 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Cross-Category Learning in Recommendation Systems with Multi-Layer Embedding Training
Sep 27, 2023



Modern DNN-based recommendation systems rely on training-derived embeddings of sparse features. Input sparsity makes obtaining high-quality embeddings for rarely-occurring categories harder as their representations are updated infrequently. We demonstrate a training-time technique to produce superior embeddings via effective cross-category learning and theoretically explain its surprising effectiveness. The scheme, termed the multi-layer embeddings training (MLET), trains embeddings using factorization of the embedding layer, with an inner dimension higher than the target embedding dimension. For inference efficiency, MLET converts the trained two-layer embedding into a single-layer one thus keeping inference-time model size unchanged. Empirical superiority of MLET is puzzling as its search space is not larger than that of the single-layer embedding. The strong dependence of MLET on the inner dimension is even more surprising. We develop a theory that explains both of these behaviors by showing that MLET creates an adaptive update mechanism modulated by the singular vectors of embeddings. When tested on multiple state-of-the-art recommendation models for click-through rate (CTR) prediction tasks, MLET consistently produces better models, especially for rare items. At constant model quality, MLET allows embedding dimension, and model size, reduction by up to 16x, and 5.8x on average, across the models.
Learning to Collide: Recommendation System Model Compression with Learned Hash Functions
Mar 28, 2022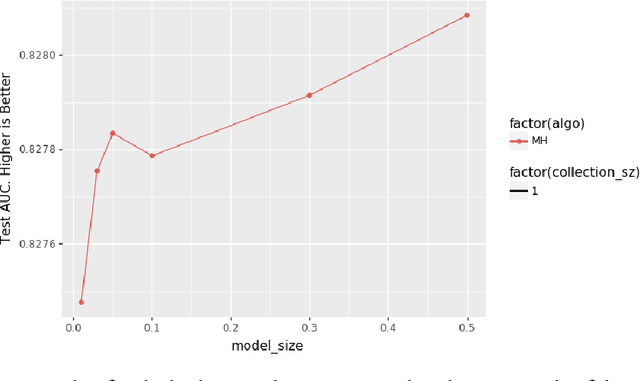

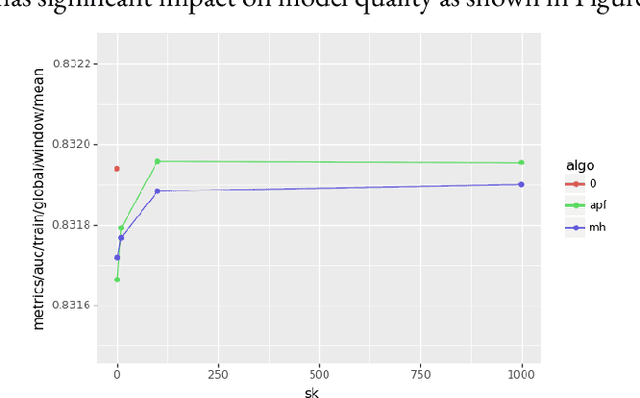
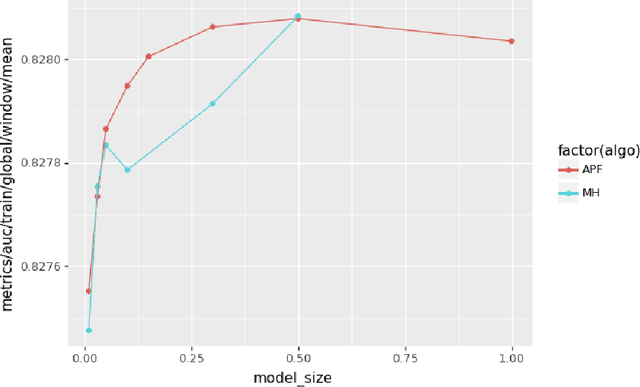
A key characteristic of deep recommendation models is the immense memory requirements of their embedding tables. These embedding tables can often reach hundreds of gigabytes which increases hardware requirements and training cost. A common technique to reduce model size is to hash all of the categorical variable identifiers (ids) into a smaller space. This hashing reduces the number of unique representations that must be stored in the embedding table; thus decreasing its size. However, this approach introduces collisions between semantically dissimilar ids that degrade model quality. We introduce an alternative approach, Learned Hash Functions, which instead learns a new mapping function that encourages collisions between semantically similar ids. We derive this learned mapping from historical data and embedding access patterns. We experiment with this technique on a production model and find that a mapping informed by the combination of access frequency and a learned low dimension embedding is the most effective. We demonstrate a small improvement relative to the hashing trick and other collision related compression techniques. This is ongoing work that explores the impact of categorical id collisions on recommendation model quality and how those collisions may be controlled to improve model performance.
Training with Multi-Layer Embeddings for Model Reduction
Jun 10, 2020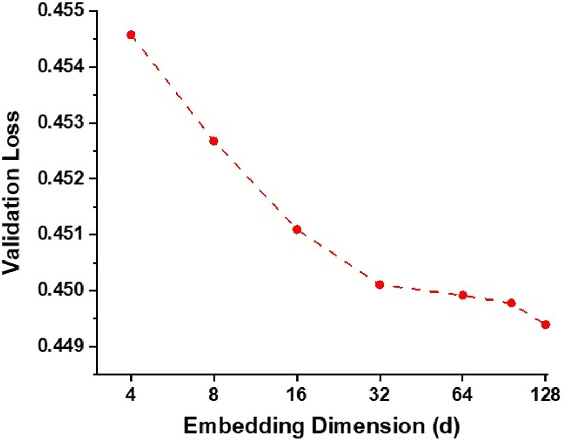

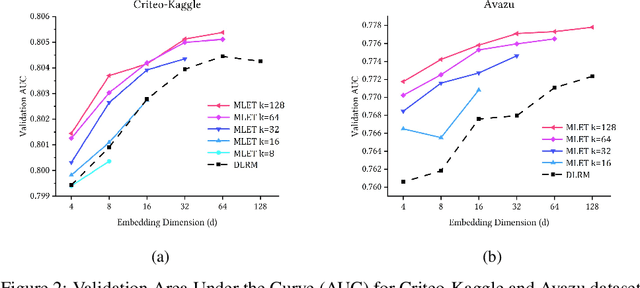
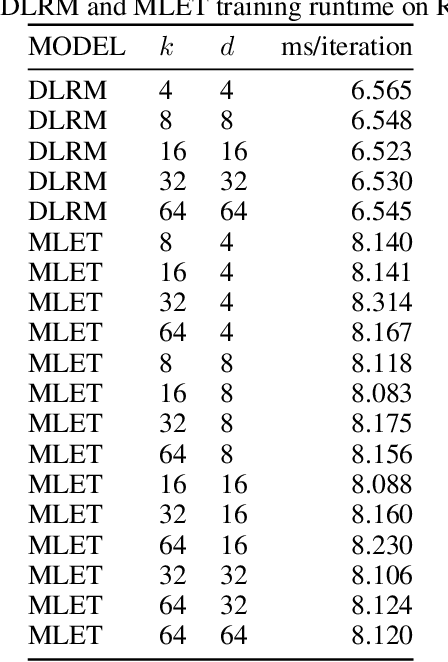
Modern recommendation systems rely on real-valued embeddings of categorical features. Increasing the dimension of embedding vectors improves model accuracy but comes at a high cost to model size. We introduce a multi-layer embedding training (MLET) architecture that trains embeddings via a sequence of linear layers to derive superior embedding accuracy vs. model size trade-off. Our approach is fundamentally based on the ability of factorized linear layers to produce superior embeddings to that of a single linear layer. We focus on the analysis and implementation of a two-layer scheme. Harnessing the recent results in dynamics of backpropagation in linear neural networks, we explain the ability to get superior multi-layer embeddings via their tendency to have lower effective rank. We show that substantial advantages are obtained in the regime where the width of the hidden layer is much larger than that of the final embedding (d). Crucially, at conclusion of training, we convert the two-layer solution into a single-layer one: as a result, the inference-time model size scales as d. We prototype the MLET scheme within Facebook's PyTorch-based open-source Deep Learning Recommendation Model. We show that it allows reducing d by 4-8X, with a corresponding improvement in memory footprint, at given model accuracy. The experiments are run on two publicly available click-through-rate prediction benchmarks (Criteo-Kaggle and Avazu). The runtime cost of MLET is 25%, on average.