 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnintended Bias in 2D+ Image Segmentation and Its Effect on Attention Asymmetry
May 20, 2025Supervised pretrained models have become widely used in deep learning, especially for image segmentation tasks. However, when applied to specialized datasets such as biomedical imaging, pretrained weights often introduce unintended biases. These biases cause models to assign different levels of importance to different slices, leading to inconsistencies in feature utilization, which can be observed as asymmetries in saliency map distributions. This transfer of color distributions from natural images to non-natural datasets can compromise model performance and reduce the reliability of results. In this study, we investigate the effects of these biases and propose strategies to mitigate them. Through a series of experiments, we test both pretrained and randomly initialized models, comparing their performance and saliency map distributions. Our proposed methods, which aim to neutralize the bias introduced by pretrained color channel weights, demonstrate promising results, offering a practical approach to improving model explainability while maintaining the benefits of pretrained models. This publication presents our findings, providing insights into addressing pretrained weight biases across various deep learning tasks.
Post-Hoc MOTS: Exploring the Capabilities of Time-Symmetric Multi-Object Tracking
Dec 11, 2024



Temporal forward-tracking has been the dominant approach for multi-object segmentation and tracking (MOTS). However, a novel time-symmetric tracking methodology has recently been introduced for the detection, segmentation, and tracking of budding yeast cells in pre-recorded samples. Although this architecture has demonstrated a unique perspective on stable and consistent tracking, as well as missed instance re-interpolation, its evaluation has so far been largely confined to settings related to videomicroscopic environments. In this work, we aim to reveal the broader capabilities, advantages, and potential challenges of this architecture across various specifically designed scenarios, including a pedestrian tracking dataset. We also conduct an ablation study comparing the model against its restricted variants and the widely used Kalman filter. Furthermore, we present an attention analysis of the tracking architecture for both pretrained and non-pretrained models
Enhancing Cell Tracking with a Time-Symmetric Deep Learning Approach
Aug 04, 2023The accurate tracking of live cells using video microscopy recordings remains a challenging task for popular state-of-the-art image processing based object tracking methods. In recent years, several existing and new applications have attempted to integrate deep-learning based frameworks for this task, but most of them still heavily rely on consecutive frame based tracking embedded in their architecture or other premises that hinder generalized learning. To address this issue, we aimed to develop a new deep-learning based tracking method that relies solely on the assumption that cells can be tracked based on their spatio-temporal neighborhood, without restricting it to consecutive frames. The proposed method has the additional benefit that the motion patterns of the cells can be learned completely by the predictor without any prior assumptions, and it has the potential to handle a large number of video frames with heavy artifacts. The efficacy of the proposed method is demonstrated through multiple biologically motivated validation strategies and compared against several state-of-the-art cell tracking methods.
Receptive Field Size Optimization with Continuous Time Pooling
Nov 06, 2020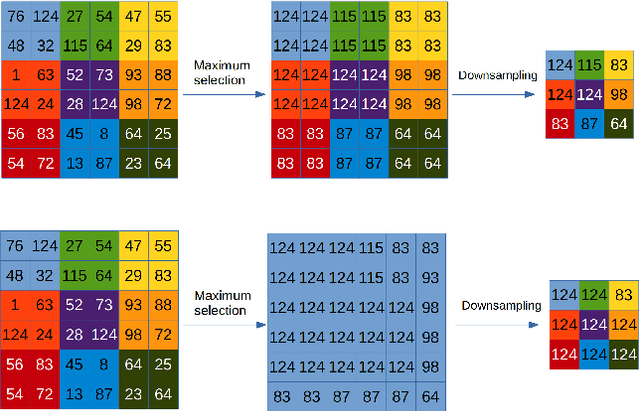
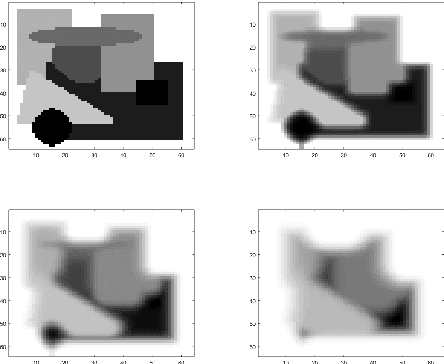
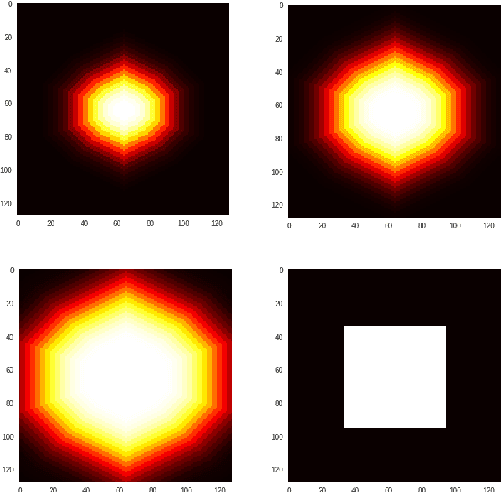
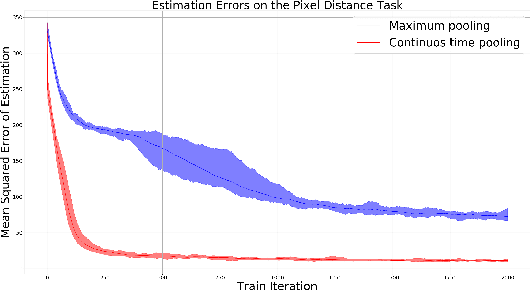
The pooling operation is a cornerstone element of convolutional neural networks. These elements generate receptive fields for neurons, in which local perturbations should have minimal effect on the output activations, increasing robustness and invariance of the network. In this paper we will present an altered version of the most commonly applied method, maximum pooling, where pooling in theory is substituted by a continuous time differential equation, which generates a location sensitive pooling operation, more similar to biological receptive fields. We will present how this continuous method can be approximated numerically using discrete operations which fit ideally on a GPU. In our approach the kernel size is substituted by diffusion strength which is a continuous valued parameter, this way it can be optimized by gradient descent algorithms. We will evaluate the effect of continuous pooling on accuracy and computational need using commonly applied network architectures and datasets.
On the notion of number in humans and machines
Jun 27, 2019
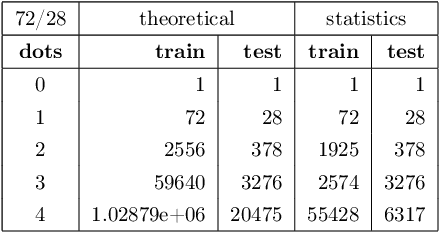

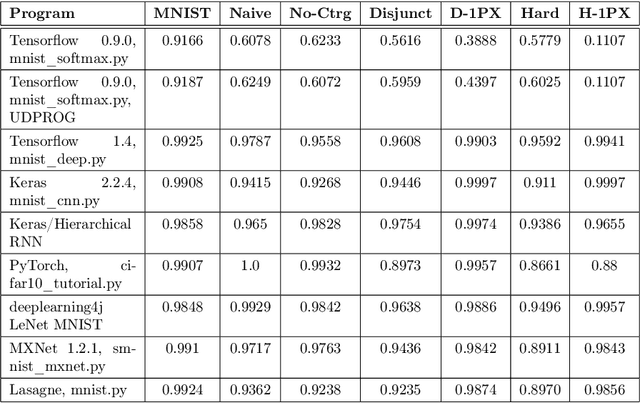
In this paper, we performed two types of software experiments to study the numerosity classification (subitizing) in humans and machines. Experiments focus on a particular kind of task is referred to as Semantic MNIST or simply SMNIST where the numerosity of objects placed in an image must be determined. The experiments called SMNIST for Humans are intended to measure the capacity of the Object File System in humans. In this type of experiment the measurement result is in well agreement with the value known from the cognitive psychology literature. The experiments called SMNIST for Machines serve similar purposes but they investigate existing, well known (but originally developed for other purpose) and under development deep learning computer programs. These measurement results can be interpreted similar to the results from SMNIST for Humans. The main thesis of this paper can be formulated as follows: in machines the image classification artificial neural networks can learn to distinguish numerosities with better accuracy when these numerosities are smaller than the capacity of OFS in humans. Finally, we outline a conceptual framework to investigate the notion of number in humans and machines.