 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Heavy-Tailed Distributions with a Mixture of Bernstein Phase-Type and Hyperexponential Models
Oct 30, 2025Heavy-tailed distributions, prevalent in a lot of real-world applications such as finance, telecommunications, queuing theory, and natural language processing, are challenging to model accurately owing to their slow tail decay. Bernstein phase-type (BPH) distributions, through their analytical tractability and good approximations in the non-tail region, can present a good solution, but they suffer from an inability to reproduce these heavy-tailed behaviors exactly, thus leading to inadequate performance in important tail areas. On the contrary, while highly adaptable to heavy-tailed distributions, hyperexponential (HE) models struggle in the body part of the distribution. Additionally, they are highly sensitive to initial parameter selection, significantly affecting their precision. To solve these issues, we propose a novel hybrid model of BPH and HE distributions, borrowing the most desirable features from each for enhanced approximation quality. Specifically, we leverage an optimization to set initial parameters for the HE component, significantly enhancing its robustness and reducing the possibility that the associated procedure results in an invalid HE model. Experimental validation demonstrates that the novel hybrid approach is more performant than individual application of BPH or HE models. More precisely, it can capture both the body and the tail of heavy-tailed distributions, with a considerable enhancement in matching parameters such as mean and coefficient of variation. Additional validation through experiments utilizing queuing theory proves the practical usefulness, accuracy, and precision of our hybrid approach.
Probabilistic Process Discovery with Stochastic Process Trees
Apr 08, 2025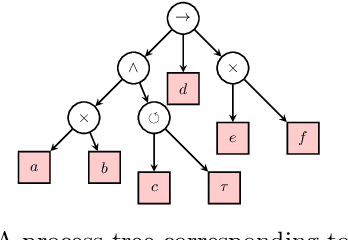
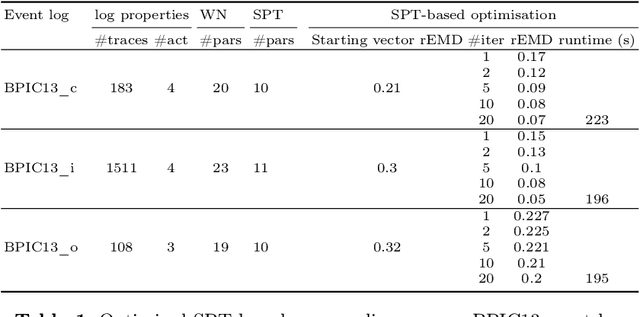
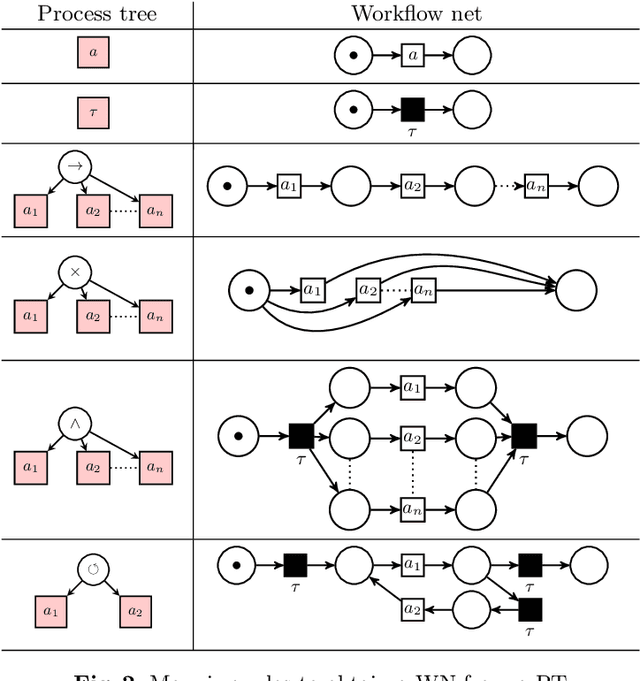
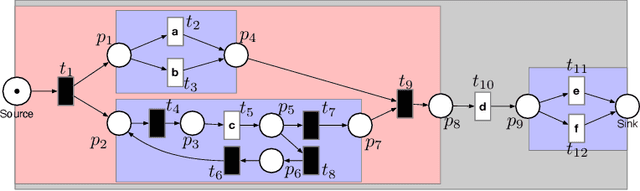
In order to obtain a stochastic model that accounts for the stochastic aspects of the dynamics of a business process, usually the following steps are taken. Given an event log, a process tree is obtained through a process discovery algorithm, i.e., a process tree that is aimed at reproducing, as accurately as possible, the language of the log. The process tree is then transformed into a Petri net that generates the same set of sequences as the process tree. In order to capture the frequency of the sequences in the event log, weights are assigned to the transitions of the Petri net, resulting in a stochastic Petri net with a stochastic language in which each sequence is associated with a probability. In this paper we show that this procedure has unfavorable properties. First, the weights assigned to the transitions of the Petri net have an unclear role in the resulting stochastic language. We will show that a weight can have multiple, ambiguous impact on the probability of the sequences generated by the Petri net. Second, a number of different Petri nets with different number of transitions can correspond to the same process tree. This means that the number of parameters (the number of weights) that determines the stochastic language is not well-defined. In order to avoid these ambiguities, in this paper, we propose to add stochasticity directly to process trees. The result is a new formalism, called stochastic process trees, in which the number of parameters and their role in the associated stochastic language is clear and well-defined.