 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtemis: HE-Aware Training for Efficient Privacy-Preserving Machine Learning
Oct 02, 2023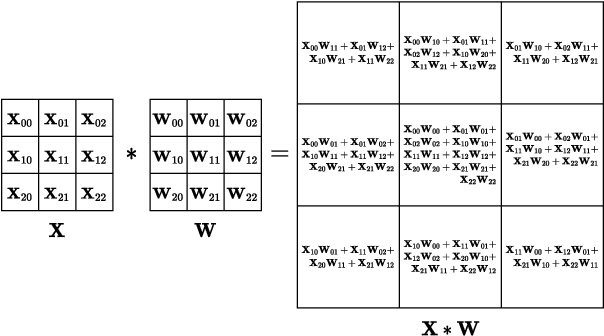
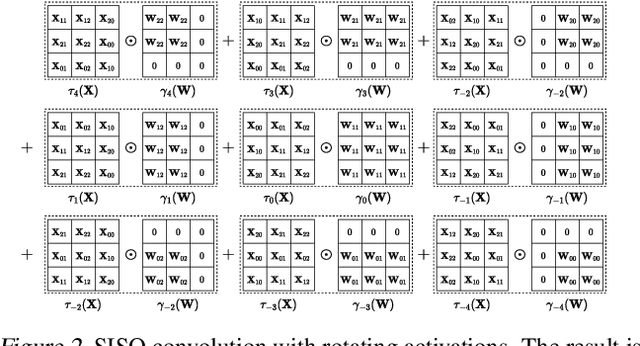

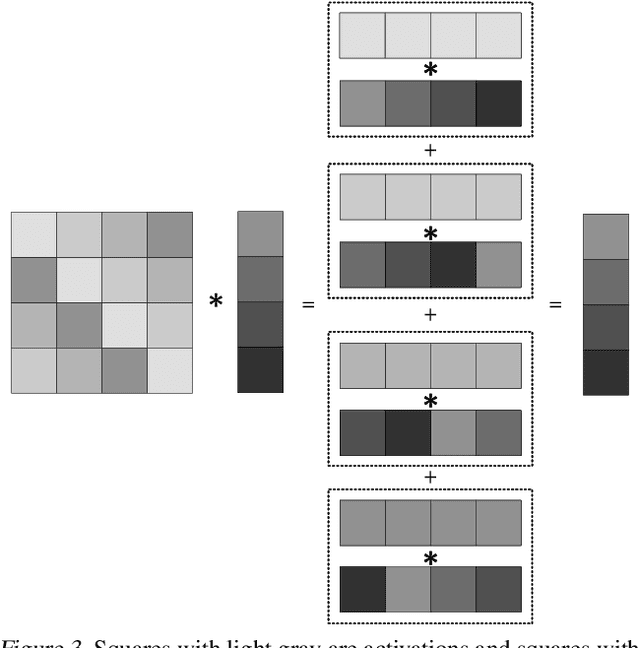
Privacy-Preserving ML (PPML) based on Homomorphic Encryption (HE) is a promising foundational privacy technology. Making it more practical requires lowering its computational cost, especially, in handling modern large deep neural networks. Model compression via pruning is highly effective in conventional plaintext ML but cannot be effectively applied to HE-PPML as is. We propose Artemis, a highly effective DNN pruning technique for HE-based inference. We judiciously investigate two HE-aware pruning strategies (positional and diagonal) to reduce the number of Rotation operations, which dominate compute time in HE convolution. We find that Pareto-optimal solutions are based fully on diagonal pruning. Artemis' benefits come from coupling DNN training, driven by a novel group Lasso regularization objective, with pruning to maximize HE-specific cost reduction (dominated by the Rotation operations). We show that Artemis improves on prior HE-oriented pruning and can achieve a 1.2-6x improvement when targeting modern convolutional models (ResNet18 and ResNet18) across three datasets.
Enhancing Cross-Category Learning in Recommendation Systems with Multi-Layer Embedding Training
Sep 27, 2023



Modern DNN-based recommendation systems rely on training-derived embeddings of sparse features. Input sparsity makes obtaining high-quality embeddings for rarely-occurring categories harder as their representations are updated infrequently. We demonstrate a training-time technique to produce superior embeddings via effective cross-category learning and theoretically explain its surprising effectiveness. The scheme, termed the multi-layer embeddings training (MLET), trains embeddings using factorization of the embedding layer, with an inner dimension higher than the target embedding dimension. For inference efficiency, MLET converts the trained two-layer embedding into a single-layer one thus keeping inference-time model size unchanged. Empirical superiority of MLET is puzzling as its search space is not larger than that of the single-layer embedding. The strong dependence of MLET on the inner dimension is even more surprising. We develop a theory that explains both of these behaviors by showing that MLET creates an adaptive update mechanism modulated by the singular vectors of embeddings. When tested on multiple state-of-the-art recommendation models for click-through rate (CTR) prediction tasks, MLET consistently produces better models, especially for rare items. At constant model quality, MLET allows embedding dimension, and model size, reduction by up to 16x, and 5.8x on average, across the models.
Mixed-Precision Quantization with Cross-Layer Dependencies
Jul 11, 2023



Quantization is commonly used to compress and accelerate deep neural networks. Quantization assigning the same bit-width to all layers leads to large accuracy degradation at low precision and is wasteful at high precision settings. Mixed-precision quantization (MPQ) assigns varied bit-widths to layers to optimize the accuracy-efficiency trade-off. Existing methods simplify the MPQ problem by assuming that quantization errors at different layers act independently. We show that this assumption does not reflect the true behavior of quantized deep neural networks. We propose the first MPQ algorithm that captures the cross-layer dependency of quantization error. Our algorithm (CLADO) enables a fast approximation of pairwise cross-layer error terms by solving linear equations that require only forward evaluations of the network on a small amount of data. Decisions on layerwise bit-width assignments are then determined by optimizing a new MPQ formulation dependent on these cross-layer quantization errors via the Integer Quadratic Program (IQP), which can be solved within seconds. We conduct experiments on multiple networks on the Imagenet dataset and demonstrate an improvement, in top-1 classification accuracy, of up to 27% over uniform precision quantization, and up to 15% over existing MPQ methods.
A Provably Secure Strong PUF based on LWE: Construction and Implementation
Mar 05, 2023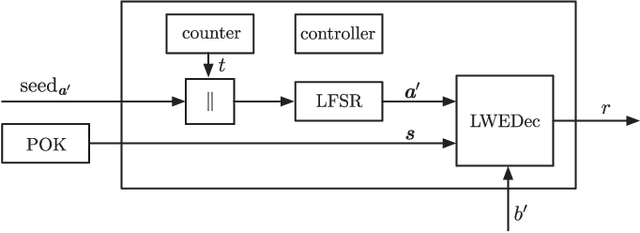

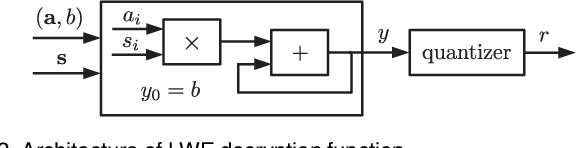

We construct a strong PUF with provable security against ML attacks on both classical and quantum computers. The security is guaranteed by the cryptographic hardness of learning decryption functions of public-key cryptosystems, and the hardness of the learning-with-errors (LWE) problem defined on integer lattices. We call our construction the lattice PUF. We construct lattice PUF with a physically obfuscated key and an LWE decryption function block. To allow deployments in different scenarios, we demonstrate designs with different latency-area trade-offs. A compact design uses a highly serialized LFSR and LWE decryption function, while a latency-optimized design uses an unrolled LFSR and a parallel datapath. We prototype lattice PUF designs with $2^{136}$ challenge-response pairs (CRPs) on a Spartan 6 FPGA. In addition to theoretical security guarantee, we evaluate empirical resistance to the various leading ML techniques: the prediction error remains above $49.76\%$ after $1$ million training CRPs. The resource-efficient design requires only $45$ slices for the PUF logic proper, and $351$ slices for a fuzzy extractor. The latency-optimized design achieves a $148X$ reduction in latency, at a $10X$ increase in PUF hardware utilization. The mean uniformity of PUF responses is $49.98\%$, the mean uniqueness is $50.00\%$, and the mean reliability is $1.26\%$.
Variability-Aware Training and Self-Tuning of Highly Quantized DNNs for Analog PIM
Nov 11, 2021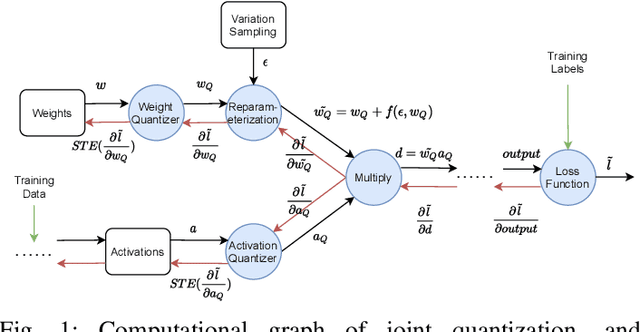



DNNs deployed on analog processing in memory (PIM) architectures are subject to fabrication-time variability. We developed a new joint variability- and quantization-aware DNN training algorithm for highly quantized analog PIM-based models that is significantly more effective than prior work. It outperforms variability-oblivious and post-training quantized models on multiple computer vision datasets/models. For low-bitwidth models and high variation, the gain in accuracy is up to 35.7% for ResNet-18 over the best alternative. We demonstrate that, under a realistic pattern of within- and between-chip components of variability, training alone is unable to prevent large DNN accuracy loss (of up to 54% on CIFAR-100/ResNet-18). We introduce a self-tuning DNN architecture that dynamically adjusts layer-wise activations during inference and is effective in reducing accuracy loss to below 10%.
Power-Based Attacks on Spatial DNN Accelerators
Aug 28, 2021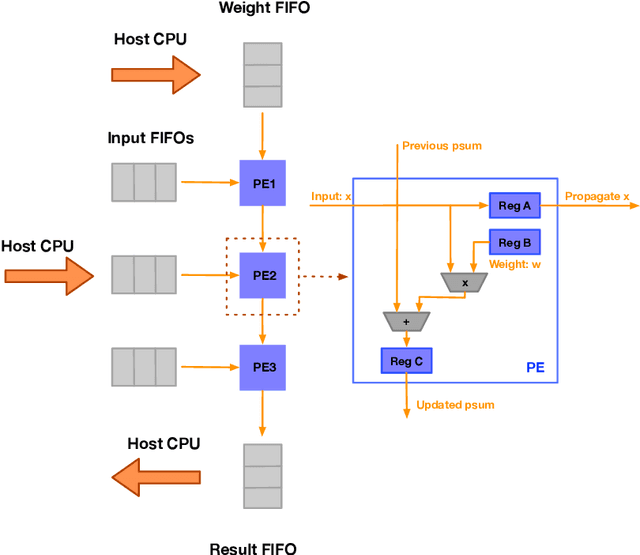

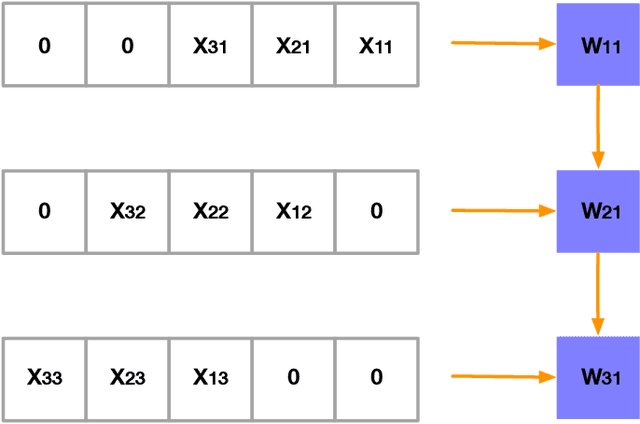
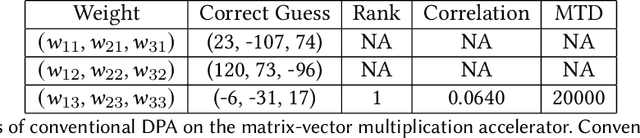
With proliferation of DNN-based applications, the confidentiality of DNN model is an important commercial goal. Spatial accelerators, that parallelize matrix/vector operations, are utilized for enhancing energy efficiency of DNN computation. Recently, model extraction attacks on simple accelerators, either with a single processing element or running a binarized network, were demonstrated using the methodology derived from differential power analysis (DPA) attack on cryptographic devices. This paper investigates the vulnerability of realistic spatial accelerators using general, 8-bit, number representation. We investigate two systolic array architectures with weight-stationary dataflow: (1) a 3 $\times$ 1 array for a dot-product operation, and (2) a 3 $\times$ 3 array for matrix-vector multiplication. Both are implemented on the SAKURA-G FPGA board. We show that both architectures are ultimately vulnerable. A conventional DPA succeeds fully on the 1D array, requiring 20K power measurements. However, the 2D array exhibits higher security even with 460K traces. We show that this is because the 2D array intrinsically entails multiple MACs simultaneously dependent on the same input. However, we find that a novel template-based DPA with multiple profiling phases is able to fully break the 2D array with only 40K traces. Corresponding countermeasures need to be investigated for spatial DNN accelerators.
Training with Multi-Layer Embeddings for Model Reduction
Jun 10, 2020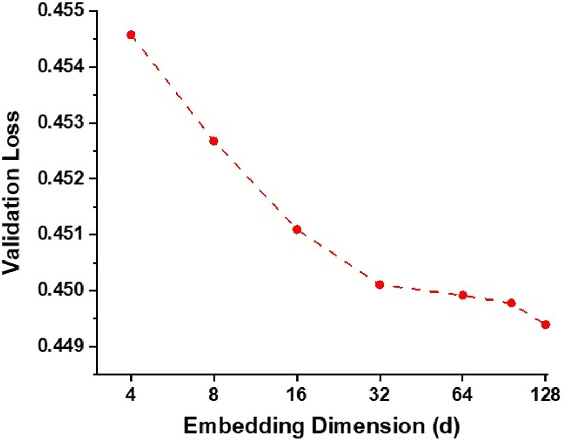

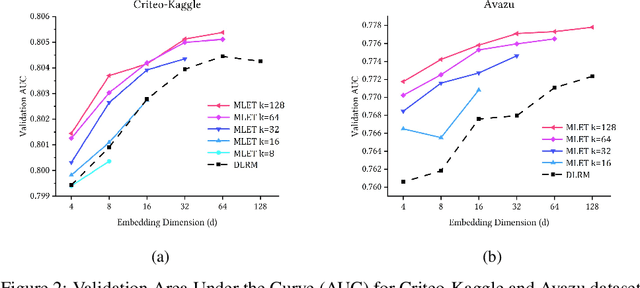
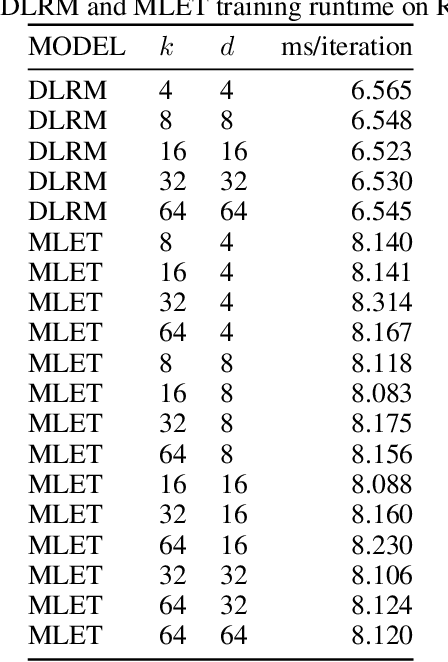
Modern recommendation systems rely on real-valued embeddings of categorical features. Increasing the dimension of embedding vectors improves model accuracy but comes at a high cost to model size. We introduce a multi-layer embedding training (MLET) architecture that trains embeddings via a sequence of linear layers to derive superior embedding accuracy vs. model size trade-off. Our approach is fundamentally based on the ability of factorized linear layers to produce superior embeddings to that of a single linear layer. We focus on the analysis and implementation of a two-layer scheme. Harnessing the recent results in dynamics of backpropagation in linear neural networks, we explain the ability to get superior multi-layer embeddings via their tendency to have lower effective rank. We show that substantial advantages are obtained in the regime where the width of the hidden layer is much larger than that of the final embedding (d). Crucially, at conclusion of training, we convert the two-layer solution into a single-layer one: as a result, the inference-time model size scales as d. We prototype the MLET scheme within Facebook's PyTorch-based open-source Deep Learning Recommendation Model. We show that it allows reducing d by 4-8X, with a corresponding improvement in memory footprint, at given model accuracy. The experiments are run on two publicly available click-through-rate prediction benchmarks (Criteo-Kaggle and Avazu). The runtime cost of MLET is 25%, on average.