 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPM: Evaluating Style Personalization in LLMs with Arbitrary Preference Mappings
May 20, 2026Typical LLM responses tend to follow a default style, even though users often have distinct preferences regarding tone, verbosity, and formality that they do not explicitly state in their prompts. Evaluating whether personalization methods can adapt to these implicit preferences is challenging, since users typically provide prompts rather than reference responses, style preferences are not factually verifiable, and reference-free LLM judges may conflate personalization with general response quality. To address these challenges, we introduce the Arbitrary Preference Mapping (APM) benchmark, which decouples user attributes (e.g. enthusiastic) from response principles (e.g. persuasive) via a hidden, randomized mapping $\mathbf{C}$ that maps user attributes to preferences about response traits. Because $\mathbf{C}$ carries no semantic content and is resampled across runs, models cannot exploit stereotypical associations and must infer preferences from conversation history. Using this unbiased evaluation methodology, we adapt retrieval-augmented, prompt-optimization, and routing personalization methods and evaluate them on Llama-3.1-8B and Qwen-3.5-27B. Our results show that routing is the most reliable approach, while RAG only improves with the stronger base LLM, and soft prompt optimization fails to improve significantly over a non-personalized baseline. Our extensive evaluation reveals that in this realistic setting, personalization remains challenging, but our adapted methods show promise.
Do LLMs Experience an Internal Polylogue? Investigating Reasoning through the Lens of Personas
May 09, 2026Recent work shows that large language models (LLMs) encode behavioural traits ("personas") as linear directions in activation space, often called "persona vectors". Prior work has used such directions as static handles for behavioural steering. Building on this, we treat them as dynamic signals instead: probes we can monitor and intervene on as reasoning unfolds. We use the term polylogue to denote the time series of alignments between persona vectors and hidden activations over the course of generation. Experiments across four open-weight models show that polylogue features predict correctness on MMLU-Pro competitively with low-dimensional activation baselines, while remaining interpretable through their associated persona directions. They also suggest concrete steering targets, namely which latent directions to modulate at different stages of a response. We instantiate this as a simple paragraph-conditioned intervention that improves accuracy on three of four models, pointing to stage-aware latent steering as a promising direction for reasoning-time control. Together, this positions the polylogue as an interpretable tool for reasoning-time monitoring and intervention.
Are Reasoning LLMs Robust to Interventions on Their Chain-of-Thought?
Feb 07, 2026Reasoning LLMs (RLLMs) generate step-by-step chains of thought (CoTs) before giving an answer, which improves performance on complex tasks and makes reasoning more transparent. But how robust are these reasoning traces to disruptions that occur within them? To address this question, we introduce a controlled evaluation framework that perturbs a model's own CoT at fixed timesteps. We design seven interventions (benign, neutral, and adversarial) and apply them to multiple open-weight RLLMs across Math, Science, and Logic tasks. Our results show that RLLMs are generally robust, reliably recovering from diverse perturbations, with robustness improving with model size and degrading when interventions occur early. However, robustness is not style-invariant: paraphrasing suppresses doubt-like expressions and reduces performance, while other interventions trigger doubt and support recovery. Recovery also carries a cost: neutral and adversarial noise can inflate CoT length by more than 200%, whereas paraphrasing shortens traces but harms accuracy. These findings provide new evidence on how RLLMs maintain reasoning integrity, identify doubt as a central recovery mechanism, and highlight trade-offs between robustness and efficiency that future training methods should address.
SUB: Benchmarking CBM Generalization via Synthetic Attribute Substitutions
Jul 31, 2025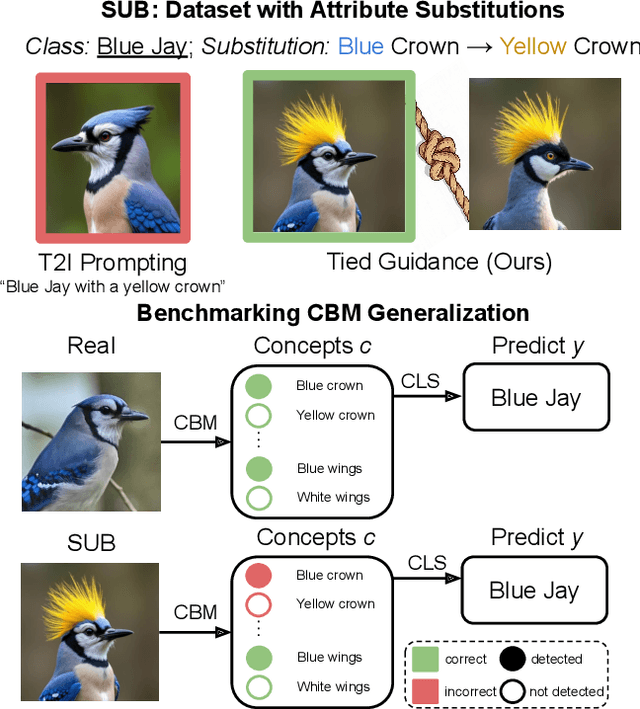
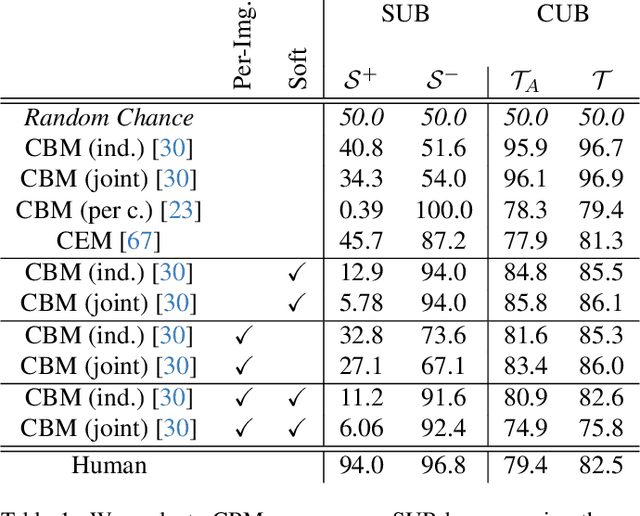
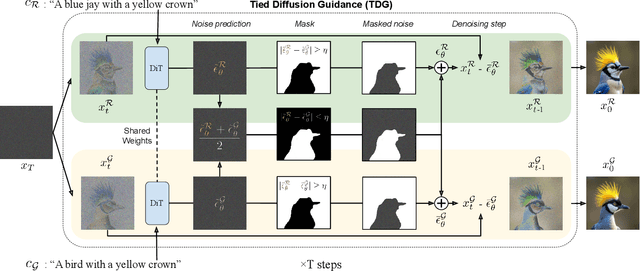

Concept Bottleneck Models (CBMs) and other concept-based interpretable models show great promise for making AI applications more transparent, which is essential in fields like medicine. Despite their success, we demonstrate that CBMs struggle to reliably identify the correct concepts under distribution shifts. To assess the robustness of CBMs to concept variations, we introduce SUB: a fine-grained image and concept benchmark containing 38,400 synthetic images based on the CUB dataset. To create SUB, we select a CUB subset of 33 bird classes and 45 concepts to generate images which substitute a specific concept, such as wing color or belly pattern. We introduce a novel Tied Diffusion Guidance (TDG) method to precisely control generated images, where noise sharing for two parallel denoising processes ensures that both the correct bird class and the correct attribute are generated. This novel benchmark enables rigorous evaluation of CBMs and similar interpretable models, contributing to the development of more robust methods. Our code is available at https://github.com/ExplainableML/sub and the dataset at http://huggingface.co/datasets/Jessica-bader/SUB.
Align-then-Unlearn: Embedding Alignment for LLM Unlearning
Jun 16, 2025As large language models (LLMs) are trained on massive datasets, they have raised significant privacy and ethical concerns due to their potential to inadvertently retain sensitive information. Unlearning seeks to selectively remove specific data from trained models, such as personal information or copyrighted content. Current approaches targeting specific output sequences at the token level often fail to achieve complete forgetting and remain susceptible to prompt rephrasing. We propose Align-then-Unlearn, a novel framework that performs unlearning in the semantic embedding space rather than directly on output tokens. Align-then-Unlearn first augments the LLM with an embedding prediction module trained to anticipate future context representations. Unlearning is then achieved by fine-tuning the model to minimize the similarity between these predicted embeddings and a target embedding that represents the concept to be removed. Initial results show that Align-then-Unlearn effectively removes targeted knowledge with minimal degradation in overall model utility. These findings suggest that embedding-based unlearning offers a promising and robust approach to removing conceptual knowledge. Our code is available at https://github.com/ExplainableML/align-then-unlearn.
A Large Scale Analysis of Gender Biases in Text-to-Image Generative Models
Mar 30, 2025With the increasing use of image generation technology, understanding its social biases, including gender bias, is essential. This paper presents the first large-scale study on gender bias in text-to-image (T2I) models, focusing on everyday situations. While previous research has examined biases in occupations, we extend this analysis to gender associations in daily activities, objects, and contexts. We create a dataset of 3,217 gender-neutral prompts and generate 200 images per prompt from five leading T2I models. We automatically detect the perceived gender of people in the generated images and filter out images with no person or multiple people of different genders, leaving 2,293,295 images. To enable a broad analysis of gender bias in T2I models, we group prompts into semantically similar concepts and calculate the proportion of male- and female-gendered images for each prompt. Our analysis shows that T2I models reinforce traditional gender roles, reflect common gender stereotypes in household roles, and underrepresent women in financial related activities. Women are predominantly portrayed in care- and human-centered scenarios, and men in technical or physical labor scenarios.
Revealing and Reducing Gender Biases in Vision and Language Assistants (VLAs)
Oct 25, 2024



Pre-trained large language models (LLMs) have been reliably integrated with visual input for multimodal tasks. The widespread adoption of instruction-tuned image-to-text vision-language assistants (VLAs) like LLaVA and InternVL necessitates evaluating gender biases. We study gender bias in 22 popular open-source VLAs with respect to personality traits, skills, and occupations. Our results show that VLAs replicate human biases likely present in the data, such as real-world occupational imbalances. Similarly, they tend to attribute more skills and positive personality traits to women than to men, and we see a consistent tendency to associate negative personality traits with men. To eliminate the gender bias in these models, we find that finetuning-based debiasing methods achieve the best tradeoff between debiasing and retaining performance on downstream tasks. We argue for pre-deploying gender bias assessment in VLAs and motivate further development of debiasing strategies to ensure equitable societal outcomes.
Addressing caveats of neural persistence with deep graph persistence
Jul 20, 2023
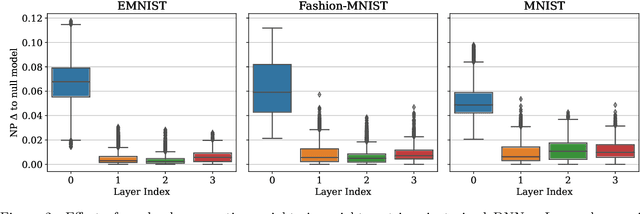
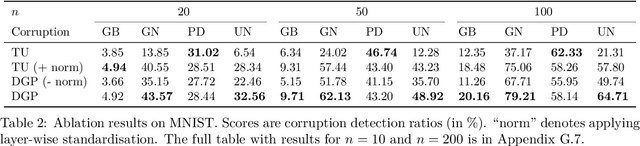
Neural Persistence is a prominent measure for quantifying neural network complexity, proposed in the emerging field of topological data analysis in deep learning. In this work, however, we find both theoretically and empirically that the variance of network weights and spatial concentration of large weights are the main factors that impact neural persistence. Whilst this captures useful information for linear classifiers, we find that no relevant spatial structure is present in later layers of deep neural networks, making neural persistence roughly equivalent to the variance of weights. Additionally, the proposed averaging procedure across layers for deep neural networks does not consider interaction between layers. Based on our analysis, we propose an extension of the filtration underlying neural persistence to the whole neural network instead of single layers, which is equivalent to calculating neural persistence on one particular matrix. This yields our deep graph persistence measure, which implicitly incorporates persistent paths through the network and alleviates variance-related issues through standardisation. Code is available at https://github.com/ExplainableML/Deep-Graph-Persistence .
Word Segmentation and Morphological Parsing for Sanskrit
Jan 30, 2022



We describe our participation in the Word Segmentation and Morphological Parsing (WSMP) for Sanskrit hackathon. We approach the word segmentation task as a sequence labelling task by predicting edit operations from which segmentations are derived. We approach the morphological analysis task by predicting morphological tags and rules that transform inflected words into their corresponding stems. Also, we propose an end-to-end trainable pipeline model for joint segmentation and morphological analysis. Our model performed best in the joint segmentation and analysis subtask (80.018 F1 score) and performed second best in the individual subtasks (segmentation: 96.189 F1 score / analysis: 69.180 F1 score). Finally, we analyse errors made by our models and suggest future work and possible improvements regarding data and evaluation.