 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhase-Type Variational Autoencoders for Heavy-Tailed Data
Mar 02, 2026Heavy-tailed distributions are ubiquitous in real-world data, where rare but extreme events dominate risk and variability. However, standard Variational Autoencoders (VAEs) employ simple decoder distributions (e.g., Gaussian) that fail to capture heavy-tailed behavior, while existing heavy-tail-aware extensions remain restricted to predefined parametric families whose tail behavior is fixed a priori. We propose the Phase-Type Variational Autoencoder (PH-VAE), whose decoder distribution is a latent-conditioned Phase-Type (PH) distribution defined as the absorption time of a continuous-time Markov chain (CTMC). This formulation composes multiple exponential time scales, yielding a flexible and analytically tractable decoder that adapts its tail behavior directly from the observed data. Experiments on synthetic and real-world benchmarks demonstrate that PH-VAE accurately recovers diverse heavy-tailed distributions, significantly outperforming Gaussian, Student-t, and extreme-value-based VAE decoders in modeling tail behavior and extreme quantiles. In multivariate settings, PH-VAE captures realistic cross-dimensional tail dependence through its shared latent representation. To our knowledge, this is the first work to integrate Phase-Type distributions into deep generative modeling, bridging applied probability and representation learning.
Approximating Heavy-Tailed Distributions with a Mixture of Bernstein Phase-Type and Hyperexponential Models
Oct 30, 2025Heavy-tailed distributions, prevalent in a lot of real-world applications such as finance, telecommunications, queuing theory, and natural language processing, are challenging to model accurately owing to their slow tail decay. Bernstein phase-type (BPH) distributions, through their analytical tractability and good approximations in the non-tail region, can present a good solution, but they suffer from an inability to reproduce these heavy-tailed behaviors exactly, thus leading to inadequate performance in important tail areas. On the contrary, while highly adaptable to heavy-tailed distributions, hyperexponential (HE) models struggle in the body part of the distribution. Additionally, they are highly sensitive to initial parameter selection, significantly affecting their precision. To solve these issues, we propose a novel hybrid model of BPH and HE distributions, borrowing the most desirable features from each for enhanced approximation quality. Specifically, we leverage an optimization to set initial parameters for the HE component, significantly enhancing its robustness and reducing the possibility that the associated procedure results in an invalid HE model. Experimental validation demonstrates that the novel hybrid approach is more performant than individual application of BPH or HE models. More precisely, it can capture both the body and the tail of heavy-tailed distributions, with a considerable enhancement in matching parameters such as mean and coefficient of variation. Additional validation through experiments utilizing queuing theory proves the practical usefulness, accuracy, and precision of our hybrid approach.
Unintended Bias in 2D+ Image Segmentation and Its Effect on Attention Asymmetry
May 20, 2025Supervised pretrained models have become widely used in deep learning, especially for image segmentation tasks. However, when applied to specialized datasets such as biomedical imaging, pretrained weights often introduce unintended biases. These biases cause models to assign different levels of importance to different slices, leading to inconsistencies in feature utilization, which can be observed as asymmetries in saliency map distributions. This transfer of color distributions from natural images to non-natural datasets can compromise model performance and reduce the reliability of results. In this study, we investigate the effects of these biases and propose strategies to mitigate them. Through a series of experiments, we test both pretrained and randomly initialized models, comparing their performance and saliency map distributions. Our proposed methods, which aim to neutralize the bias introduced by pretrained color channel weights, demonstrate promising results, offering a practical approach to improving model explainability while maintaining the benefits of pretrained models. This publication presents our findings, providing insights into addressing pretrained weight biases across various deep learning tasks.
Probabilistic Process Discovery with Stochastic Process Trees
Apr 08, 2025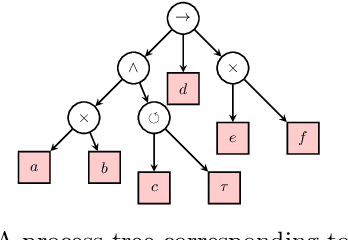
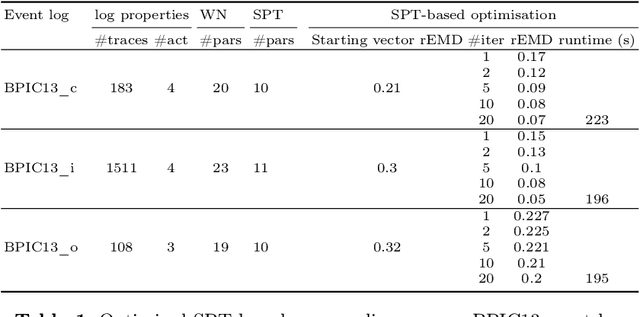
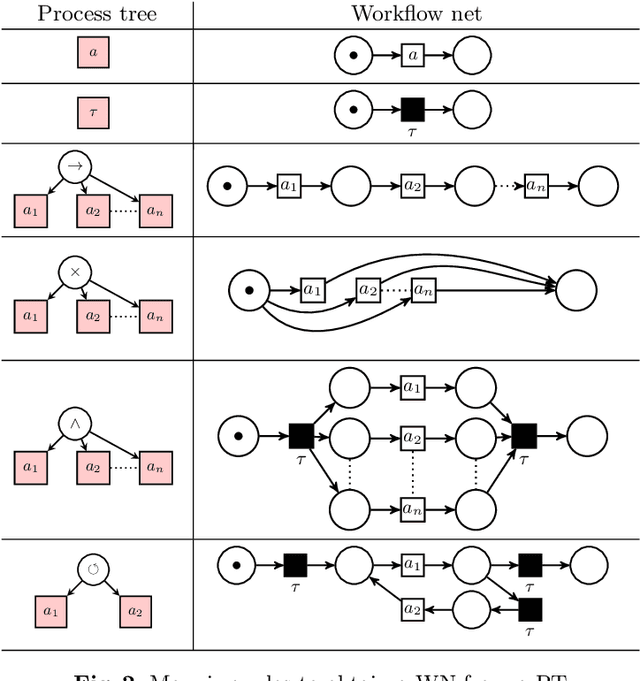
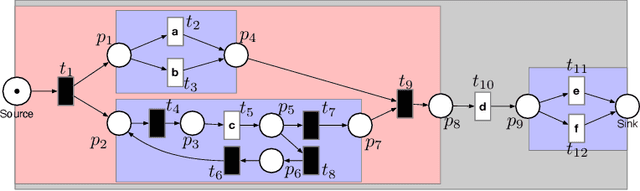
In order to obtain a stochastic model that accounts for the stochastic aspects of the dynamics of a business process, usually the following steps are taken. Given an event log, a process tree is obtained through a process discovery algorithm, i.e., a process tree that is aimed at reproducing, as accurately as possible, the language of the log. The process tree is then transformed into a Petri net that generates the same set of sequences as the process tree. In order to capture the frequency of the sequences in the event log, weights are assigned to the transitions of the Petri net, resulting in a stochastic Petri net with a stochastic language in which each sequence is associated with a probability. In this paper we show that this procedure has unfavorable properties. First, the weights assigned to the transitions of the Petri net have an unclear role in the resulting stochastic language. We will show that a weight can have multiple, ambiguous impact on the probability of the sequences generated by the Petri net. Second, a number of different Petri nets with different number of transitions can correspond to the same process tree. This means that the number of parameters (the number of weights) that determines the stochastic language is not well-defined. In order to avoid these ambiguities, in this paper, we propose to add stochasticity directly to process trees. The result is a new formalism, called stochastic process trees, in which the number of parameters and their role in the associated stochastic language is clear and well-defined.
Edge Training and Inference with Analog ReRAM Technology for Hand Gesture Recognition
Feb 25, 2025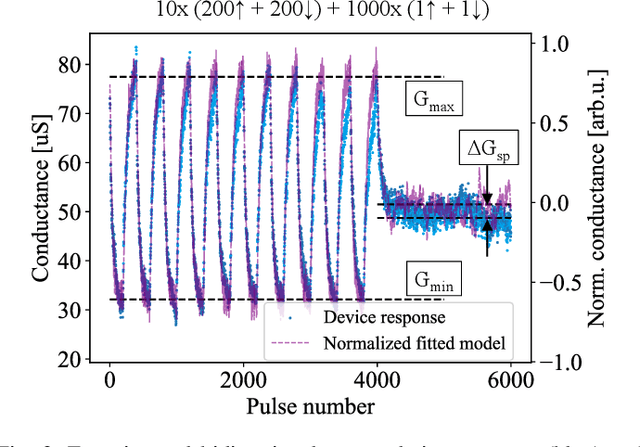
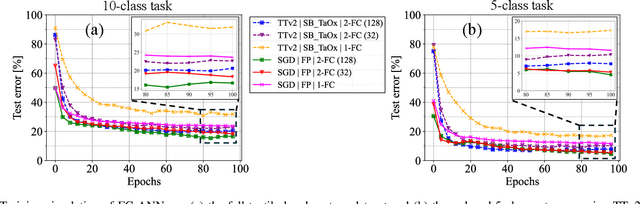
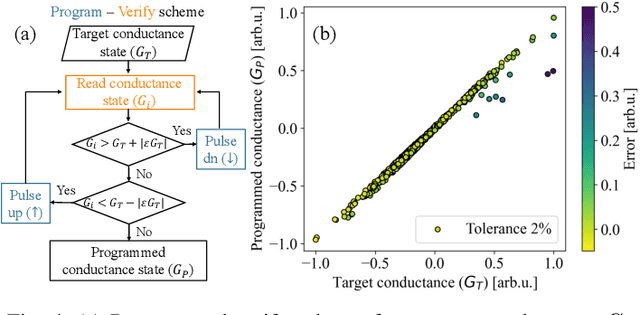
Tactile hand gesture recognition is a crucial task for user control in the automotive sector, where Human-Machine Interactions (HMI) demand low latency and high energy efficiency. This study addresses the challenges of power-constrained edge training and inference by utilizing analog Resistive Random Access Memory (ReRAM) technology in conjunction with a real tactile hand gesture dataset. By optimizing the input space through a feature engineering strategy, we avoid relying on large-scale crossbar arrays, making the system more suitable for edge deployment. Through realistic hardware-aware simulations that account for device non-idealities derived from experimental data, we demonstrate the functionalities of our analog ReRAM-based analog in-memory computing for on-chip training, utilizing the state-of-the-art Tiki-Taka algorithm. Furthermore, we validate the classification accuracy of approximately 91.4% for post-deployment inference of hand gestures. The results highlight the potential of analog ReRAM technology and crossbar architecture with fully parallelized matrix computations for real-time HMI systems at the Edge.
Post-Hoc MOTS: Exploring the Capabilities of Time-Symmetric Multi-Object Tracking
Dec 11, 2024



Temporal forward-tracking has been the dominant approach for multi-object segmentation and tracking (MOTS). However, a novel time-symmetric tracking methodology has recently been introduced for the detection, segmentation, and tracking of budding yeast cells in pre-recorded samples. Although this architecture has demonstrated a unique perspective on stable and consistent tracking, as well as missed instance re-interpolation, its evaluation has so far been largely confined to settings related to videomicroscopic environments. In this work, we aim to reveal the broader capabilities, advantages, and potential challenges of this architecture across various specifically designed scenarios, including a pedestrian tracking dataset. We also conduct an ablation study comparing the model against its restricted variants and the widely used Kalman filter. Furthermore, we present an attention analysis of the tracking architecture for both pretrained and non-pretrained models
Enhancing Cell Tracking with a Time-Symmetric Deep Learning Approach
Aug 04, 2023The accurate tracking of live cells using video microscopy recordings remains a challenging task for popular state-of-the-art image processing based object tracking methods. In recent years, several existing and new applications have attempted to integrate deep-learning based frameworks for this task, but most of them still heavily rely on consecutive frame based tracking embedded in their architecture or other premises that hinder generalized learning. To address this issue, we aimed to develop a new deep-learning based tracking method that relies solely on the assumption that cells can be tracked based on their spatio-temporal neighborhood, without restricting it to consecutive frames. The proposed method has the additional benefit that the motion patterns of the cells can be learned completely by the predictor without any prior assumptions, and it has the potential to handle a large number of video frames with heavy artifacts. The efficacy of the proposed method is demonstrated through multiple biologically motivated validation strategies and compared against several state-of-the-art cell tracking methods.
Saliency Map Based Data Augmentation
May 29, 2022
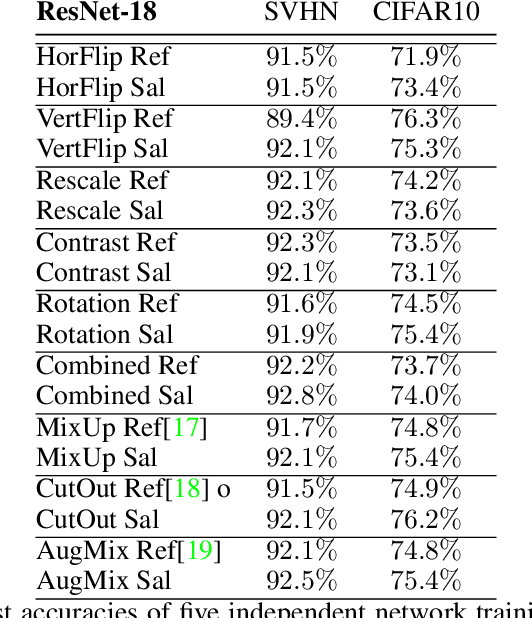

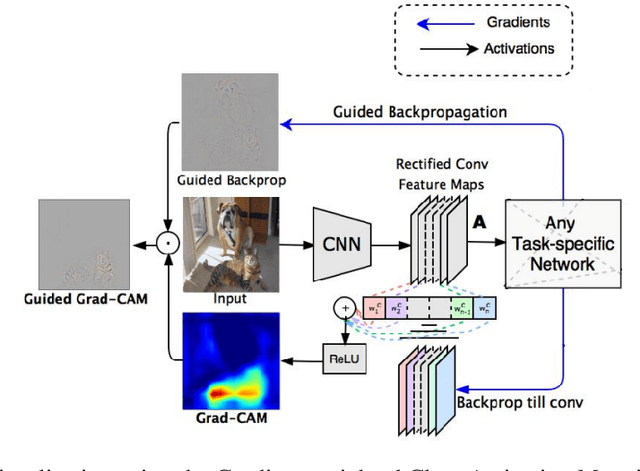
Data augmentation is a commonly applied technique with two seemingly related advantages. With this method one can increase the size of the training set generating new samples and also increase the invariance of the network against the applied transformations. Unfortunately all images contain both relevant and irrelevant features for classification therefore this invariance has to be class specific. In this paper we will present a new method which uses saliency maps to restrict the invariance of neural networks to certain regions, providing higher test accuracy in classification tasks.
Receptive Field Size Optimization with Continuous Time Pooling
Nov 06, 2020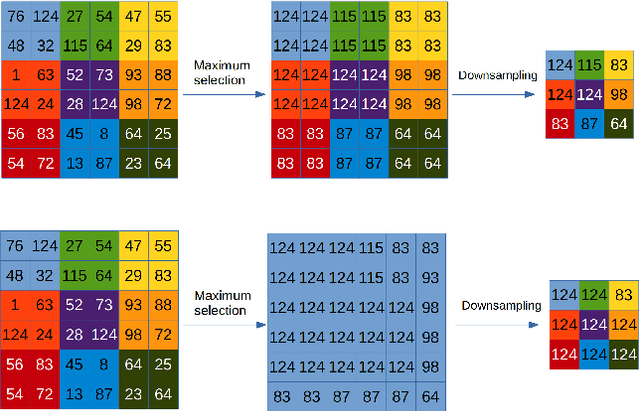
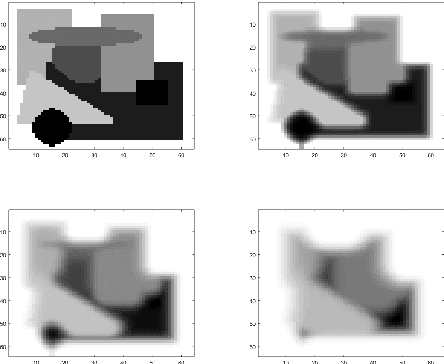
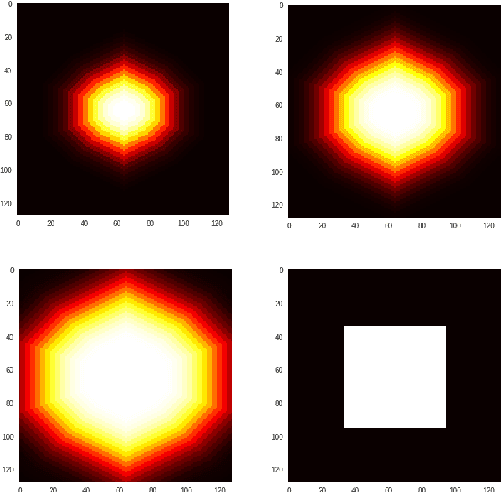
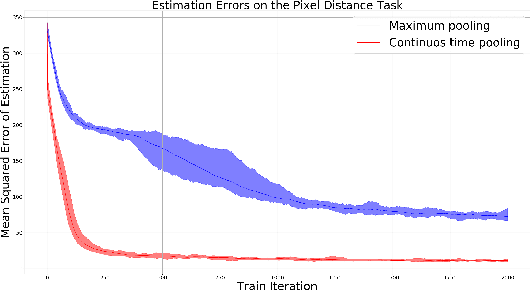
The pooling operation is a cornerstone element of convolutional neural networks. These elements generate receptive fields for neurons, in which local perturbations should have minimal effect on the output activations, increasing robustness and invariance of the network. In this paper we will present an altered version of the most commonly applied method, maximum pooling, where pooling in theory is substituted by a continuous time differential equation, which generates a location sensitive pooling operation, more similar to biological receptive fields. We will present how this continuous method can be approximated numerically using discrete operations which fit ideally on a GPU. In our approach the kernel size is substituted by diffusion strength which is a continuous valued parameter, this way it can be optimized by gradient descent algorithms. We will evaluate the effect of continuous pooling on accuracy and computational need using commonly applied network architectures and datasets.
Sorted Pooling in Convolutional Networks for One-shot Learning
Jul 20, 2020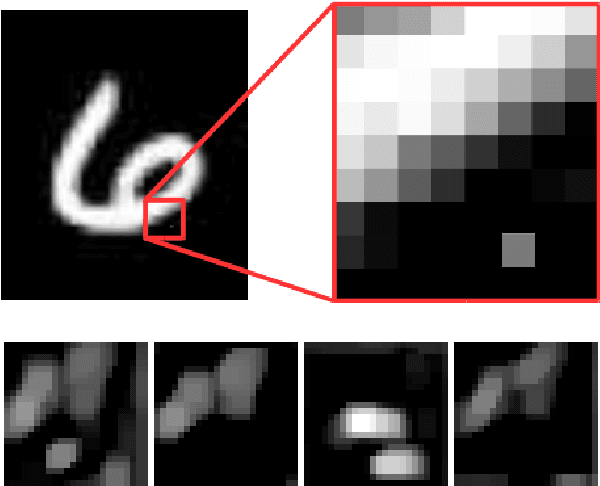
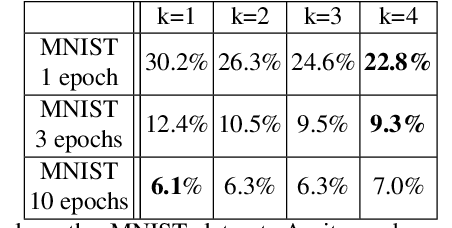
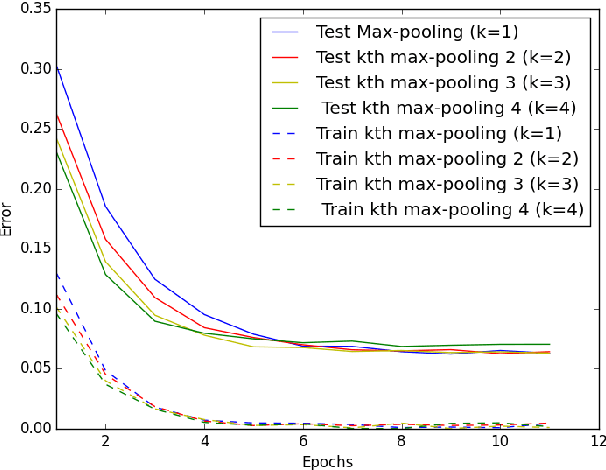
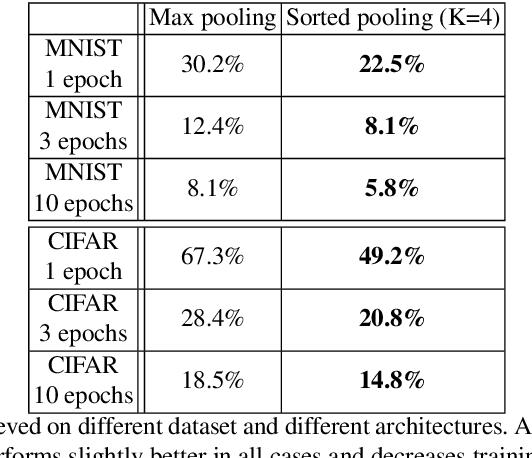
We present generalized versions of the commonly used maximum pooling operation: $k$th maximum and sorted pooling operations which selects the $k$th largest response in each pooling region, selecting locally consistent features of the input images. This method is able to increase the generalization power of a network and can be used to decrease training time and error rate of networks and it can significantly improve accuracy in case of training scenarios where the amount of available data is limited, like one-shot learning scenarios