 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtemis: HE-Aware Training for Efficient Privacy-Preserving Machine Learning
Paper and Code
Oct 02, 2023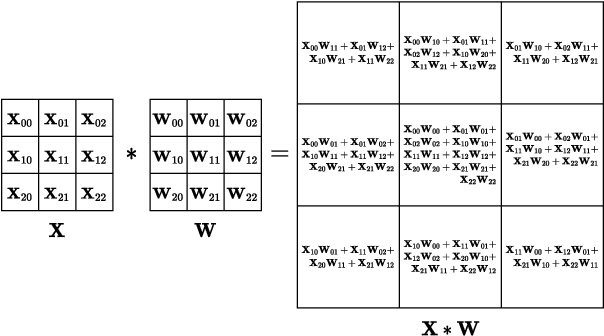
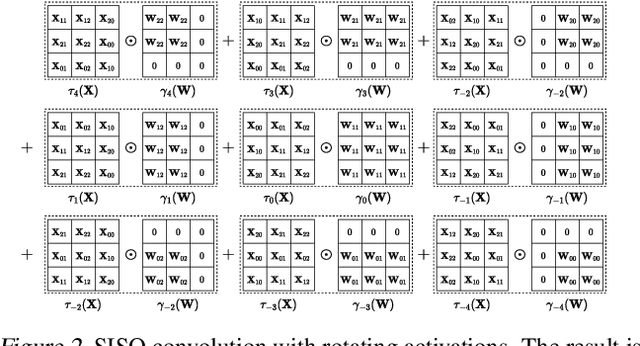

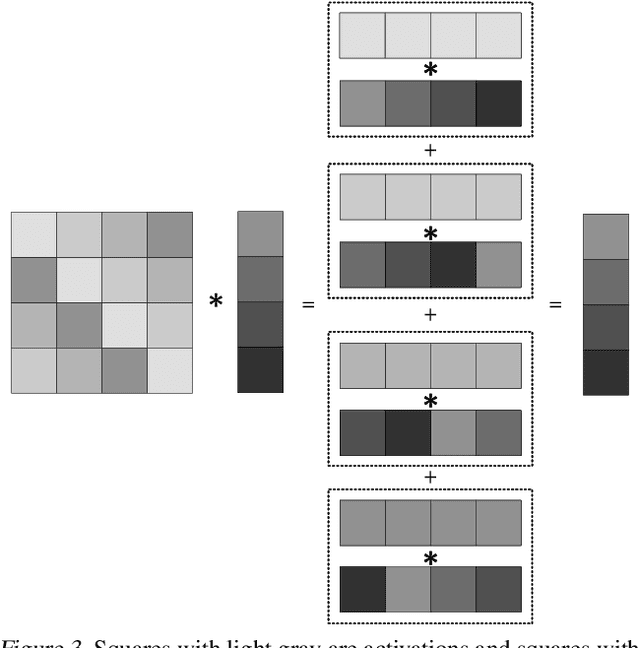
Privacy-Preserving ML (PPML) based on Homomorphic Encryption (HE) is a promising foundational privacy technology. Making it more practical requires lowering its computational cost, especially, in handling modern large deep neural networks. Model compression via pruning is highly effective in conventional plaintext ML but cannot be effectively applied to HE-PPML as is. We propose Artemis, a highly effective DNN pruning technique for HE-based inference. We judiciously investigate two HE-aware pruning strategies (positional and diagonal) to reduce the number of Rotation operations, which dominate compute time in HE convolution. We find that Pareto-optimal solutions are based fully on diagonal pruning. Artemis' benefits come from coupling DNN training, driven by a novel group Lasso regularization objective, with pruning to maximize HE-specific cost reduction (dominated by the Rotation operations). We show that Artemis improves on prior HE-oriented pruning and can achieve a 1.2-6x improvement when targeting modern convolutional models (ResNet18 and ResNet18) across three datasets.