 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Machine Learning Safety: A Survey and Primer
Jun 09, 2021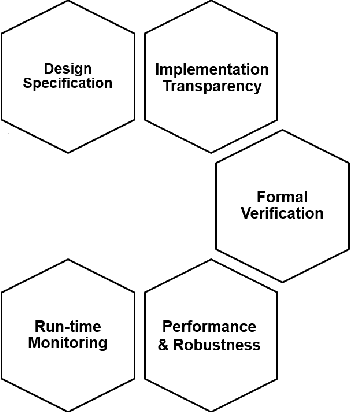
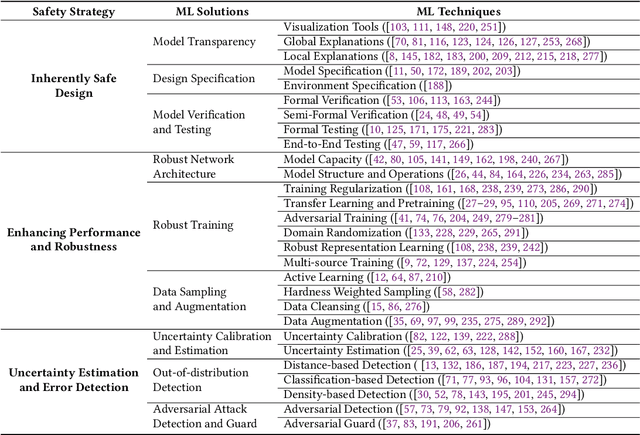

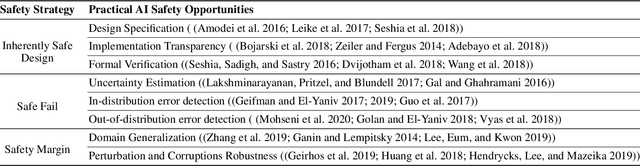
The open-world deployment of Machine Learning (ML) algorithms in safety-critical applications such as autonomous vehicles needs to address a variety of ML vulnerabilities such as interpretability, verifiability, and performance limitations. Research explores different approaches to improve ML dependability by proposing new models and training techniques to reduce generalization error, achieve domain adaptation, and detect outlier examples and adversarial attacks. In this paper, we review and organize practical ML techniques that can improve the safety and dependability of ML algorithms and therefore ML-based software. Our organization maps state-of-the-art ML techniques to safety strategies in order to enhance the dependability of the ML algorithm from different aspects, and discuss research gaps as well as promising solutions.
Multi-task Transformation Learning for Robust Out-of-Distribution Detection
Jun 07, 2021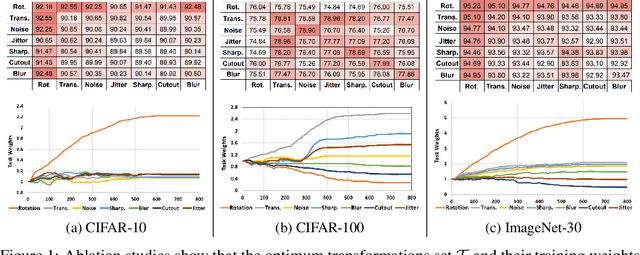
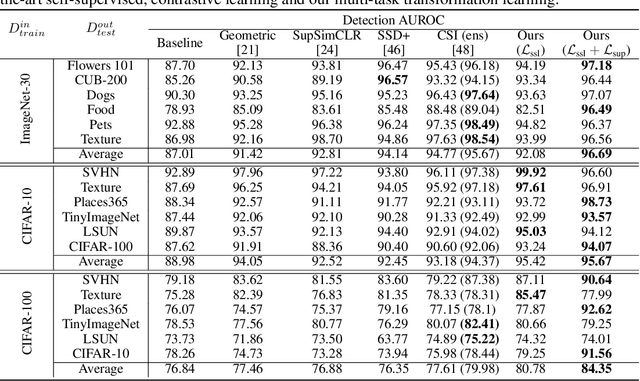
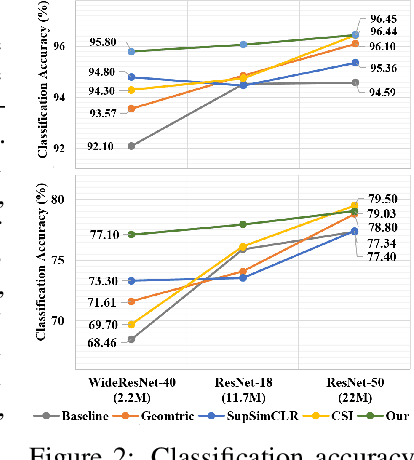
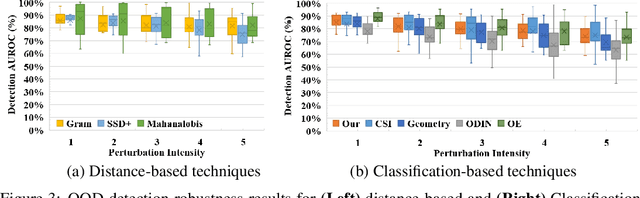
Detecting out-of-distribution (OOD) samples plays a key role in open-world and safety-critical applications such as autonomous systems and healthcare. Self-supervised representation learning techniques (e.g., contrastive learning and pretext learning) are well suited for learning representation that can identify OOD samples. In this paper, we propose a simple framework that leverages multi-task transformation learning for training effective representation for OOD detection which outperforms state-of-the-art OOD detection performance and robustness on several image datasets. We empirically observe that the OOD performance depends on the choice of data transformations which itself depends on the in-domain training set. To address this problem, we propose a simple mechanism for selecting the transformations automatically and modulate their effect on representation learning without requiring any OOD training samples. We characterize the criteria for a desirable OOD detector for real-world applications and demonstrate the efficacy of our proposed technique against a diverse range of the state-of-the-art OOD detection techniques.
Machine Learning Explanations to Prevent Overtrust in Fake News Detection
Jul 27, 2020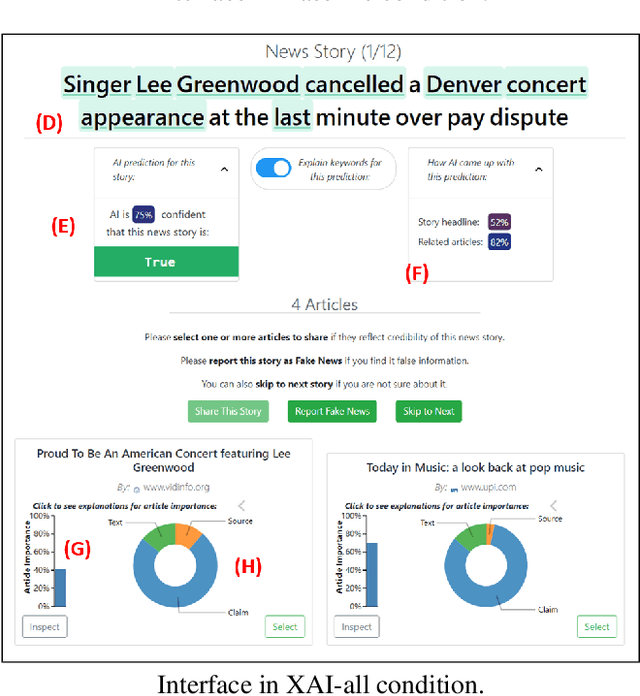

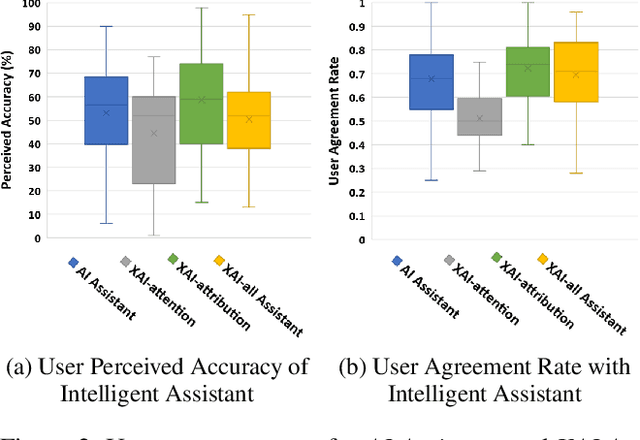
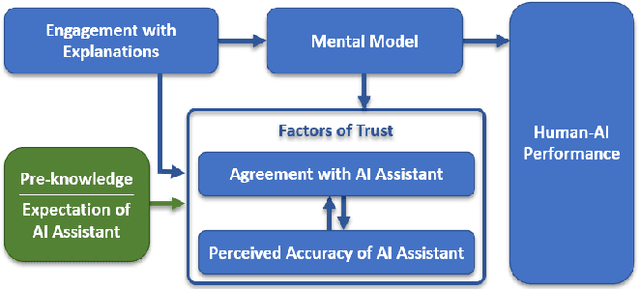
Combating fake news and misinformation propagation is a challenging task in the post-truth era. News feed and search algorithms could potentially lead to unintentional large-scale propagation of false and fabricated information with users being exposed to algorithmically selected false content. Our research investigates the effects of an Explainable AI assistant embedded in news review platforms for combating the propagation of fake news. We design a news reviewing and sharing interface, create a dataset of news stories, and train four interpretable fake news detection algorithms to study the effects of algorithmic transparency on end-users. We present evaluation results and analysis from multiple controlled crowdsourced studies. For a deeper understanding of Explainable AI systems, we discuss interactions between user engagement, mental model, trust, and performance measures in the process of explaining. The study results indicate that explanations helped participants to build appropriate mental models of the intelligent assistants in different conditions and adjust their trust accordingly for model limitations.
Practical Solutions for Machine Learning Safety in Autonomous Vehicles
Dec 20, 2019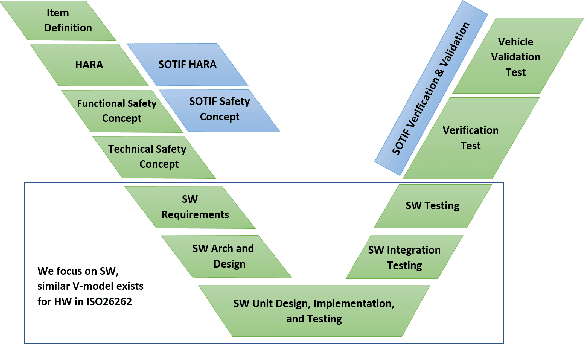
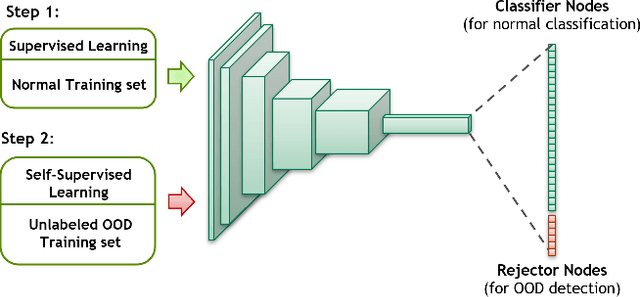
Autonomous vehicles rely on machine learning to solve challenging tasks in perception and motion planning. However, automotive software safety standards have not fully evolved to address the challenges of machine learning safety such as interpretability, verification, and performance limitations. In this paper, we review and organize practical machine learning safety techniques that can complement engineering safety for machine learning based software in autonomous vehicles. Our organization maps safety strategies to state-of-the-art machine learning techniques in order to enhance dependability and safety of machine learning algorithms. We also discuss security limitations and user experience aspects of machine learning components in autonomous vehicles.
XFake: Explainable Fake News Detector with Visualizations
Jul 08, 2019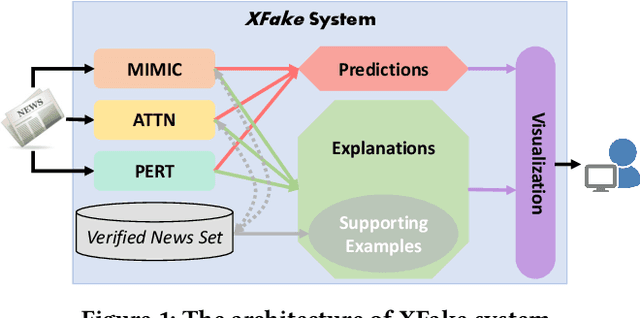
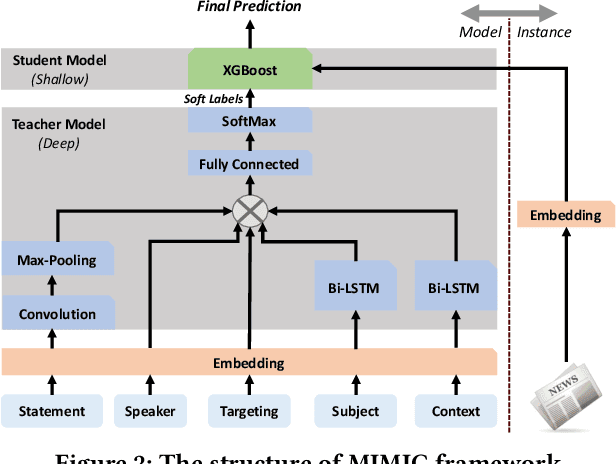
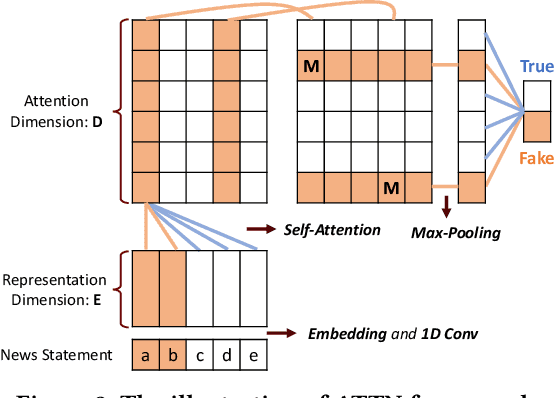
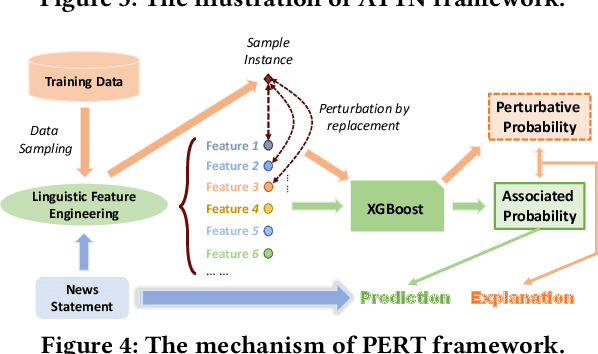
In this demo paper, we present the XFake system, an explainable fake news detector that assists end-users to identify news credibility. To effectively detect and interpret the fakeness of news items, we jointly consider both attributes (e.g., speaker) and statements. Specifically, MIMIC, ATTN and PERT frameworks are designed, where MIMIC is built for attribute analysis, ATTN is for statement semantic analysis and PERT is for statement linguistic analysis. Beyond the explanations extracted from the designed frameworks, relevant supporting examples as well as visualization are further provided to facilitate the interpretation. Our implemented system is demonstrated on a real-world dataset crawled from PolitiFact, where thousands of verified political news have been collected.
Predicting Model Failure using Saliency Maps in Autonomous Driving Systems
May 19, 2019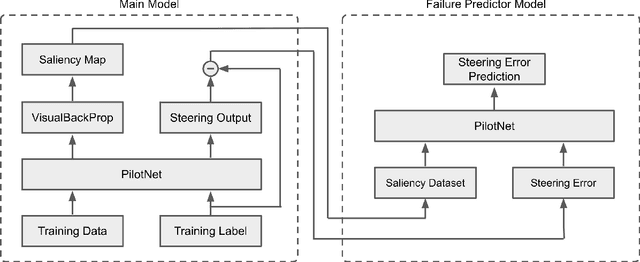
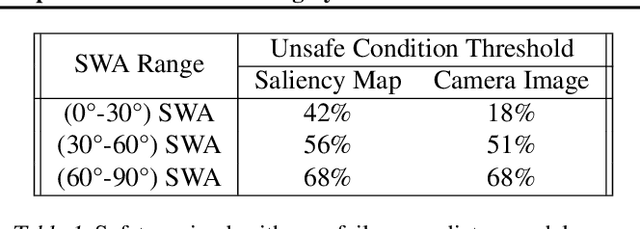
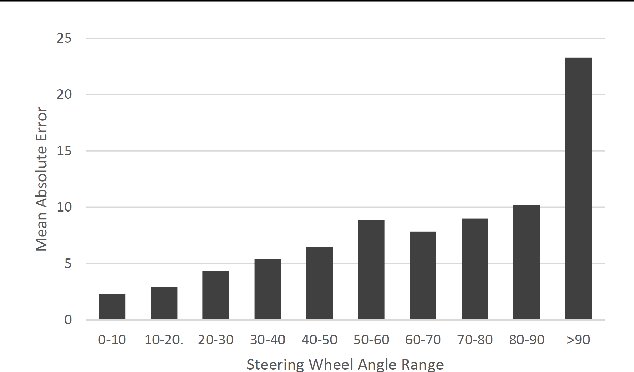

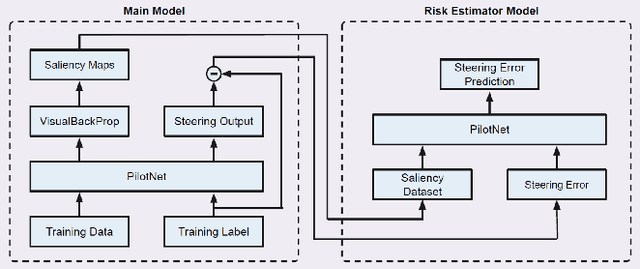
While machine learning systems show high success rate in many complex tasks, research shows they can also fail in very unexpected situations. Rise of machine learning products in safety-critical industries cause an increase in attention in evaluating model robustness and estimating failure probability in machine learning systems. In this work, we propose a design to train a student model -- a failure predictor -- to predict the main model's error for input instances based on their saliency map. We implement and review the preliminary results of our failure predictor model on an autonomous vehicle steering control system as an example of safety-critical applications.
A Human-Grounded Evaluation Benchmark for Local Explanations of Machine Learning
Jan 16, 2018
In order for people to be able to trust and take advantage of the results of advanced machine learning and artificial intelligence solutions for real decision making, people need to be able to understand the machine rationale for given output. Research in explain artificial intelligence (XAI) addresses the aim, but there is a need for evaluation of human relevance and understandability of explanations. Our work contributes a novel methodology for evaluating the quality or human interpretability of explanations for machine learning models. We present an evaluation benchmark for instance explanations from text and image classifiers. The explanation meta-data in this benchmark is generated from user annotations of image and text samples. We describe the benchmark and demonstrate its utility by a quantitative evaluation on explanations generated from a recent machine learning algorithm. This research demonstrates how human-grounded evaluation could be used as a measure to qualify local machine-learning explanations.