 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstracting Sparse DNN Acceleration via Structured Sparse Tensor Decomposition
Mar 12, 2024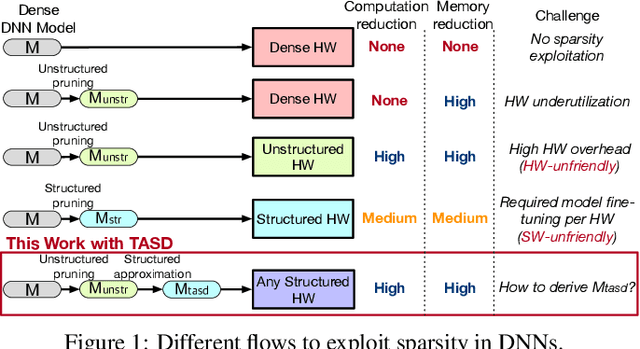
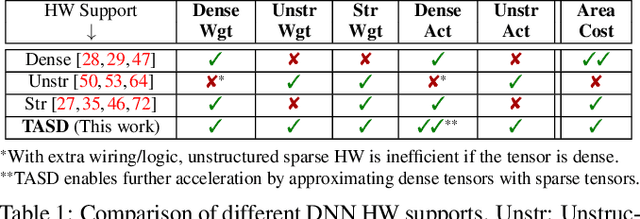
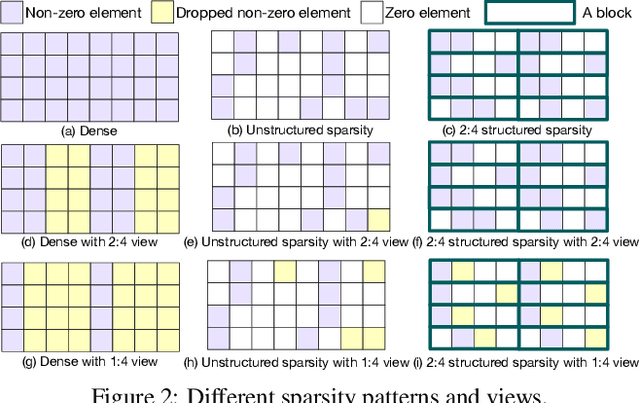
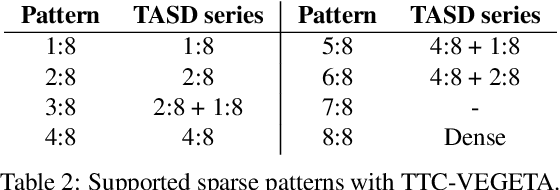
Exploiting sparsity in deep neural networks (DNNs) has been a promising area to meet the growing computation need of modern DNNs. However, in practice, sparse DNN acceleration still faces a key challenge. To minimize the overhead of sparse acceleration, hardware designers have proposed structured sparse hardware support recently, which provides limited flexibility and requires extra model fine-tuning. Moreover, any sparse model fine-tuned for certain structured sparse hardware cannot be accelerated by other structured hardware. To bridge the gap between sparse DNN models and hardware, this paper proposes tensor approximation via structured decomposition (TASD), which leverages the distributive property in linear algebra to turn any sparse tensor into a series of structured sparse tensors. Next, we develop a software framework, TASDER, to accelerate DNNs by searching layer-wise, high-quality structured decomposition for both weight and activation tensors so that they can be accelerated by any systems with structured sparse hardware support. Evaluation results show that, by exploiting prior structured sparse hardware baselines, our method can accelerate off-the-shelf dense and sparse DNNs without fine-tuning and improves energy-delay-product by up to 83% and 74% on average.