirical superiority of MLET is puzzling as its search space is not larger than that of the single-layer embedding. The strong dependence of MLET on the inner dimension is even more surprising. We develop a theory that explains both of these behaviors by showing that MLET creates an adaptive update mechanism modulated by the singular vectors of embeddings. When tested on multiple state-of-the-art recommendation models for click-through rate (CTR) prediction tasks, MLET consistently produces better models, especially for rare items. At constant model quality, MLET allows embedding dimension, and model size, reduction by up to 16x, and 5.8x on average, across the models.
Training with Multi-Layer Embeddings for Model Reduction
Jun 10, 2020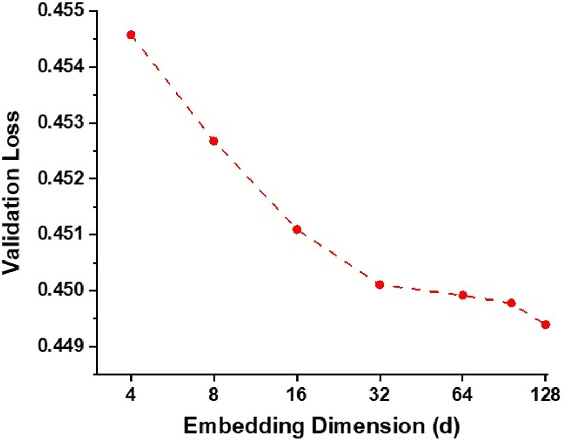

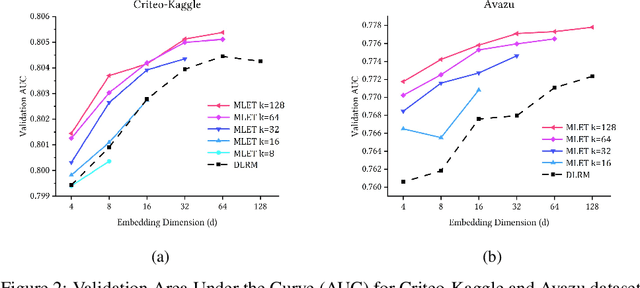
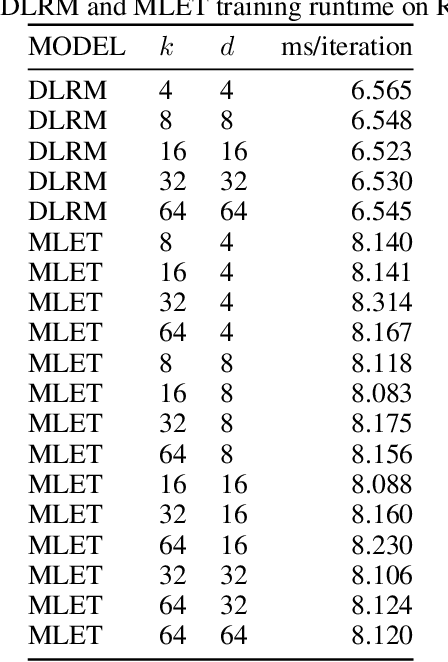
Modern recommendation systems rely on real-valued embeddings of categorical features. Increasing the dimension of embedding vectors improves model accuracy but comes at a high cost to model size. We introduce a multi-layer embedding training (MLET) architecture that trains embeddings via a sequence of linear layers to derive superior embedding accuracy vs. model size trade-off. Our approach is fundamentally based on the ability of factorized linear layers to produce superior embeddings to that of a single linear layer. We focus on the analysis and implementation of a two-layer scheme. Harnessing the recent results in dynamics of backpropagation in linear neural networks, we explain the ability to get superior multi-layer embeddings via their tendency to have lower effective rank. We show that substantial advantages are obtained in the regime where the width of the hidden layer is much larger than that of the final embedding (d). Crucially, at conclusion of training, we convert the two-layer solution into a single-layer one: as a result, the inference-time model size scales as d. We prototype the MLET scheme within Facebook's PyTorch-based open-source Deep Learning Recommendation Model. We show that it allows reducing d by 4-8X, with a corresponding improvement in memory footprint, at given model accuracy. The experiments are run on two publicly available click-through-rate prediction benchmarks (Criteo-Kaggle and Avazu). The runtime cost of MLET is 25%, on average.
FlexSA: Flexible Systolic Array Architecture for Efficient Pruned DNN Model Training
Apr 27, 2020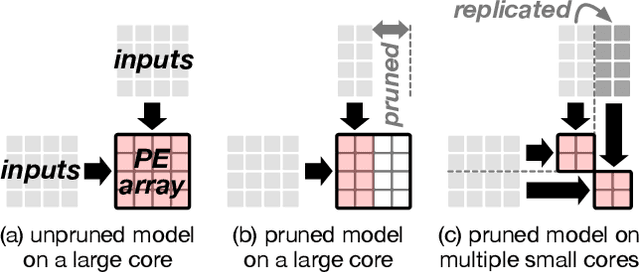
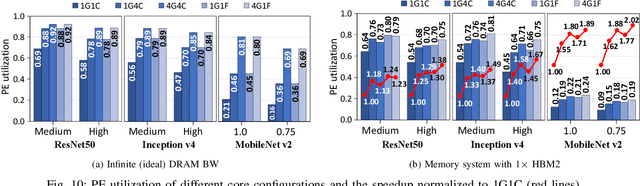
Modern deep learning models have high memory and computation cost. To make them fast and memory-cost efficient, structured model pruning is commonly used. We find that pruning a model using a common training accelerator with large systolic arrays is extremely performance-inefficient. To make a systolic array efficient for pruning and training, we propose FlexSA, a flexible systolic array architecture. FlexSA dynamically reconfigures the systolic array structure and offers multiple sub-systolic operating modes, which are designed for energy- and memory bandwidth-efficient processing of tensors with different sizes and shapes. We also present a compilation heuristic for tiling matrix-multiplication-and-accumulation operations in a training workload to best utilize the resources of FlexSA. Based on our evaluation, FlexSA with the proposed compilation heuristic improves compute resource utilization of pruning and training modern CNN models by 37% compared to a conventional training accelerator with a large systolic array. FlexSA also improves on-chip data reuse by 1.7X saving 28% energy compared to naive systolic array splitting.
DeLTA: GPU Performance Model for Deep Learning Applications with In-depth Memory System Traffic Analysis
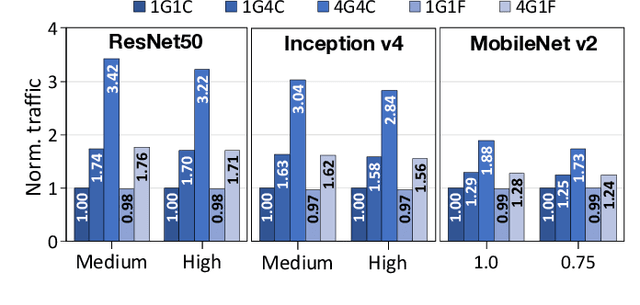
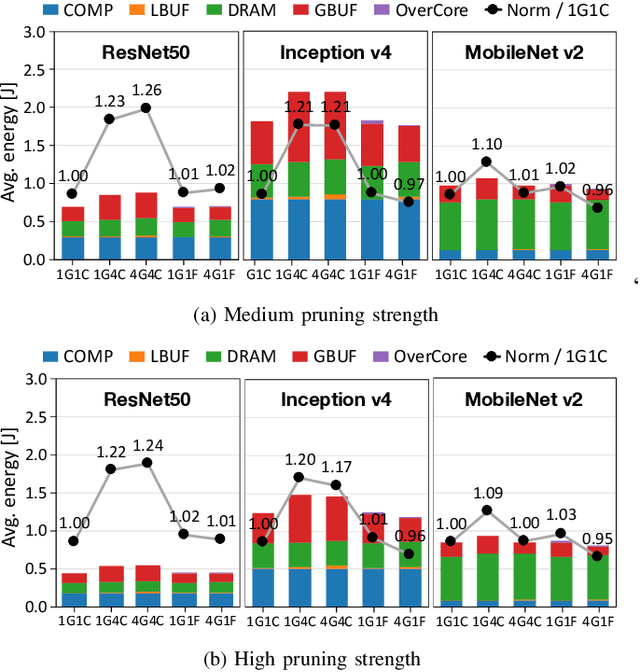
Apr 02, 2019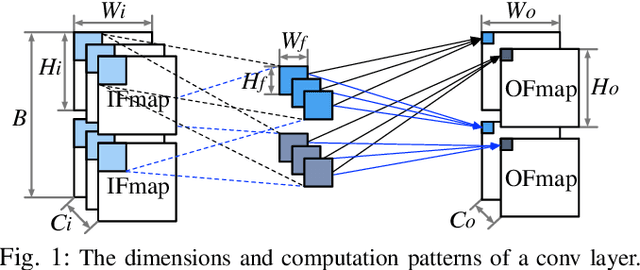
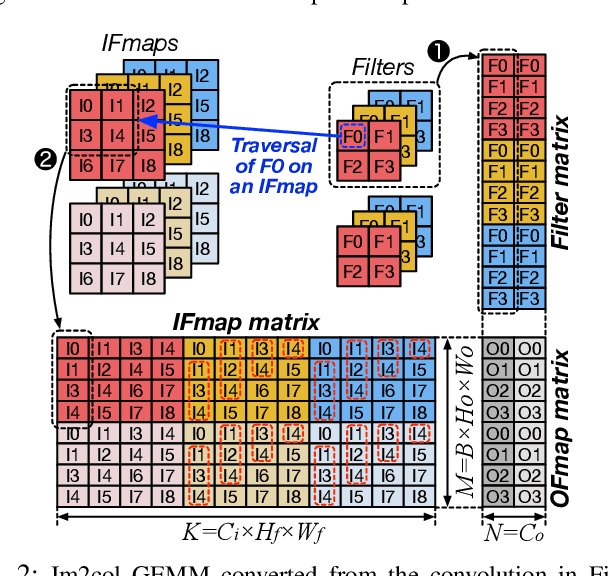
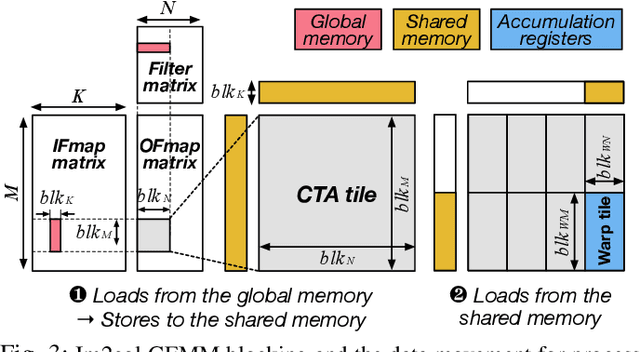
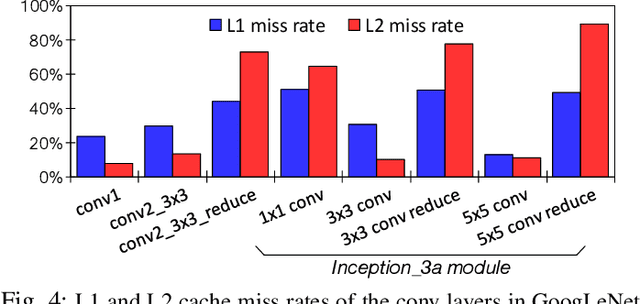
Training convolutional neural networks (CNNs) requires intense compute throughput and high memory bandwidth. Especially, convolution layers account for the majority of the execution time of CNN training, and GPUs are commonly used to accelerate these layer workloads. GPU design optimization for efficient CNN training acceleration requires the accurate modeling of how their performance improves when computing and memory resources are increased. We present DeLTA, the first analytical model that accurately estimates the traffic at each GPU memory hierarchy level, while accounting for the complex reuse patterns of a parallel convolution algorithm. We demonstrate that our model is both accurate and robust for different CNNs and GPU architectures. We then show how this model can be used to carefully balance the scaling of different GPU resources for efficient CNN performance improvement.
PruneTrain: Gradual Structured Pruning from Scratch for Faster Neural Network Training
Jan 26, 2019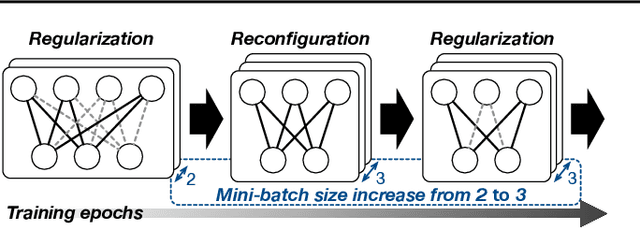
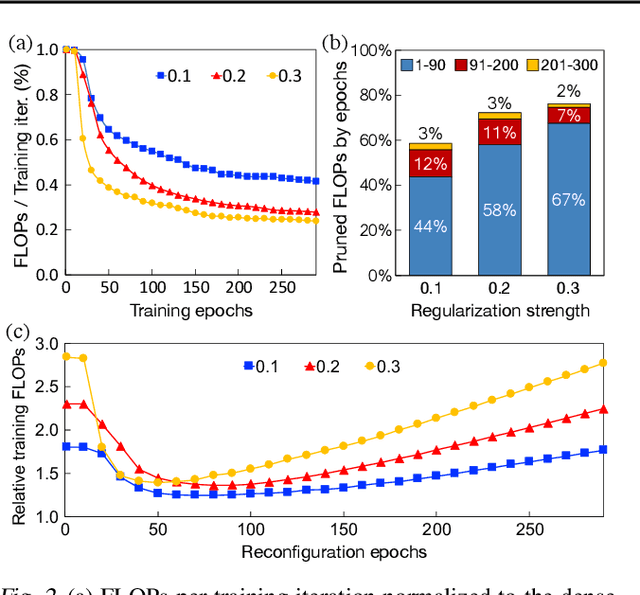
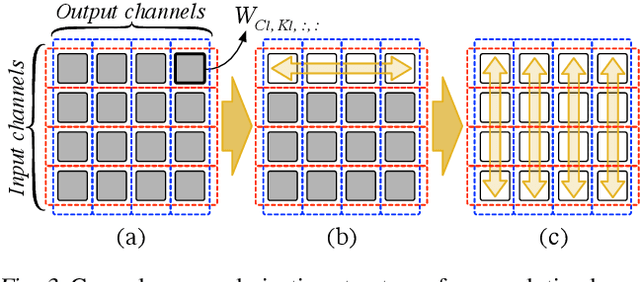
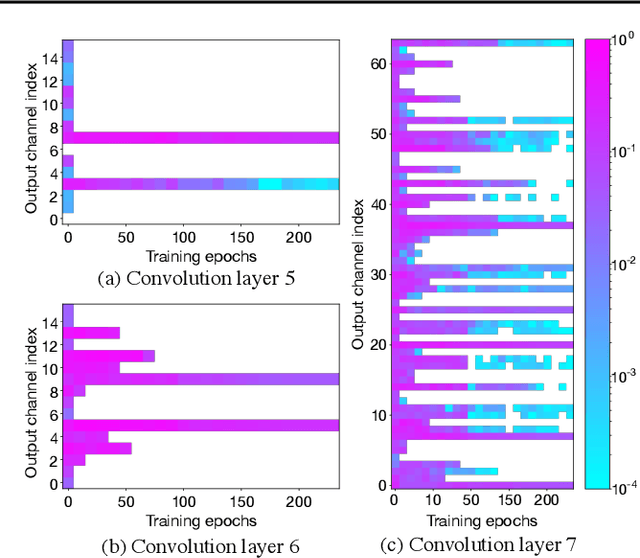
Model pruning is a popular mechanism to make a network more efficient for inference. In this paper, we explore the use of pruning to also make the training of such neural networks more efficient. Unlike all prior model pruning methods that sparsify a pre-trained model and then prune it, we train the network from scratch, while gradually and structurally pruning parameters during the training. We build on our key observations: 1) once parameters are sparsified via regularization, they rarely re-appear in later steps, and 2) setting the appropriate regularization penalty at the beginning of training effectively converges the loss. We train ResNet and VGG networks on CIFAR10/100 and ImageNet datasets from scratch, and achieve 30-50% improvement in training FLOPs and 20-30% improvement in measured training time on modern GPUs.
Mini-batch Serialization: CNN Training with Inter-layer Data Reuse
Sep 30, 2018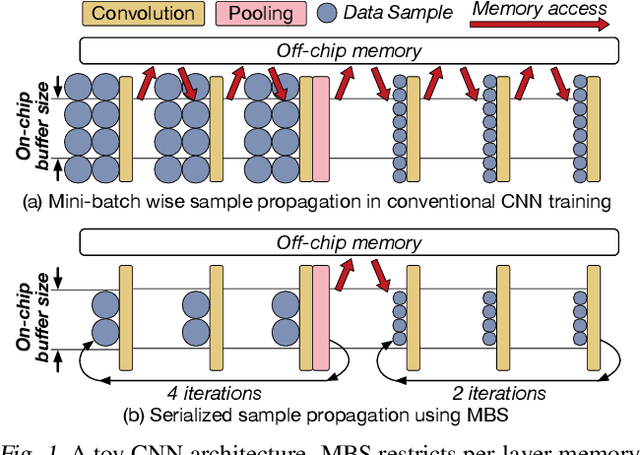
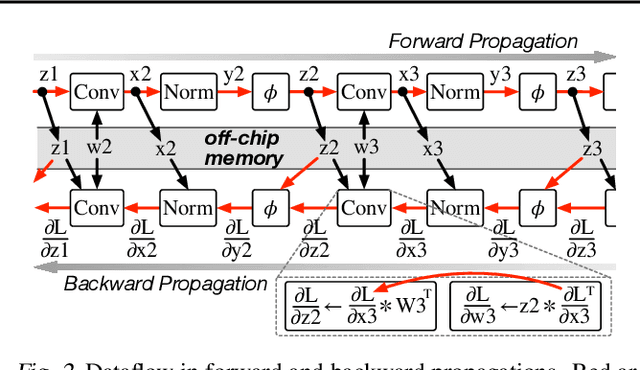
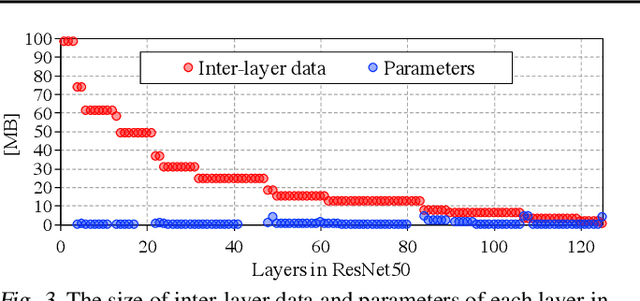
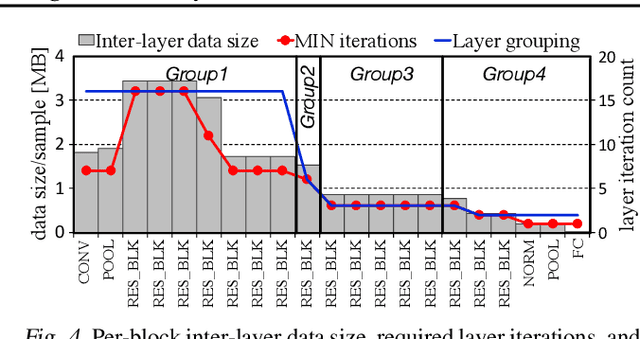
Training convolutional neural networks (CNNs) requires intense computations and high memory bandwidth. We find that bandwidth today is over-provisioned because most memory accesses in CNN training can be eliminated by rearranging computation to better utilize on-chip buffers and avoid traffic resulting from large per-layer memory footprints. We introduce the MBS CNN training approach that significantly reduces memory traffic by partially serializing mini-batch processing across groups of layers. This optimizes reuse within on-chip buffers and balances both intra-layer and inter-layer reuse. We also introduce the WaveCore CNN training accelerator that effectively trains CNNs in the MBS approach with high functional-unit utilization. Combined, WaveCore and MBS reduce DRAM traffic by 73%, improve performance by 45%, and save 24% system energy for modern deep CNN training compared to conventional training mechanisms and accelerators.