 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large Scale Analysis of Gender Biases in Text-to-Image Generative Models
Mar 30, 2025With the increasing use of image generation technology, understanding its social biases, including gender bias, is essential. This paper presents the first large-scale study on gender bias in text-to-image (T2I) models, focusing on everyday situations. While previous research has examined biases in occupations, we extend this analysis to gender associations in daily activities, objects, and contexts. We create a dataset of 3,217 gender-neutral prompts and generate 200 images per prompt from five leading T2I models. We automatically detect the perceived gender of people in the generated images and filter out images with no person or multiple people of different genders, leaving 2,293,295 images. To enable a broad analysis of gender bias in T2I models, we group prompts into semantically similar concepts and calculate the proportion of male- and female-gendered images for each prompt. Our analysis shows that T2I models reinforce traditional gender roles, reflect common gender stereotypes in household roles, and underrepresent women in financial related activities. Women are predominantly portrayed in care- and human-centered scenarios, and men in technical or physical labor scenarios.
Standard Language Ideology in AI-Generated Language
Jun 13, 2024
In this position paper, we explore standard language ideology in language generated by large language models (LLMs). First, we outline how standard language ideology is reflected and reinforced in LLMs. We then present a taxonomy of open problems regarding standard language ideology in AI-generated language with implications for minoritized language communities. We introduce the concept of standard AI-generated language ideology, the process by which AI-generated language regards Standard American English (SAE) as a linguistic default and reinforces a linguistic bias that SAE is the most "appropriate" language. Finally, we discuss tensions that remain, including reflecting on what desirable system behavior looks like, as well as advantages and drawbacks of generative AI tools imitating--or often not--different English language varieties. Throughout, we discuss standard language ideology as a manifestation of existing global power structures in and through AI-generated language before ending with questions to move towards alternative, more emancipatory digital futures.
Linguistic Bias in ChatGPT: Language Models Reinforce Dialect Discrimination
Jun 13, 2024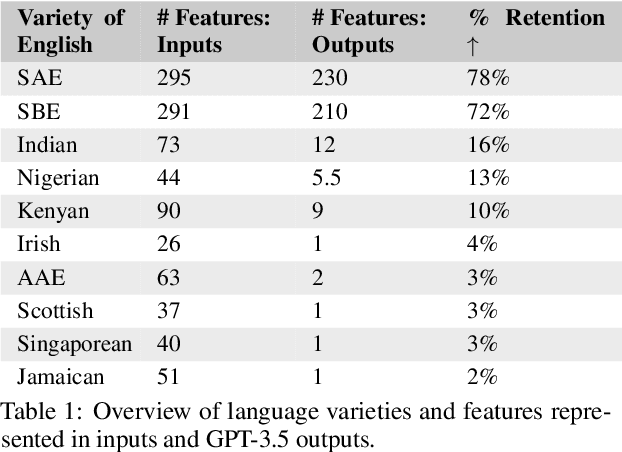
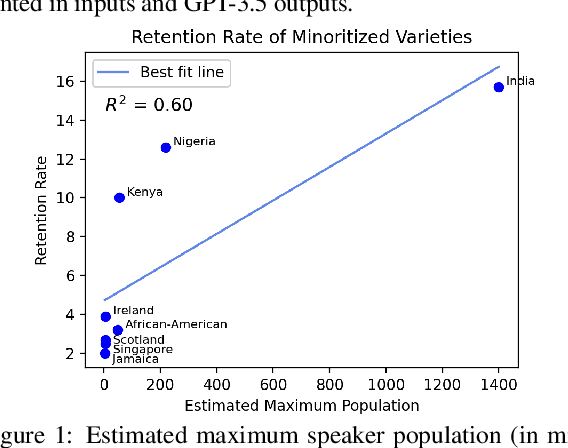
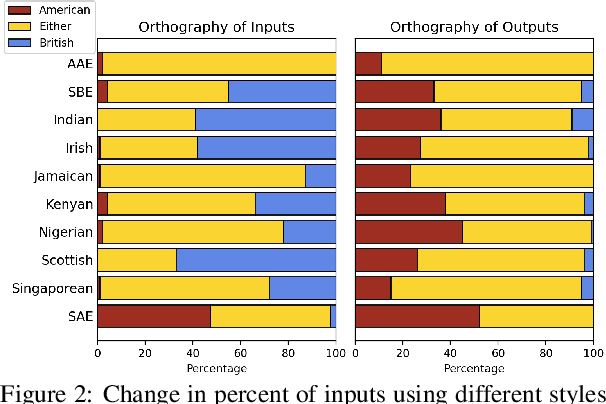
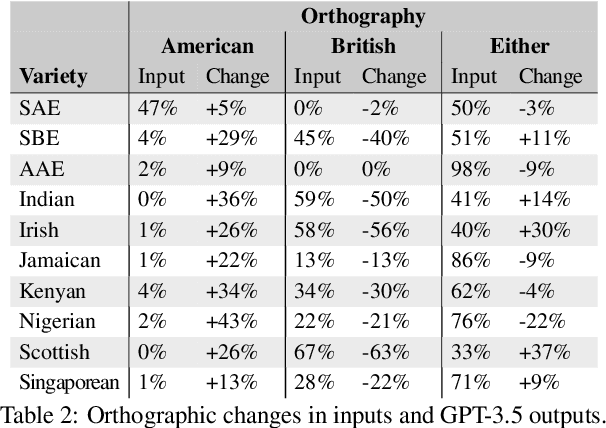
We present a large-scale study of linguistic bias exhibited by ChatGPT covering ten dialects of English (Standard American English, Standard British English, and eight widely spoken non-"standard" varieties from around the world). We prompted GPT-3.5 Turbo and GPT-4 with text by native speakers of each variety and analyzed the responses via detailed linguistic feature annotation and native speaker evaluation. We find that the models default to "standard" varieties of English; based on evaluation by native speakers, we also find that model responses to non-"standard" varieties consistently exhibit a range of issues: lack of comprehension (10% worse compared to "standard" varieties), stereotyping (16% worse), demeaning content (22% worse), and condescending responses (12% worse). We also find that if these models are asked to imitate the writing style of prompts in non-"standard" varieties, they produce text that exhibits lower comprehension of the input and is especially prone to stereotyping. GPT-4 improves on GPT-3.5 in terms of comprehension, warmth, and friendliness, but it also results in a marked increase in stereotyping (+17%). The results suggest that GPT-3.5 Turbo and GPT-4 exhibit linguistic discrimination in ways that can exacerbate harms for speakers of non-"standard" varieties.
Risks and Opportunities of Open-Source Generative AI
May 14, 2024



Applications of Generative AI (Gen AI) are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about the potential risks of the technology, and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open-source generative AI. Using a three-stage framework for Gen AI development (near, mid and long-term), we analyze the risks and opportunities of open-source generative AI models with similar capabilities to the ones currently available (near to mid-term) and with greater capabilities (long-term). We argue that, overall, the benefits of open-source Gen AI outweigh its risks. As such, we encourage the open sourcing of models, training and evaluation data, and provide a set of recommendations and best practices for managing risks associated with open-source generative AI.
Near to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024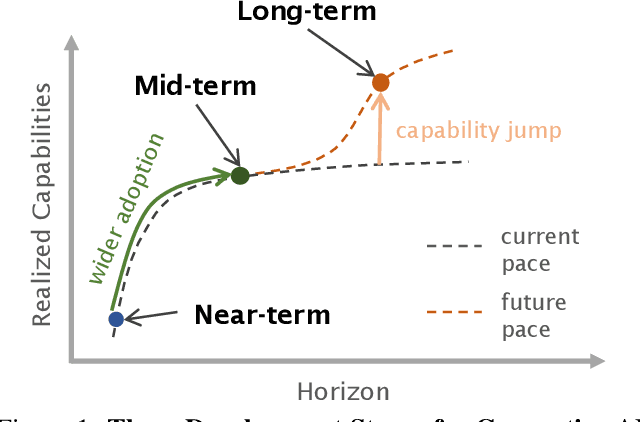
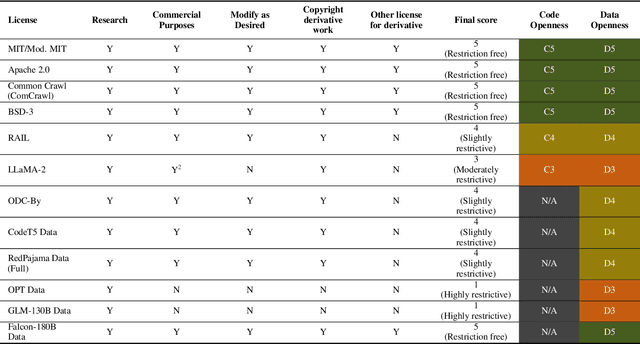
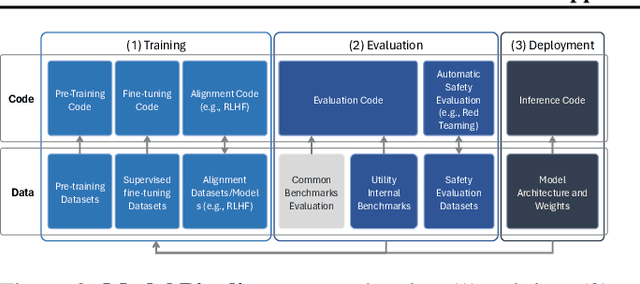
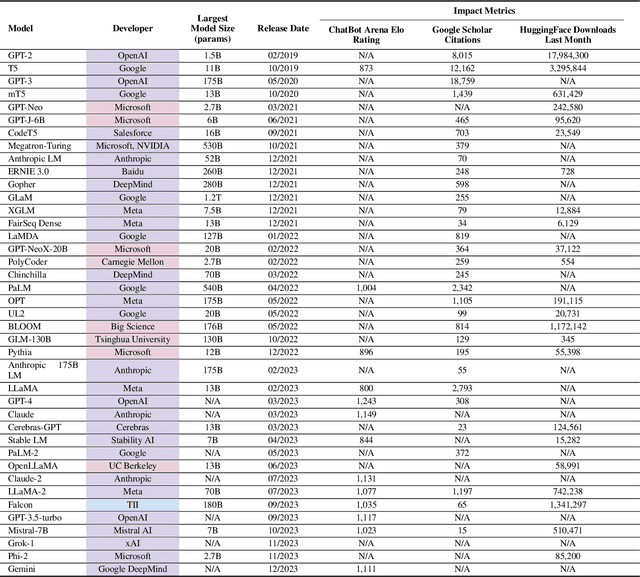
In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.