 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear to Mid-term Risks and Opportunities of Open Source Generative AI
Apr 25, 2024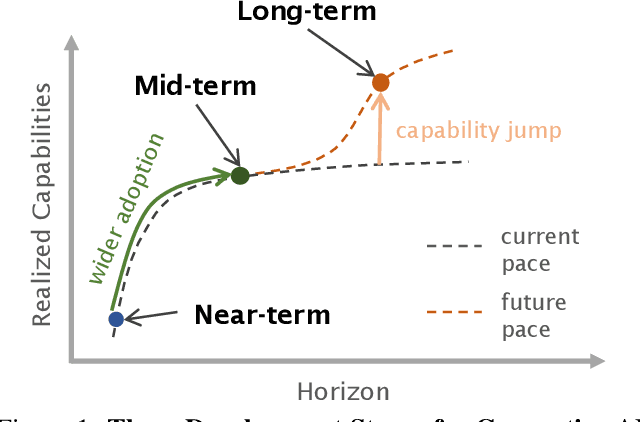
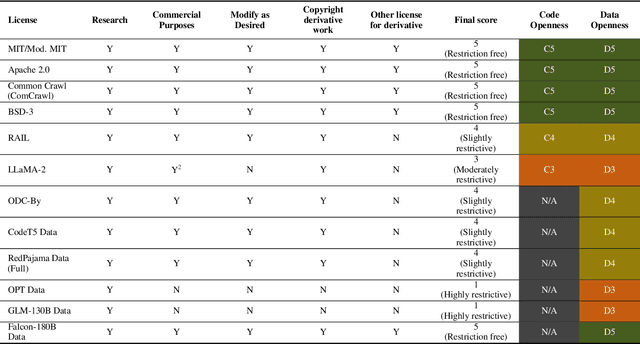
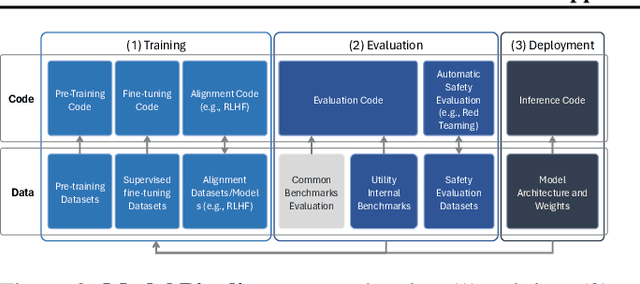
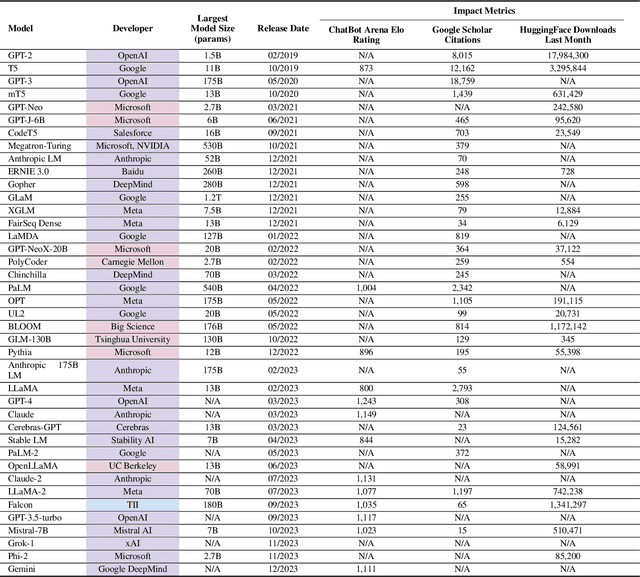
In the next few years, applications of Generative AI are expected to revolutionize a number of different areas, ranging from science & medicine to education. The potential for these seismic changes has triggered a lively debate about potential risks and resulted in calls for tighter regulation, in particular from some of the major tech companies who are leading in AI development. This regulation is likely to put at risk the budding field of open source Generative AI. We argue for the responsible open sourcing of generative AI models in the near and medium term. To set the stage, we first introduce an AI openness taxonomy system and apply it to 40 current large language models. We then outline differential benefits and risks of open versus closed source AI and present potential risk mitigation, ranging from best practices to calls for technical and scientific contributions. We hope that this report will add a much needed missing voice to the current public discourse on near to mid-term AI safety and other societal impact.
Label Delay in Continual Learning
Dec 01, 2023



Online continual learning, the process of training models on streaming data, has gained increasing attention in recent years. However, a critical aspect often overlooked is the label delay, where new data may not be labeled due to slow and costly annotation processes. We introduce a new continual learning framework with explicit modeling of the label delay between data and label streams over time steps. In each step, the framework reveals both unlabeled data from the current time step $t$ and labels delayed with $d$ steps, from the time step $t-d$. In our extensive experiments amounting to 1060 GPU days, we show that merely augmenting the computational resources is insufficient to tackle this challenge. Our findings underline a notable performance decline when solely relying on labeled data when the label delay becomes significant. More surprisingly, when using state-of-the-art SSL and TTA techniques to utilize the newer, unlabeled data, they fail to surpass the performance of a na\"ive method that simply trains on the delayed supervised stream. To this end, we introduce a simple, efficient baseline that rehearses from the labeled memory samples that are most similar to the new unlabeled samples. This method bridges the accuracy gap caused by label delay without significantly increasing computational complexity. We show experimentally that our method is the least affected by the label delay factor and in some cases successfully recovers the accuracy of the non-delayed counterpart. We conduct various ablations and sensitivity experiments, demonstrating the effectiveness of our approach.
Diversified Dynamic Routing for Vision Tasks
Sep 26, 2022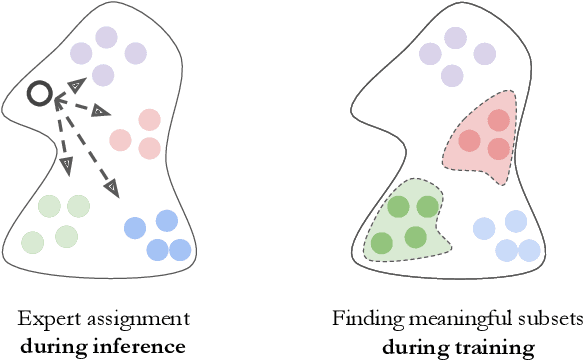
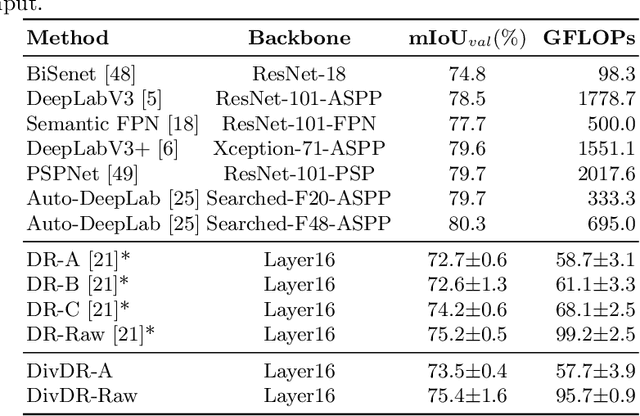
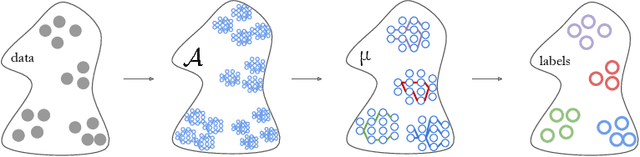
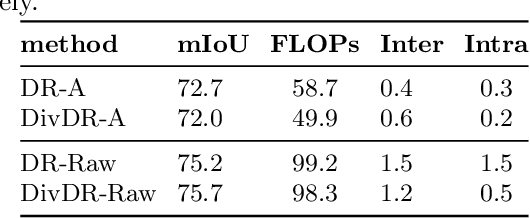
Deep learning models for vision tasks are trained on large datasets under the assumption that there exists a universal representation that can be used to make predictions for all samples. Whereas high complexity models are proven to be capable of learning such representations, a mixture of experts trained on specific subsets of the data can infer the labels more efficiently. However using mixture of experts poses two new problems, namely (i) assigning the correct expert at inference time when a new unseen sample is presented. (ii) Finding the optimal partitioning of the training data, such that the experts rely the least on common features. In Dynamic Routing (DR) a novel architecture is proposed where each layer is composed of a set of experts, however without addressing the two challenges we demonstrate that the model reverts to using the same subset of experts. In our method, Diversified Dynamic Routing (DivDR) the model is explicitly trained to solve the challenge of finding relevant partitioning of the data and assigning the correct experts in an unsupervised approach. We conduct several experiments on semantic segmentation on Cityscapes and object detection and instance segmentation on MS-COCO showing improved performance over several baselines.
Multilevel Knowledge Transfer for Cross-Domain Object Detection
Aug 03, 2021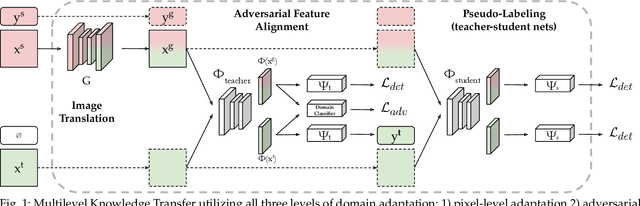
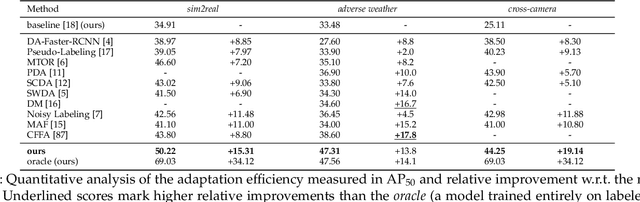
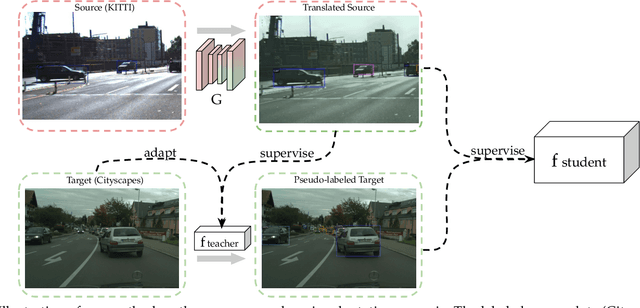
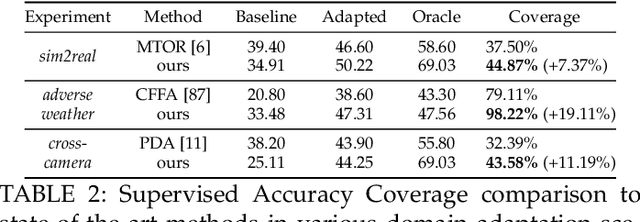
Domain shift is a well known problem where a model trained on a particular domain (source) does not perform well when exposed to samples from a different domain (target). Unsupervised methods that can adapt to domain shift are highly desirable as they allow effective utilization of the source data without requiring additional annotated training data from the target. Practically, obtaining sufficient amount of annotated data from the target domain can be both infeasible and extremely expensive. In this work, we address the domain shift problem for the object detection task. Our approach relies on gradually removing the domain shift between the source and the target domains. The key ingredients to our approach are -- (a) mapping the source to the target domain on pixel-level; (b) training a teacher network on the mapped source and the unannotated target domain using adversarial feature alignment; and (c) finally training a student network using the pseudo-labels obtained from the teacher. Experimentally, when tested on challenging scenarios involving domain shift, we consistently obtain significantly large performance gains over various recent state of the art approaches.
Domain Partitioning Network
Feb 21, 2019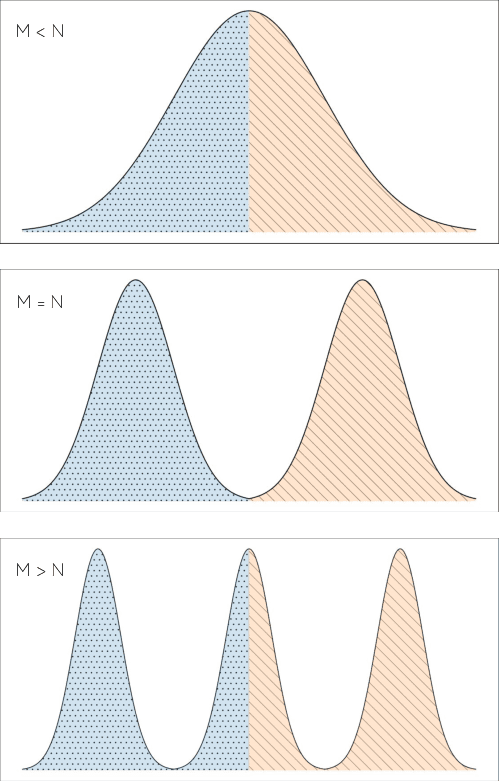
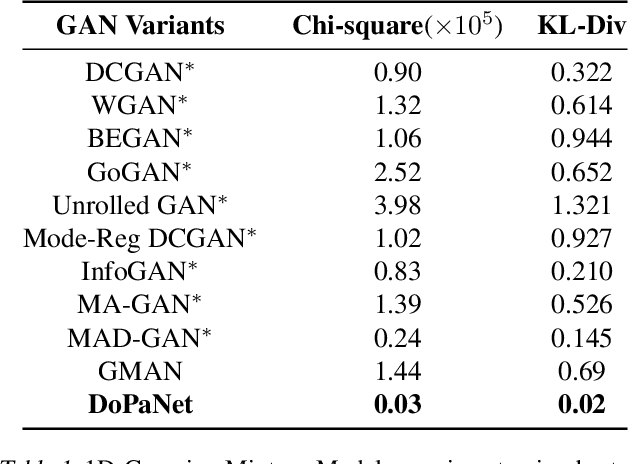
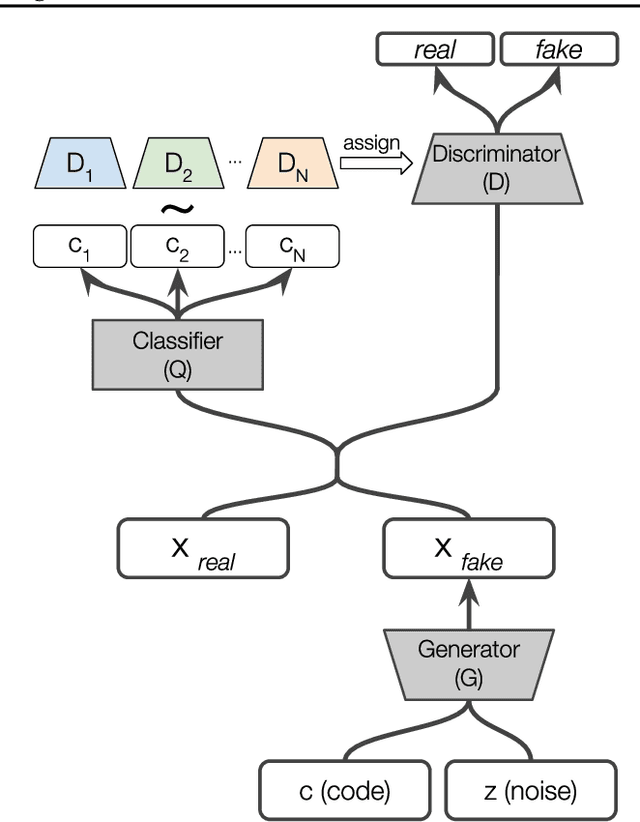

Standard adversarial training involves two agents, namely a generator and a discriminator, playing a mini-max game. However, even if the players converge to an equilibrium, the generator may only recover a part of the target data distribution, in a situation commonly referred to as mode collapse. In this work, we present the Domain Partitioning Network (DoPaNet), a new approach to deal with mode collapse in generative adversarial learning. We employ multiple discriminators, each encouraging the generator to cover a different part of the target distribution. To ensure these parts do not overlap and collapse into the same mode, we add a classifier as a third agent in the game. The classifier decides which discriminator the generator is trained against for each sample. Through experiments on toy examples and real images, we show the merits of DoPaNet in covering the real distribution and its superiority with respect to the competing methods. Besides, we also show that we can control the modes from which samples are generated using DoPaNet.